GAN, DCGAN, CGANに引き続きGAN手法のお勉強。

順番に記事を書いてきて、やっとPix2Pixまで来た。
Pix2Pix
Pix2PixはCVPR 2017で発表された論文 Image-to-Image Translation with Conditional Adversarial Networksで提案された生成手法。
Pix2Pixも広い意味ではCGAN (Conditional GAN)の一種。
CGANでは「条件ベクトルと画像のペア」を学習データとしてその対応関係を学習していたが、Pix2Pixでは「条件画像と画像のペア」を学習データとしてその対応関係を学習する。
つまり、Pix2Pixは条件ベクトルの代わりに条件画像を使用し、画像から画像への変換問題を扱うCGANと言える。ここで言う「変換」は「翻訳」に近いニュアンスです。(原文ではtranslationと表記されている)
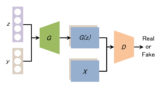
Pix2Pixの基本構造はCGANと似て以下の図のようになる↓
G:Generator
D:Discriminatorx:条件画像 (学習データ)
y:実画像 (学習データ)
z:ノイズベクトル
G(x, z):Generatorが生成した偽の画像
Generatorは条件画像xとノイズベクトルzから画像G(x, z)を生成する。
Discriminatorは「条件画像xと実画像yのペア」と「条件画像xと生成画像G(x, z)のペア」がそれぞれ本物かどうかを識別する。
この構造によって、Generatorが条件画像から本物のような画像を生成できるように画像ペアの関係を学習する。
スポンサーリンク
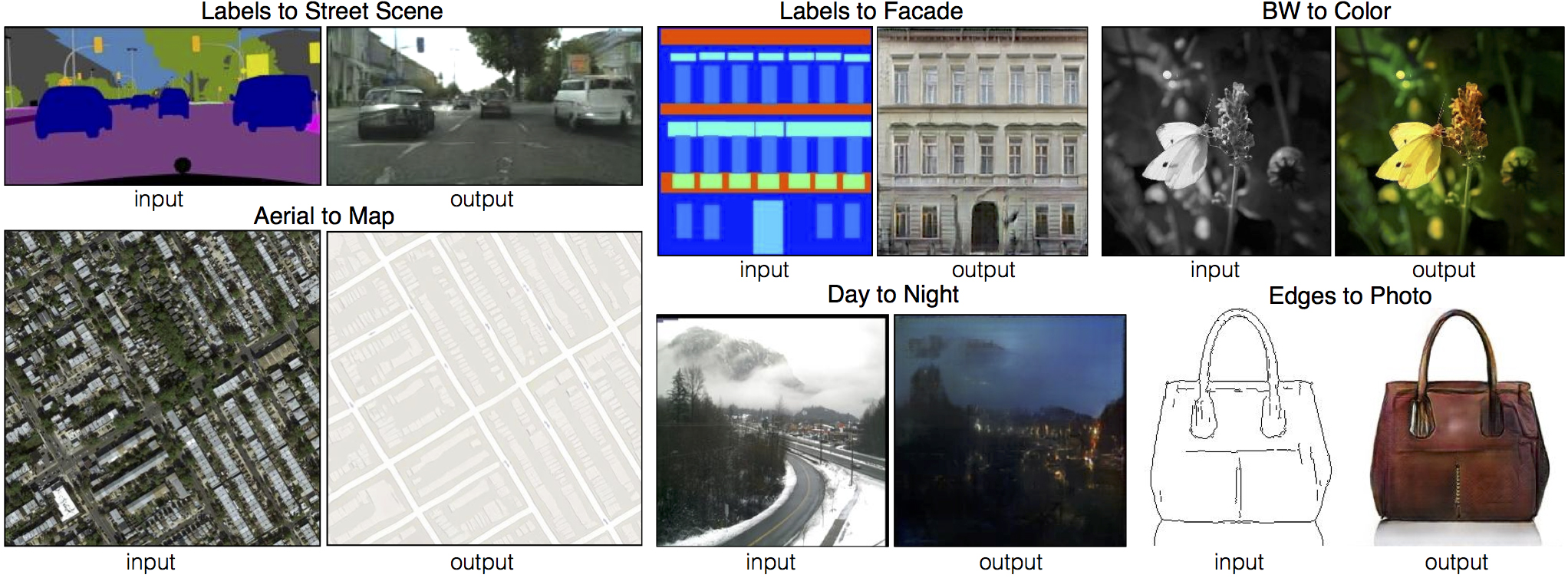
これによって、Pix2Pixでは衛星写真を地図画像に変換したり、白黒画像をカラー画像に変換したり、線画を写真に変換できるようになる。
Web上で試せるインタラクティブデモのおかげで誰でも手軽にPix2Pixの凄さを体感できる↓
では、もう少し詳しく見ていこう。
画像変換のアルゴリズムをGANで一般化する
CGや画像処理・コンピュータービジョン分野では、入力画像に何らかの処理を加えて出力画像を生成する変換問題が多く存在する。しかし、そこで使用されるアルゴリズムはそれぞれの用途に特化して個別に開発されたのもので汎用性が無い。
これら変換問題を扱うアルゴリズムをシンプルな共通のフレームワークに一般化しよう、というのがPix2Pixのモチベーション。個々の用途に合わせて人力で変換アルゴリズムを設計するのではなく、CGANの考え方を利用して入力画像・出力画像の関係から変換アルゴリズムを学習によって獲得させる。
Pix2Pixのネットワーク
Generator
Generatorのネットワークには、Semantic Segmentationで利用されるU-Netを使用する。

画像変換問題ではSemantic Segmentationと同様に画像ピクセルの細かいディティールを捉えることが重要となるため、Encoder-Decoder構造とスキップ接続で画像の詳細な情報を伝搬できるU-Netが適している。そしてPix2Pixでは、U-Netの複数の層にDropoutを設けることで各層にノイズベクトルzを与え、高品質な画像の生成を可能にしている。
最内レイヤーはDropoutなしだった。 pic.twitter.com/zEFSeBNBdF
— Teppei Kurita (@kuritateppei) April 9, 2020
畳み込みニューラルネットワークを使うという点で、Pix2PixはDCGANの延長とも言えますね。

ちなみにCGANは仕組み上、ノイズベクトルzが無くても条件だけで決定論的に画像を生成することも可能らしい。しかし、ノイズベクトルによる確率的要素が無いと、学習データと全く同じ分布しか表現できないGeneratorになってしまう。
Discriminator
通常、GANによる生成結果はややぼやけた画像となってしまう。Pix2PixのDiscriminatorでは、この問題に対処するための工夫が加えられている。
L1損失関数の追加
通常のGANでは、Discriminatorが本物と偽物を見分ける能力が向上するように目的関数を設計する。
しかし画像変換問題では、本物らしさだけでなく、入力画像と出力画像の一致具合を測る指標が別途必要となる。つまり、「条件画像と画像のペア」の一致度を保つための制約条件。
そこで、Pix2PixではDiscriminatorの損失関数にL1損失関数が加えられている。
L1損失関数を生成画像の低周波成分の正確さを測る指標として使用し、条件画像と生成画像の全体像が一致するよう学習させる。
以下はSemmantic Segmentationで使われるデータセット(ラベル画像と実画像のペア)を用いて、損失関数を変えた場合の生成結果の違いを比較したもの↓
スポンサーリンク

ちなみに、論文ではL1, L2と比較してL1の方が良い結果であるとも書かれてる。
ここでL1, L2についておさらい
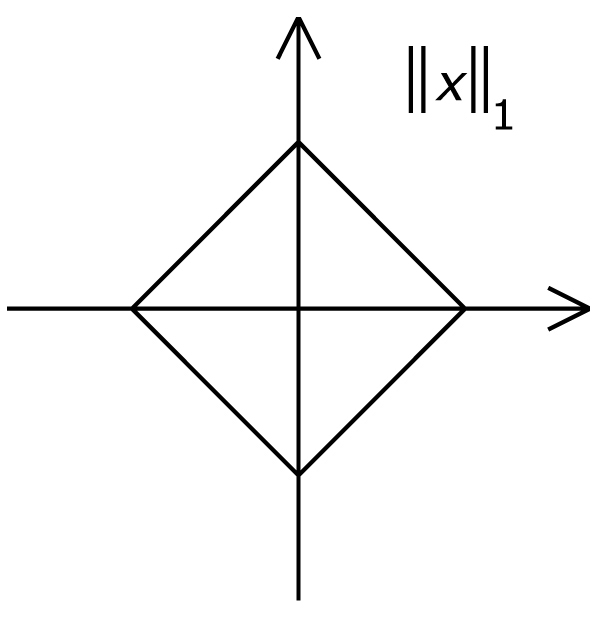
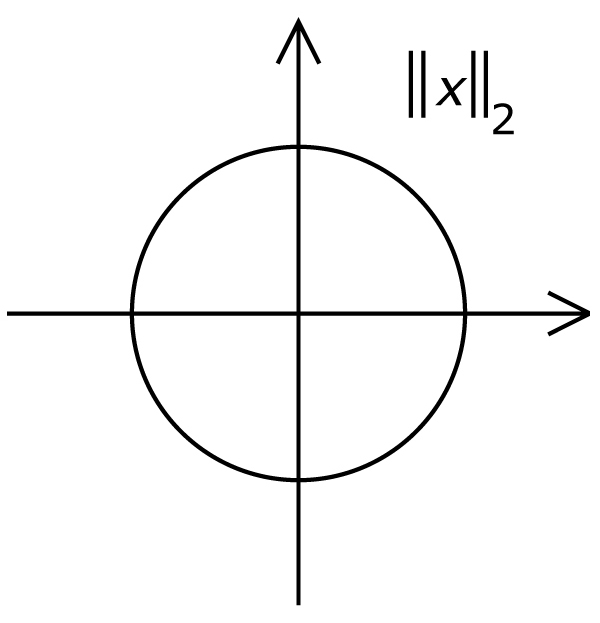
L1, L2はL1ノルム、L2ノルムのこと。
ノルム(norm)とはベクトルの長さを一般化したもの。LPとして一般化して表され、これは大きさ(距離)の測り方を表している。
P=2にすると(つまりL2ノルム)、ベクトルの長さを求めるお馴染みの式になる。(高校数学でもやりますね)
とりあえずL1とL2が分かっていれば色々な応用も理解できる。
- L1ノルム:マンハッタン距離 (碁盤の目のように縦横にしか移動できない距離)
- L2ノルム:ユークリッド距離 (いわゆる普通の距離)
PatchGAN
さらに、DiscriminatorにはPatchGANというアイディアが取り入れられている。
入力画像をN×N解像度のパッチに分解し、各パッチ単位で本物か偽物かの識別を行う。そして、全てのパッチの真偽値を平均したものをDiscriminatorの出力(つまり真偽値)とする。
Discriminatorが画像全体ではなく、パッチ単位での識別を学習することで、CGANの学習を画像の高周波成分のモデル化に専念させることができる。
Pix2Pixでは、画像の全体像(低周波成分)はL1損失関数で捉え、画像の詳細なディティール(高周波成分)はCGANで捉えるようにし、それぞれの短所を補完し合って精度を向上させている。
そして、GeneratorとDisciminatorの畳み込み層にはどちらにもConvolution-BatchNormalization-ReLUのモジュールを使用している。(今やお馴染みの構造ですね)
Pix2Pixの定式化
ここまでのことを式で見ていこう。
まず、通常のCGANの目的関数が以下↓
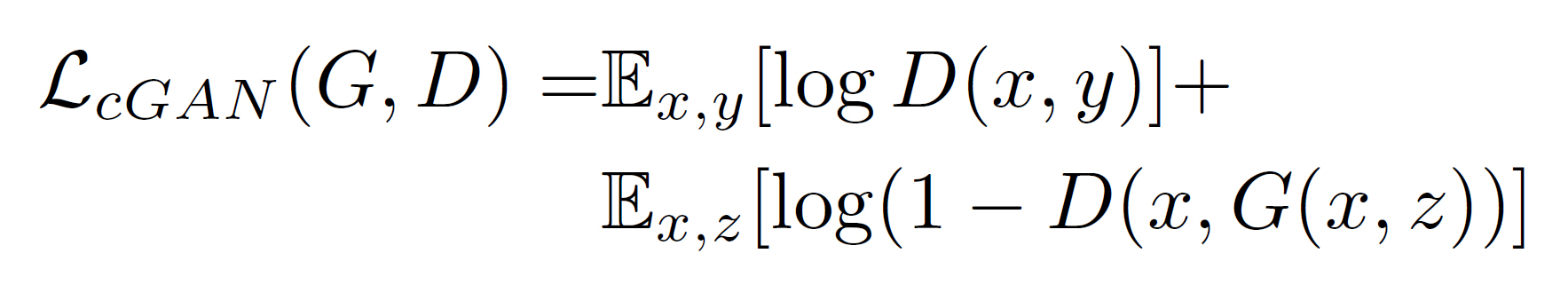
そして、L1ノルム損失関数が以下↓

これらを1つにまとめて、Pix2Pixの目的関数は最終的に以下の式になる↓
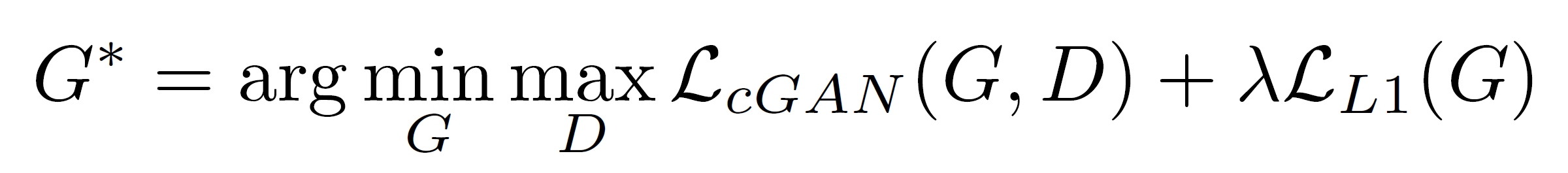
ここで、λはL1ノルム損失関数の重要度を制御するための重み変数。
実験の評価指標
これまで、GANで生成した画像の品質を評価する方法は曖昧で、定量的に評価するのは難しかった。
Pix2Pixによる生成画像が高品質なのは見ただけでなんとなく分かるが、論文ではちゃんと評価指標を定めて性能の定量的な比較・評価を試みている。
Pix2Pixの論文では、以下の2つの方法を使って生成画像の品質を評価している。
- AMT(Amazon Mechanical Turk)による知覚評価
- FCN-score
AMT(Amazon Mechanical Turk)による知覚評価
Pix2Pixによる航空写真から地図画像への変換やモノクロ画像のカラー化は、人間の目で見た妥当性を評価指標とし、AMT(Amazon Mechanical Turk)を利用して集めた被験者による知覚評価実験を行っている。
FCN-score
Pix2Pixで生成した都市景観画像については、生成画像が現実的かどうかを評価したい。
そこで、既存の画像認識手法で正しく認識できるかを評価指標として考える。Pix2Pixによる生成画像が現実的であれば、実画像だけで学習した識別器でも正しく分類できるはずである。
ここでは、Semantic Segmentationで使われるFCN-8sアーキテクチャを都市景観データセットで学習させ、Pix2Pixで生成した都市景観画像に対してSemantic Segmentationラベルをどれだけ正しく分類できるかをリアルさの評価指標としている。

Pix2Pixのソースコード
Pix2Pixはプロジェクトページにたくさんの例があり、PyTorchによる実装もGitHubにソースコードが公開されていて勉強しやすい↓
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
Telmo PieperのKiddie Arts
余談ですが、2014年にちょっと話題になったTelmo PieperというアーティストのKiddie Artsという作品がPix2Pixの処理とよく似ているのです。

Kiddie Artsは、Pieper氏が幼い頃に描いた下手クソな絵(線画)を現在のスキルでリファイン(ディティールアップ)するというアート作品。
今見ると、やってることが完全に人力Pix2Pixだよな。
https://www.designboom.com/art/telmo-pieper-reincarnates-childhood-drawings-digital-paintings-07-22-2014/
さて、この資料に則って↓
次はCycleGANを勉強しよう↓

スポンサーリンク


コメント