Kinectの骨格検出で使用されているという機械学習アルゴリズムのRandom Forestについて、ちょっと勉強してみた。
オイラはRandom Forestの存在をSSII 2013のチュートリアルで初めて知ったんだけど、当時は機械学習の分野を知らなさ過ぎてピンとこなかった。
チュートリアルの資料はこちら↓
ランダムフォレストの 基礎と最新動向
Random Forestは仕組みが単純な割に高性能で、処理も速くて最近は結構色んな用途に使われている。Randomized Treesとか、呼び名はいくつかあるらしい。
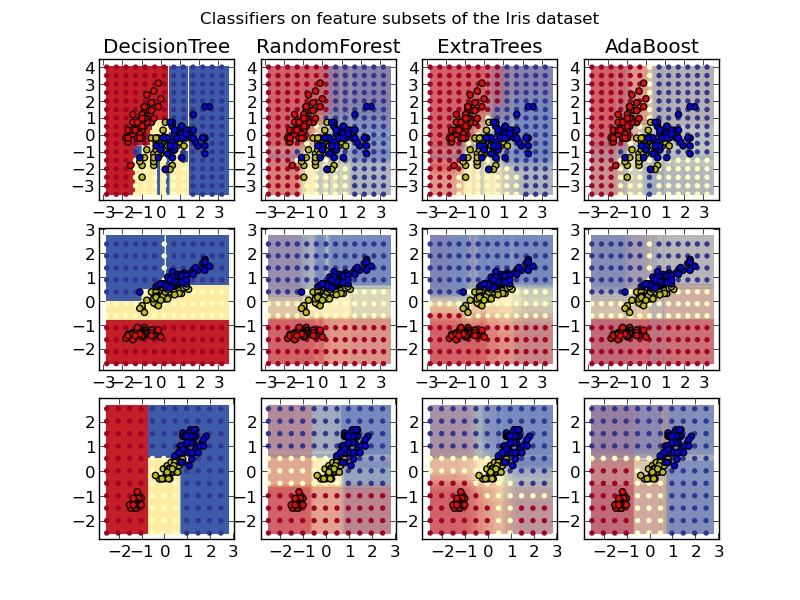
以下の画像はRandom Forestと他の手法のクラス分類を比較したscikit-learnのサンプル。3色のつぶつぶ(Iris datasetのサブセット)をどのようにクラス分けしたかが図示されている。エリアの色が分類結果。↓
集団学習手法の1つ
このRandom Forestという手法は、弱い学習器を複数組み合わせて強い学習器を作る「集団学習」というジャンルの機械学習手法の1つ。集団学習はアンサンブル学習と呼ばれたりもする。
Random Forestの特長
Random Forestはクラス分類、回帰、クラスタリングに利用できる。この手法の大きな特長は、1つ1つの弱識別器が二分木で入力値を選別する「決定木」でできていること。そして、学習をランダムサンプリングによって行う。学習データをランダムにサンプリングして学習した複数の決定木を使用するから、ランダムで作った木の集合”森”(フォレスト)ということで「ランダムフォレスト」という呼び名がついている。
例えばクラス分類なら、決定木1つが「弱識別器」となり、決定木の集合である「森」が「強識別器」というわけ。複数の決定木が出した識別結果を多数決してRandom Forestの識別結果にする。決定木1つ1つでは単純な分割しかできないけど、複数集まると結構複雑な切り分けができたりする。
扱うデータの対象によっては、同じく集団学習を用いるブースティングよりも有効だとか。
参考資料
Random Forestは様々なライブラリで実装されていて、結構実用的な手法だけど、日本語の解説資料が結構少ない。
中部大学の藤吉先生が基本アルゴリズムから発展手法まで紹介した資料を公開している。
あと、こちらのブログ記事もわかりやすいかな。↓
http://alfredplpl.hatenablog.com/entry/2013/12/24/225420
手軽に試すには
実はRandom Forestを実装しているライブラリは山ほどある、というか、機械学習のライブラリだったらとりあえずRandom ForestとSVMぐらいは当たり前のようだ。以前紹介したPythonのscikit-learnもそう。
ちなみに、OpenCVでは機械学習アルゴリズムを扱うmlモジュールの中にRandom Treesという名前で実装されている。→Random Trees
インターフェイスがcv名前空間に属してない古い1.x系のままっぽいのが気になるけど、3.x系からcv::ml::RTreesとして整備されるっぽい。
もちろんRでも利用できるパッケージが沢山ある。↓
パッケージユーザーのための機械学習(5):ランダムフォレスト
Random Forestはこの前紹介した機械学習のお勉強アプリMLDemosにも実装されているので、動作のイメージを掴むには良いかも。
自分でガリガリ実装するなら
Random Forestの仕組み自体はそれほど複雑ではないので、自分で実装して勉強してみるのもアリかもしれない。基本的に分割ノードと末端の葉ノードの木構造を表現できれば良いわけだから、C++で言うstd::vectorみたいな動的配列使うと楽に作れそうね。
ランダムフォレストをC++で書きました。
2015/3/30追記:
こちらがとても解りやすい。↓


コメント