機械学習分野では、世間的にも話題のLLM(Large Language Model)をはじめ、多様な大量のデータでニューラルネットワークを事前学習(Pre-training)した基盤モデル(Foundation Model)が様々な下流タスク(Downstream Tasks)で高い性能を発揮し、その汎用性を示している。

![]()
3Dコンピュータービジョンにおいても、3D Geometric Foundation Modelと総称される大規模基盤モデルの登場でパラダイムシフトが起こっている。
DUSt3R (Dense and Unconstrained Stereo 3D Reconstruction)
DUSt3R(ダスター)はCVPR2024で発表された論文 DUSt3R: Geometric 3D Vision Made Easyで提案された3Dコンピュータービジョンの基盤モデル。
“Geometric 3D Vision Made Easy“(幾何学的3Dビジョンを手軽に)というタイトル通り、幾何学的な制約を利用して段階的に3D情報を算出していく従来手法と違い、DUSt3Rは2D画像から直接密な3D情報(Pointmap)を推定できる。
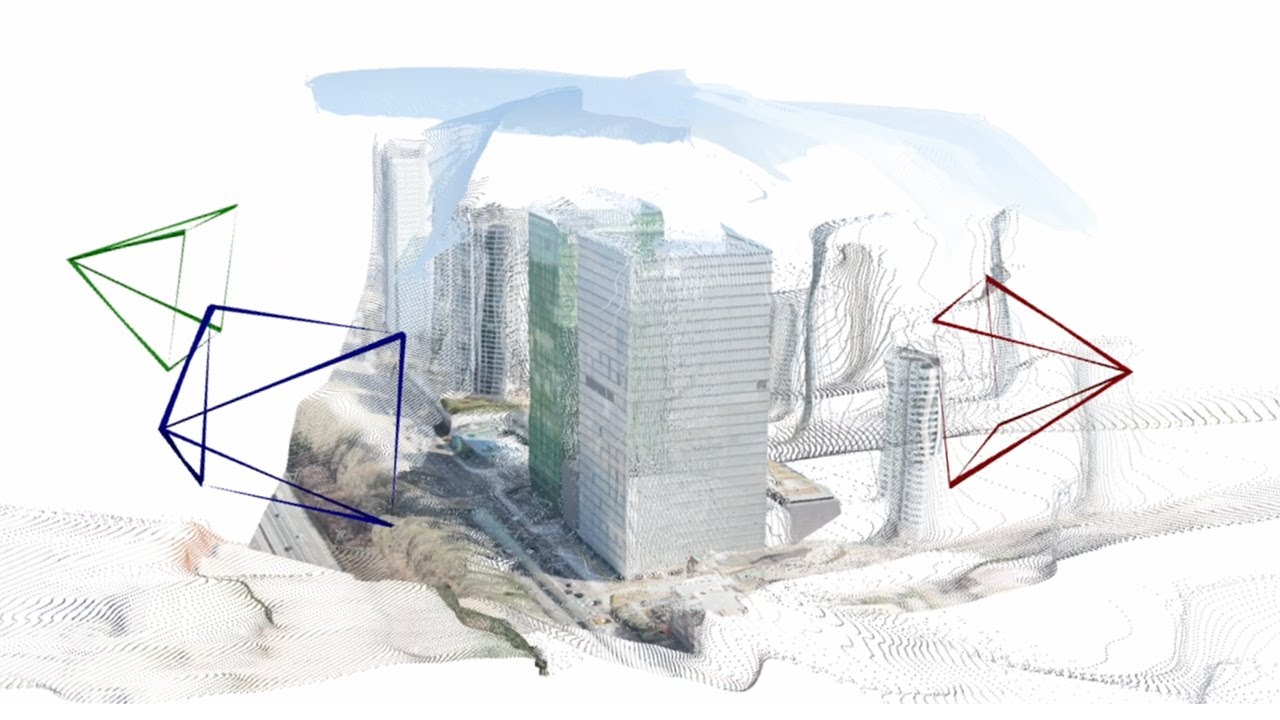
DUSt3Rは大規模な事前学習によって、画像以外の幾何情報不要で、しかも従来手法よりはるかに少なく離れた「疎な視点」の画像でも強力に3次元情報を推定できることを示した↓
疎な視点から3次元情報を復元するsparse multi-view scene reconstructionというタスクの手法と位置付けることもできる。
DUSt3Rの根幹
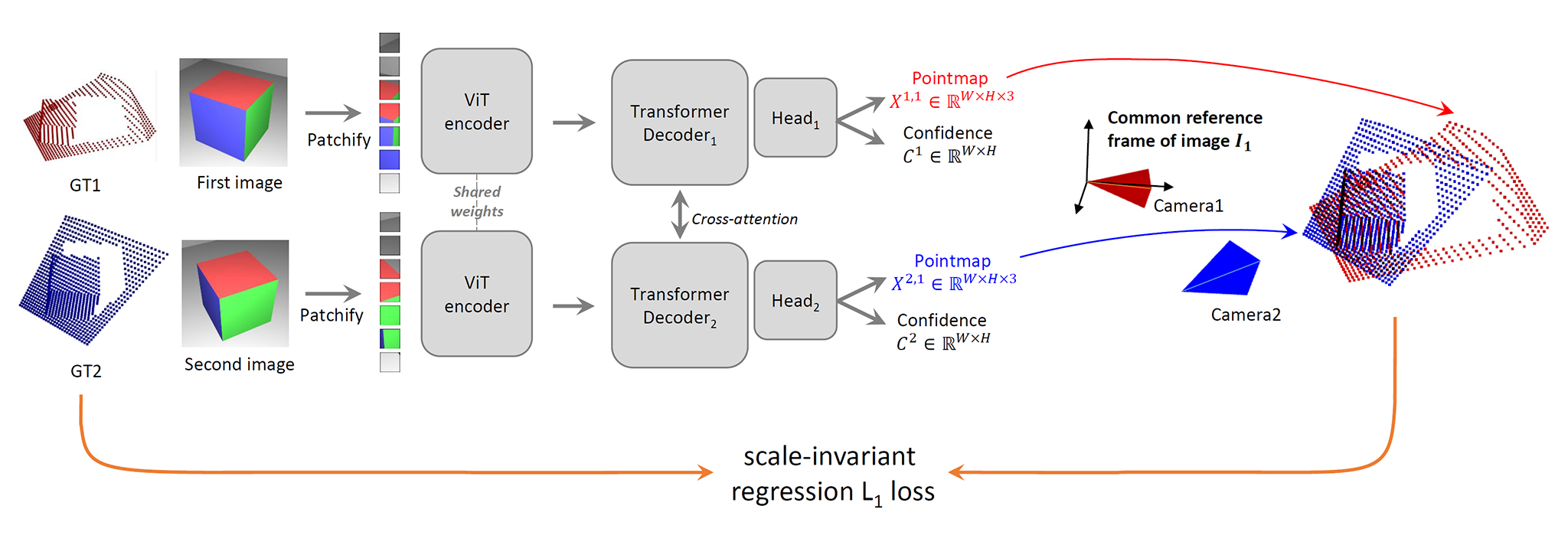
DUSt3Rの根幹はViT(Vision Transformer)ベースのニューラルネットワークによる推論処理。
2枚のRGB画像を入力とし、入力画像2枚の全ピクセルに対応するPointmap(3D位置座標)とConfidence(推定信頼度)を出力する。
入力 Image :RGB画像 (W×H×3)
Image :RGB画像 (W×H×3)
出力 Pointmap :Image
Confidence :Pointmap
Pointmap :Image
Confidence :Pointmap
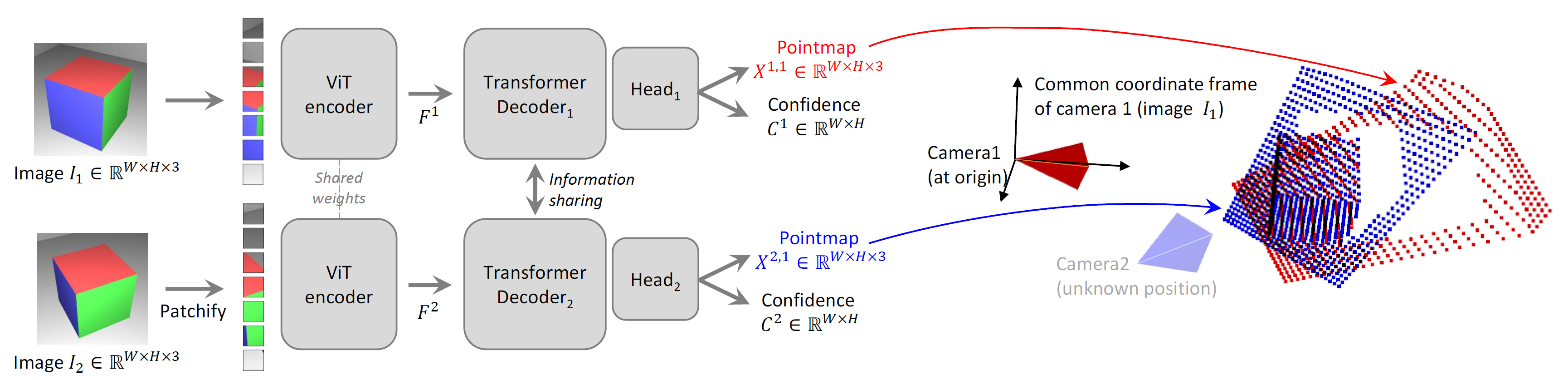
出力される2つのPointmapの3次元座標系は、入力画像1枚目の撮影カメラ位置を原点とした同一の座標系。
Pointmapとして入力画像2枚の全ピクセルの3次元位置座標が推定され3Dの対応関係が求まるので、その情報を利用してPnP問題を解けば撮影カメラの姿勢(位置・向き)も算出できる。
また、入力画像2枚に同一の画像を使用すると、画像1枚から全ピクセルの3次元位置座標を推定でき、単眼Depth推定と同等の出力を得ることができる。
DUSt3Rの応用範囲
このようにシンプルに定式化されたDUSt3Rの推論機能を応用すれば、3Dコンピュータービジョンの様々なタスクを下流タスクとして解くことができる。2枚の画像の3次元的な対応関係が推定できるので、3枚以上の複数画像についても、2枚ずつ取り出したペアごとの推論処理を複数回行えば全画像の3次元的な対応関係を推定できる。
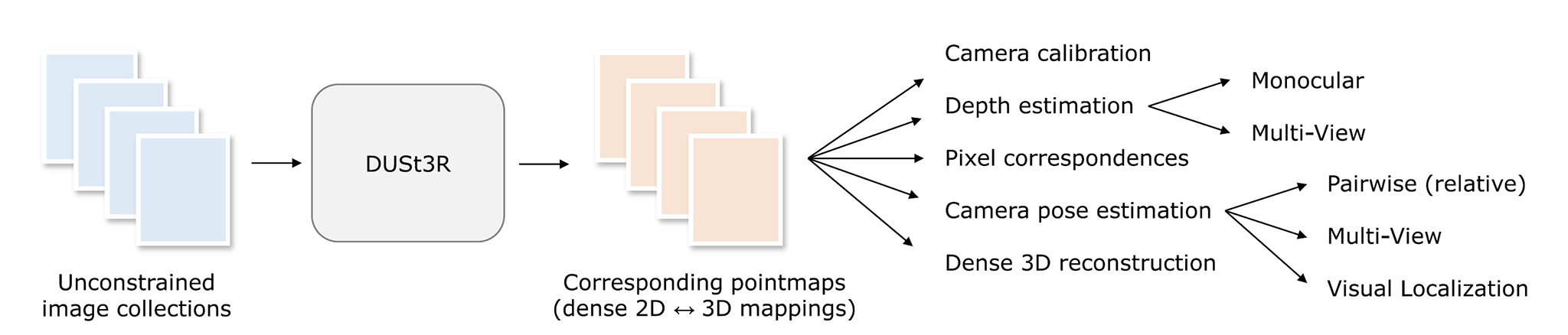
DUSt3Rの推論によって2視点の2D画像上の位置と3D空間上の位置の対応関係が既知となるので、既存の幾何計算手法を使って3Dコンピュータービジョンの様々なパラメータを算出できるわけですね。
DUSt3R発表後、すでに多くの派生研究が発表されている↓
https://github.com/ruili3/awesome-dust3r
https://europe.naverlabs.com/research/3d-foundation-models/
DUSt3R公式のソースコードをWindows環境で動かす方法は以前別記事にまとめた↓
DUSt3RのソースコードのライセンスはCreative Commons Attribution-NonCommercial-ShareAlike 4.0で商用利用不可。
配布されている学習済みモデルも商用利用不可のデータで学習されたものらしい。(学習済みモデルは最大512×512解像度の画像入力に対応)
DUSt3Rの仕組みを学びやすいよう有志が作成したミニマムなコードもある。
この実装はONNXエクスポートに対応しているので、Netronでネットワーク構造を可視化して見ることもできる。(ネットワークが巨大過ぎてあまりピンと来ないけど)
ネットワーク構造の定義のコードを読むのが1番理解が捗るかも。
DUSt3Rの仕組み
DUSt3Rの概要が分かったところで、DUSt3Rの仕組みについて詳しく見て行こう。
従来の3Dビジョン
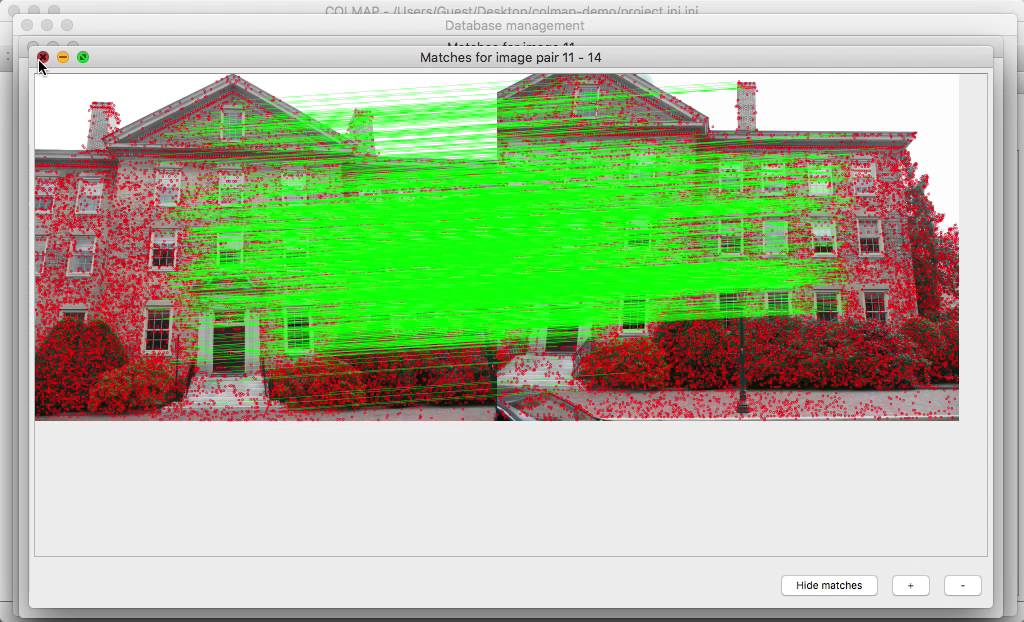
過去数十年、シーンを複数視点で撮影した2D画像からシーンの3D情報を復元する手法が研究されてきた。近年Photogrammetryによる3Dスキャンツールが普及しているのはその恩恵だ。
「複数視点の2D画像からシーンの3D情報を復元する」とはつまり、シーンの3Dジオメトリと撮影カメラパラメーターを推定すること。
一般的にPhotogrammetryと呼ばれている処理は、複数のコンピュータービジョンタスクを段階的に解くことでボトムアップに実現されている。
Photogrammetryの根幹となっている「疎な3D情報を求める」(Sparse 3D Reconstruction)タスクのStructure from Motionを例に挙げると、以下のようなサブタスクを順に連結したパイプラインで実現されている。
Structure from Motionのパイプライン
- Feature Detection(特徴点検出):画像から局所特徴点を検出する
- Feature Matching(特徴点マッチング):複数画像間の特徴点の対応関係を求める
- Initial Reconstruction(初期再構成):得られた対応関係から幾何学的関係の初期値を推定する
- Camera Pose Estimation(カメラ姿勢推定):カメラの相対姿勢を推定する
- Triangulation(三角測量):特徴点の3D位置を推定する
- Bundle Adjustment(バンドル調整):全画像について最も矛盾の無い幾何学的関係を求める(誤差最小化)
PhotogrammetryではStructure from Motionによって得られた疎な3D情報を利用して、後続のサブタスク(Multi-View Stereoなど)でより詳細な3D情報の算出(Dense 3D Reconstruction)を行っていく。
従来の3Dビジョンの問題
しかし、3Dビジョンのパイプラインの各サブタスクは精度100%で解けるわけではない。サブタスクで発生する誤差やエラーは次のサブタスクへのノイズとなり、次以降のサブタスクでそのノイズを補正する手がかりを知る術はない。その結果、パイプラインが進むほど各サブタスクで発生したノイズが蓄積され、最終的な3D復元精度の低下につながる。
この問題に対して、従来は個々のサブタスクの精度を高める研究が盛んに行われてきた。
特に、パイプラインの最初のステップであるFeature Detection, Feature Matchingで発生するノイズは以降の全てのサブタスクを狂わせてしまうため、古典的問題でありながらDeep Learning時代になっても盛んに研究されてきた。
https://github.com/cvg/LightGlue
DUSt3Rのアプローチ
従来の3Dビジョンがサブタスクを積み重ねてボトムアップ的に3D情報を算出・詳細化していたのに対し、DUSt3Rはその構造を大きく変えるトップダウン的アプローチを取っている。
冒頭で説明した通り、DUSt3Rでは2枚の画像から詳細な3D情報(全ピクセルの3D位置)を直接推定するニューラルネットワークを構築。従来の3Dビジョンでは中間処理を担っていた様々なサブタスクを、このニューラルネットワークの推定結果から算出できる下流タスクと位置づけた。
サブタスクに分解されたパイプラインによって多くの誤差や情報欠落が発生していた従来手法に対して、DUSt3Rは2D画像と3D構造の関係を1つのニューラルネットワークで学習することで、ViTの特徴抽出能力を活かしたEnd-to-Endの3D復元を実現した。
DUSt3RはFeature Detection, Feature Matchingを経ないことで、従来のStructure from Motionの欠点であった局所特徴点の少ないシーン、視差や画像枚数が不足した条件でも高い3D復元性能を示した。
DUSt3Rの学習
DUSt3Rのネットワークの学習はDepth付き多視点画像データセット(約850万ペア)を用いた教師あり学習だが、学習の初期化にCroCo(Cross-View Completion)による事前学習を活用している。
DUSt3Rの学習
CroCo (Cross-View Completion)
CroCo(Cross-View Completion)は、多視点画像から3D空間を推論する能力をニューラルネットワークに獲得させる自己教師あり学習手法。

シーンを撮影した複数視点画像1枚について画像の一部をマスクし、Cross-View Completion(異なる視点の画像の情報を使ってそのマスク箇所を補間)できるよう学習する。
CroCoのネットワーク
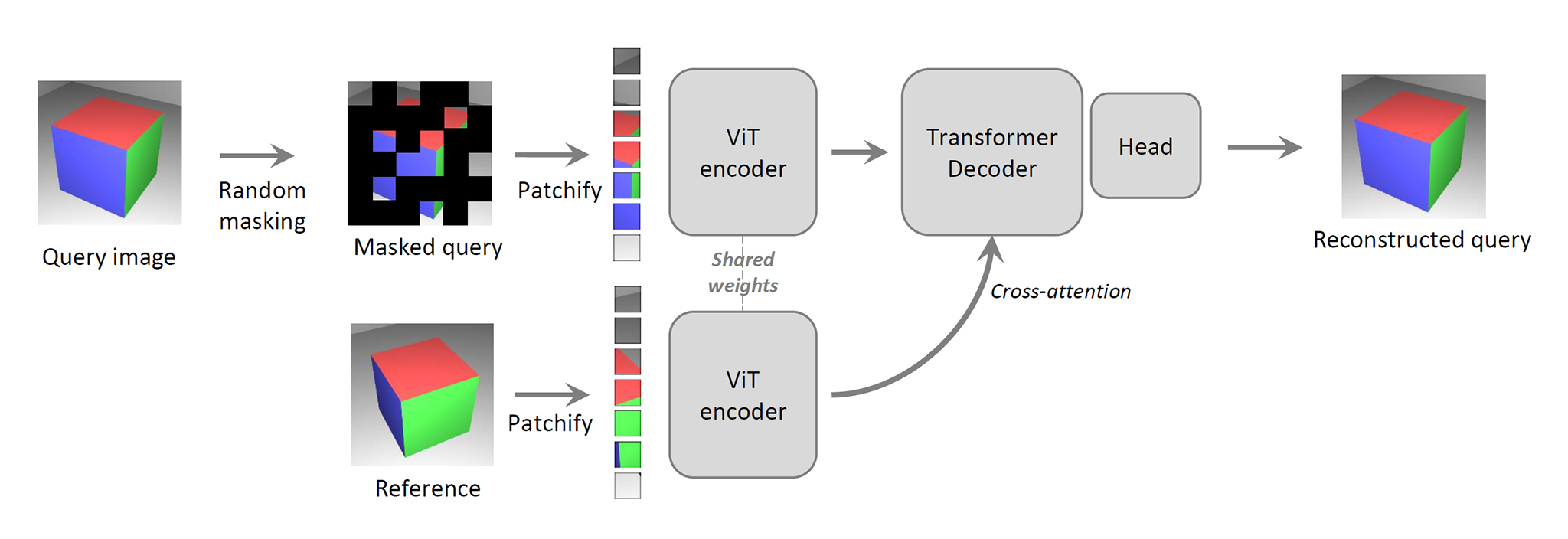
DUSt3Rは、多視点画像からシーンの3次元的構造を推論する能力を獲得したCroCoの重みを初期値として、2視点目に対応するDecoderとHeadを追加して学習される。
Global Alignmentによる3枚以上の画像への対応
DUSt3Rのネットワークは2視点(画像ペア)の入力にしか対応していないが、3枚以上の複数視点に対応するための後処理としてGlobal Alignmentが提案されている。
Global Alignmentは従来の3DビジョンでBundle Adjustmentに相当するような誤差最小化処理だが、Bundle Adjustmentが3D空間の点を2D画像に再投影した際の誤差を最小化するのに対し、Global Alignmentは3D空間で直接点群同士の位置合わせを行い、3D空間上での誤差を最小化する。
複数の画像ペアからDUSt3Rのネットワークがそれぞれ独立して推論したPointmapについて、Global Alignmentで1つの3D座標系に統合・矛盾のない3D点群を構築する。
Global Alignmentによって得られた矛盾の無い3D点群を利用して様々な下流タスクを解くことができる。
公式のソースコードを確認すると、どうやら2視点の場合でも、画像の入力順を変えて2回推論を行った後にGlobal Alignmentを行っているようだ。2枚の画像のどちらを1つめの視点として入力するかによって推論結果に偏りがあるのだろうか。
DUSt3Rの下流タスク性能
論文中では、以下の3Dビジョンタスクを下流タスクとして解いた場合にDUSt3Rが既存のState-of-the-Art手法に匹敵する性能を示したことが紹介されている↓
- Visual Localization
- Multi-view Pose Estimation
- Monocular Depth Estimation
- Multi-view Depth Estimation
- 3D Reconstruction
一方、従来の3Dビジョンの初期ステップであったFeature Matchingタスクについては、DUSt3Rの下流タスクとして解いても精度があまり良くなく、後に同研究チームからMASt3Rという改善手法が発表された。
逆に言うと、DUSt3Rは従来とアプローチが逆だからFeature Matchingの性能と関係なくトータルの3D復元性能が高いことを示している。
参考資料
今のところDUSt3Rの解説を日本語で読めるのはSpatial AI Networkの発表資料とコンピュータビジョン最前線の最終号「コンピュータビジョン最前線 Summer 2025」

派生研究
DUSt3Rの派生研究であるVGGT(Visual Geometry Grounded Transformer)はCVPR 2025でベストペーパーに選ばれた。
Many Congratulations to @jianyuan_wang, @MinghaoChen23, @n_karaev, Andrea Vedaldi, Christian Rupprecht and @davnov134 for winning the Best Paper Award @CVPR for "VGGT: Visual Geometry Grounded Transformer" 🥇🎉 🙌🙌 #CVPR2025!!!!!! pic.twitter.com/2nhX8jbMMX
— Visual Geometry Group (VGG) (@Oxford_VGG) June 13, 2025
余談
ここ数年流行りだったNeRFや3D Gaussian Splattingも最初のステップはStructure from Motionに依存していたことを考えると、DUSt3Rの登場によってまた大きな変化が起こりそうだ。

Radiance Field系は視線依存の光の変化を捉えられるリアリティが大きな価値ではあるので、視点の数が減ってしまうと質感表現が追いつかなくなりそうだ。そこを補うのはマテリアル推定技術とかかな。
最近はAIツールの充実で研究論文を読むのが格段に楽になり、以前は時間的に難しかったザッピングも割とできるようになった。
![]()
公式に公開されるソースコードも、最近はGitHub Copilotの補助を借りて読むことができる。機械学習分野ではPythonがデファクトスタンダードになっているものの、Pythonコードは規模が大きくなると読みにくかったのでとても助かる。
関連記事
Google Colaboratoryで遊ぶ準備
Houdiniのライセンスの種類
UnityでARKit2.0
SSII2014 チュートリアル講演会の資料
ZBrushでUndo Historyを動画に書き出す
第20回 文化庁メディア芸術祭『3DCG表現と特撮の時代』
Physically Based Rendering
スクラッチで既存のキャラクターを立体化したい
Polyscope:3Dデータ操作用GUIライブラリ
機械学習のオープンソースソフトウェアフォーラム『mloss(...
SONY製のニューラルネットワークライブラリ『NNabla』
書籍『仕事ではじめる機械学習』を読みました
参考になりそうなサイト
ManuelBastioniLAB:人体モデリングできるBl...
cvui:OpenCVのための軽量GUIライブラリ
Adobeの手振れ補正機能『ワープスタビライザー』の秘密
注文してた本が届いた
Zibra Liquids:Unity向け流体シミュレーショ...
OpenSfM:PythonのStructure from ...
ZBrushでアヴァン・ガメラを作ってみる 頬の突起を作り始...
C#で使える遺伝的アルゴリズムライブラリ『GeneticSh...
Kornia:微分可能なコンピュータービジョンライブラリ
オープンソースのネットワーク可視化ソフトウェアプラットフォー...
ラクガキの立体化 胴体の追加
全脳アーキテクチャ勉強会
映画『ジュラシック・ワールド/新たなる支配者』を観た
iOSで使えるJetpac社の物体認識SDK『DeepBel...
Maya LTのQuick Rigを試す
ZBrushと液晶ペンタブレットでドラゴンをモデリングするチ...
ゴジラ(2014)のディティール制作の舞台裏
VCG Library:C++のポリゴン操作ライブラリ
ZBrushでアヴァン・ガメラを作ってみる 頭頂部の作り込み...
オープンソースの物理ベースGIレンダラ『appleseed』
Qlone:スマホのカメラで3Dスキャンできるアプリ
Pylearn2:ディープラーニングに対応したPythonの...
ZBrush 2018へのアップグレード
ZBrushでアヴァン・ガメラを作ってみる 壊れたデータの救...
Deep Fluids:流体シミュレーションをディープラーニ...
SVM (Support Vector Machine)
ラクガキの立体化 モールドの追加
Raytracing Wiki
OpenGVのライブラリ構成

コメント