
最近、UnityのAR Foundation経由でiOSのARKit 3遊びをしていますが、

昨年、書店で「ARの教科書」を立ち読みして、思いの外しっかりした内容だったので購入したのでした。

https://book.mynavi.jp/ec/products/detail/id=91748
随分ストレートなタイトルなので、世に沢山あるようなプログラミングの入門書みたいなものかと思ったら、割とアカデミックな洋書の翻訳本なんですね。
原著は2016年に出版された”Augmented Reality: Principles and Practice“で、2人の著者はどちらもARを研究する大学教授だ。
書籍のサポートサイトもある↓
https://sites.google.com/view/ar-textbook/
チュートリアル動画↓
xR Tech Tokyoで輪講会もあったね。
https://www.godis1st.net/2018/12/ar.html
本書の冒頭で書かれている通り、ARは複数の研究分野(主にCGとCV)が複合的に絡み合って発展したため、ARの文脈で理論と実装をバランス良く体系的にまとめた教科書的な書物が長らく存在しなかった。
実装面において、ARは既存の技術分野を横断した開発知識が必要だが、その一方でAR体験を設計するには人間の知覚についても理解が必要だ。
未来を見据えた理想的なビジョンを描くのも大事だが、優れたAR体験を実装するには、今現在の技術的制約と人間の知覚特性のバランスを取って体験を設計(モデル化)できなければならない。
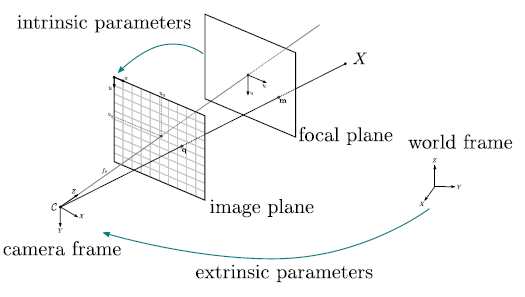
本書の原題にある”Principles and Practice“は日本語で言うと「原理と実践」ということで、まずARという概念の定義、感覚を提示する手段(ディスプレイ)について視覚に限らず音声、触覚、嗅覚・味覚なども紹介した後、最も盛んに実装されている視覚系のARを実現するための画像認識、コンピューターグラフィックスの技術、アプリケーション設計について概観できる構成になっている。
ARのための画像認識
単眼カメラで撮影した2D画像から3Dの情報を得る理屈はこういう分野↓
思えば、ARという言葉が一般に浸透してだいぶ経つ。
ARToolKit全盛の時代はデフォルトのARマーカー「Hiro」をよく見かけた。ARマーカー独特の意匠がARというジャンルのシンボルマーク、アフォーダンスとして機能していた時代があった。
現在この手の矩形マーカーはARコンテンツ向けというより、カメラ画像からの堅牢な位置測位・トラッキングのための手段として定着した気がする。

ハリウッド映画のメイキングで、俳優の演技をキャプチャするためのスーツにマーカーがたくさん貼り付けられている。

一目でマーカーだと分かる矩形のARマーカーに対して、その後明示的なマーカーを使わずに自然特徴量だけで位置測位・トラッキングを行う手法も登場した。(これがマーカーレスと呼ばれることもある)
スマートフォンの時代になり、ここ最近はカメラ位置のトラッキングに撮影画像だけでなくスマホのモーションセンサーも併用するVIO(visual-inertial odometry)で実用面も一応一段落した感じ。(あくまでエンタメ用途のARでは)
追記:ARの歴史についてはこちらの記事が詳しい↓
Occlusion
今ARの実装でホットな技術課題はOcclusionのようだ。現実のオブジェクトよりも後ろにあるCGオブジェクトは遮蔽されるはず。この現実のオブジェクトとCGオブジェクト表示の前後関係の矛盾をどう解決するか。
アプローチとしては、単眼カメラ動画からDepth Mapを推定したり、もっと大雑把に前後フレームの視差から物体の境界書き割りを推定したり、あるいはSemantic Segmentationで特定の物体についての境界を推定したり。
ここでも機械学習ベースの手法が盛んに研究されている。
Siggraph Asia 2018では、同じセッションでFacebookとGoogleが別々のアプローチでARのOcclusion問題を解決する手法を発表していた。
Facebookの研究の方はソースコードも含めてネットで無料公開されている↓
https://homes.cs.washington.edu/~holynski/publications/occlusion/index.html
https://github.com/facebookresearch/AR-Depth
GoogleはAndroidのARCoreに実装してくれてる↓
https://developers.googleblog.com/2019/12/blending-realities-with-arcore-depth-api.html
Niantic
ポケモンGOの開発元で知られるNianticもOcclusion問題に取り組んでいる。
https://nianticlabs.com/ja/blog/nianticrealworldplatform/
Niantic LabsとしてDepth推定の論文を発表し、ソースコードも公開している↓
https://arxiv.org/abs/1806.01260
https://github.com/nianticlabs/monodepth2
PoepleOcclusion
オイラが最近遊んでいるiOSのARKit3では、人物領域をSegmentationすることで現実空間の人とCGオブジェクトの重なりを解決するもの。
オイラもこの記事を参考にPoepleOcclusionを試してみた↓

顔が判別できるほど大きく写っている人物に対してはちゃんとSegmentationがかかる。ARで問題となるのは特に手前の物体によるOcclusionなので、これで十分。要件の落としどころが上手い。
DR (Diminished Reality)
現実空間に架空のオブジェクトなどを配置するAR: Augmented Reality(拡張現実感)に対して、オイラが個人的に注目しているのは、現実空間からオブジェクトを消して見せるDR: Diminished Reality(隠消現実感、減損現実感)と呼ばれる概念。
ARが情報の足し算だとすると、DRは情報の引き算と言える。
その概念を初めて知ったのは2015年のSSIIだった↓

あれから数年経って、面白い実装例が増えてきた↓
Full details here 🙂 https://t.co/d37MM2Meeb
— Chris Harris (@otduet) May 7, 2019
http://harrischris.com/article/biophillic-vision-experiment-1
Deep Learningで特定の物体領域を検出する精度が上がったから、次の課題はその領域をどうやって加工するかだ。
ARKit 3のPeopleOcclusionはDRの実装にも利用できるね↓
Hide yourself – arkit testing w @openMolmol_MPS pic.twitter.com/8Xv2VdpD3h
— zach lieberman (@zachlieberman) June 22, 2019
https://wired.jp/2019/08/03/leapmotion-blog/
ARで新宿を更地にするアプリ作ってみた。
タップした建物を撤去。
東京タワー移設してみたり。#PLATEAU pic.twitter.com/ePEjJnetT1— 龍 lilea / Ryo Fujiwara (@lileaLab) May 26, 2021
Unity上だとこんな。
ステンシルバッファなシェーダーを利用。 pic.twitter.com/hiEjm2420O— 龍 lilea / Ryo Fujiwara (@lileaLab) May 26, 2021
新宿西口のVPS用マップ生成でけた。
ImmersalによるAR自動位置合わせ。
0.3秒くらいで位置が合う。西口をこれだけ歩き回っても位置が合うのは気持ちいい。#Immersal pic.twitter.com/GhYYwiDtV0
— 龍 lilea / Ryo Fujiwara (@lileaLab) May 31, 2021
https://nlab.itmedia.co.jp/nl/articles/2105/28/news131.html
追記:ところで、冒頭の書籍の続編っぽいのが出てるけど著者は別の人なのね↓(原題:Practical Augmented Reality: A Guide to the Technologies, Applications, and Human Factors for AR and VR)



コメント