オイラはCG上がりの人間なので、ディープラーニングへの興味は画像認識のような識別系よりもっぱら生成系なのである。
最近はCG系の学会でもお馴染みになりつつあるGAN(敵対的生成ネットワーク)についてちゃんと知りたくて、その前知識としてニューラルネットワークの勉強をしていたのです。とりあえずPix2Pixまではちゃんと勉強したいところ。
機械学習の識別モデルと生成モデル
機械学習は大まかに識別モデル(Discriminative Model)と生成モデル(Generative Model)に大別できる。
今までブログ記事にまとめてきた手法は全て識別モデルだった。
GANについて学ぶ前に、まずは識別モデルと生成モデルの違いについて知っておこう。こちらの資料がとても分かりやすい↓
生成モデルでは、学習データの分布と生成データの確率分布が近づくように学習する。
画像系の場合、この確率分布の学習によって実画像に近い画像を生成できるようになる。
ニューラルネットワークを使った生成モデルではVAE: Variational Autoencoder (変分オートエンコーダー)も有名ですが、
オイラはとにかくGANについて知りたいのです。(歪んだモチベーション)
GAN (Generative Adversarial Networks)
ようやく本題。
GAN (Generative Adversarial Networks)はNIPS 2014で発表された論文 Generative Adversarial Netsで提案された生成モデル。
この論文を発端にGANの派生研究が爆発的に増えた。増え続けるGAN研究をまとめたGAN ZOOを見るとその量に圧倒される。
GANはゲーム理論から着想を得ており、プレーヤー同士が互いに自身の利得を最大化する戦略取ることで均衡する「ナッシュ均衡」という状態を目指して学習する。
要するに、プレーヤー同士が互角のバランスで強くなっていくライバル関係を実現するような学習方法。少年ジャンプ(というかドラゴンボール)的な世界観だと思えばすんなりイメージできる。
ちなみに、ナッシュ均衡を考案したJohn Nashは映画「ビューティフル・マインド」でも描かれた天才数学者。

GANの考え方
GANでは、偽のデータを生成するGenerator (生成器)と、データが本物か偽物かを判別するDiscriminator (識別器)を敵対させ、競わせることで互いの性能が向上するように学習する。
この関係は、偽造紙幣を作る偽造者とそれを見破る警察の関係に例えられる。
偽造者は本物そっくりの偽造紙幣を作ることを目指して訓練し、警察はどんな偽造紙幣でも見破れるよう訓練する。このイタチゴッコを続けることで、やがて偽造者は本物そっくりの偽造紙幣を作れるようになっていく。
GANではこの性質を利用して優秀な偽造者(Generator)を育て上げるわけです。これは偽造者(Generator)が本物の紙幣(データ)の確率分布を習得したということ。
ちなみに、GANの基本的な考え方に則れば、GeneratorとDiscriminatorはニューラルネットワークに限らずどんな最適化モデルでも良いそうです。
(と言いつつ、高い性能を示した例は全部ディープラーニングなので実質ニューラルネットワークがデファクトスタンダード)
GANの基本構造
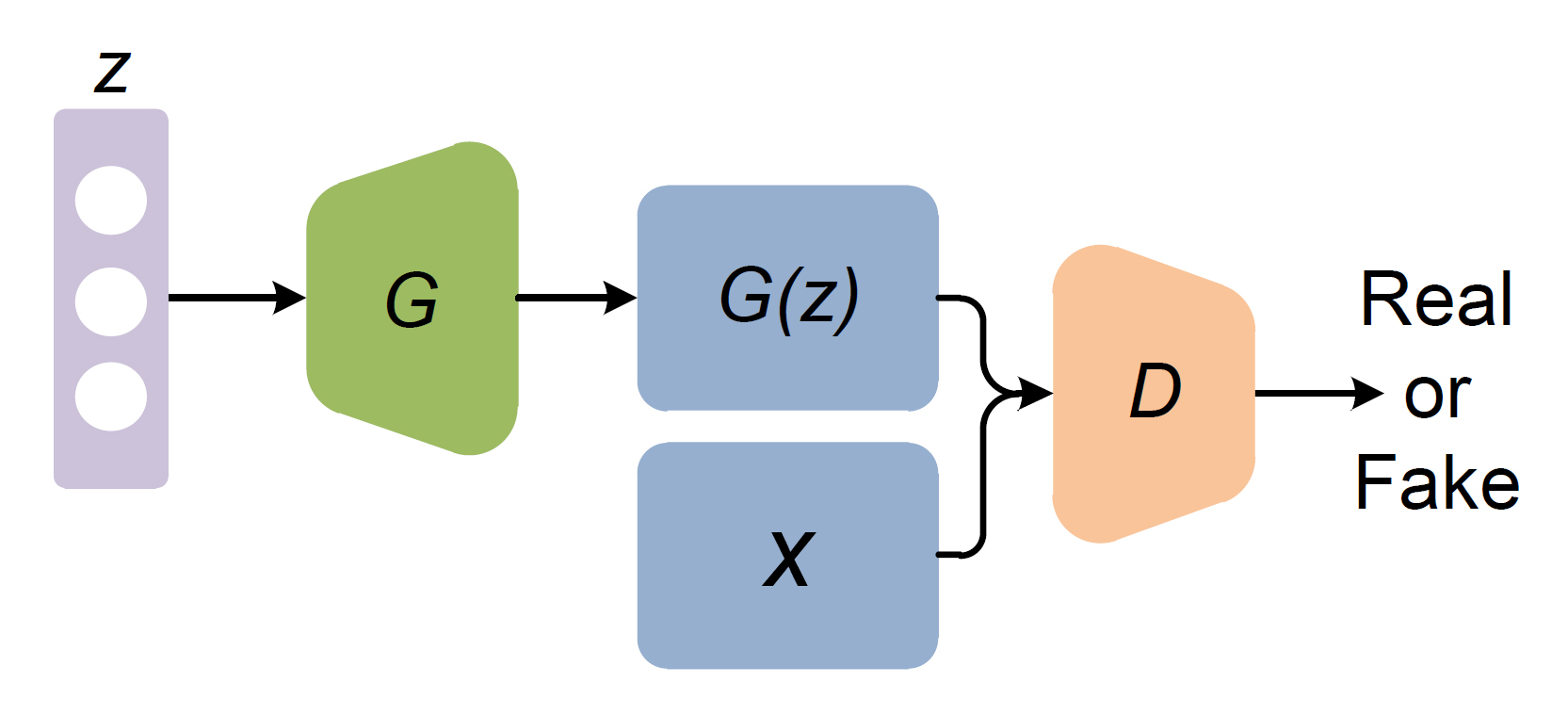
一般的に、GANで学習させるGenerator (生成器)とDiscriminator (識別器)にはそれぞれニューラルネットワークを使い、以下の図のような構成で学習する↓
G:Generator
D:Discriminatorz:ノイズベクトル
x:本物のデータ (学習データ)
G(z):Generatorが生成した偽のデータ
Generatorはノイズベクトルzを入力とし、偽のデータG(z)を生成する。
Discriminatorは、偽物のデータG(z)と本物のデータXを入力とし、それが本物か偽物かを判定する二値分類を行う。
GeneratorはDiscriminatorが本物と判定してしまうような偽データを生成できるように学習し、DiscriminatorはGeneratorが生成したデータが偽物だと見破れるように学習する。
Discriminatorが本物のデータXを学習することで、人間には上手く定義できない多次元の教師信号を獲得しているとも言えるのかな。
では、図中のそれぞれについて詳しく見て行こう。
ノイズベクトル z
一般的に、Generatorの入力となるノイズベクトルzには、-1~1の範囲で各値をランダム生成(一様分布 or 正規分布)した1次元のベクトル(1階のテンソル)が使われる。
Generator (生成器)
Generatorは、入力されたノイズベクトルzから本物のデータxの確率分布に近い偽データG(z)を生成できるよう学習する。
Generatorが本物のデータxと全く同じ確率分布の偽データを生成できれば、Discriminatorを完全に騙すことができるわけだが、それではxと同一のデータしか生成できないGeneratorになってしまう。
GANでは学習データに存在しないデータを生成するのが目的となるので、Generatorには学習データと同質の新しいデータを生成する生成過程を学習させる。
Discriminator (識別器)
Discriminatorは、入力された本物のデータと偽物のデータから、本物と偽物の確率分布を正確に識別できるよう学習する。入力されたデータが本物であれば1を出力し、偽物であれば0を出力する二値分類を学習する。いわゆる通常の識別器の学習と同様。
実データx, 偽データG(z)
ここまで、やや一般化して書いてきたけど、画像生成のGANなら、Discriminatorの入力xは画像データとなり、Generatorの出力G(z)もそれと同サイズの画像データとなる。
つまり、xはGANの学習で必要となる学習データのこと。Generatorが生成する偽のデータG(z)は、使用する本物のデータxに合わせて同様の仕様にする。
損失関数
GeneratorとDiscriminatorが影響し合って学習を進めるために、通常のニューラルネットワークとは違う損失関数が設計されている。
交差エントロピーに似ているものの、Generatorの損失関数にDiscriminatorが含まれているし、Discriminatorの損失関数にもGeneratorが含まれており、互いに依存した式になっている。
Generatorの損失関数
Generatorの損失関数は以下の式で定義される。※式中のmはミニバッチのサイズです。
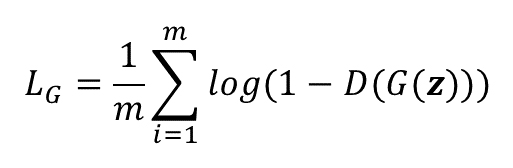
つまり、Generatorが生成した偽データG(z)をDiscriminatorに識別させ、本物と判定される(1が出力される)と最小になる式。D(G(z))を最大化するという言い方もできる。
実装では1から引く形ではなく、純粋にD(G(z))の最大化として扱わないと勾配消失が起きやすいとか。
Discriminatorの損失関数
Discriminatorの損失関数は以下の式のようになる。
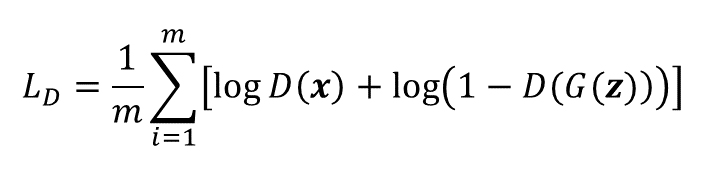
つまり、本物のデータxをDiscriminatorで識別すると本物と判定(1が出力)され、偽物のデータG(z)を識別すると偽物と判定(0が出力)されると最小になる式。
実装では単純に、本物のデータxをDiscriminatorで識別した誤差と、偽データG(z)を識別した誤差の和で表現されていたりする。
目的関数
GeneratorとDiscriminatorの2つの損失関数を合わせて、GAN全体の学習目標として目的関数に定式化すると以下のようになる↓
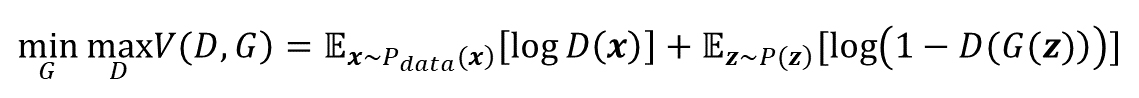
GeneratorとDiscriminatorのイタチゴッコ関係の定式化ということですね。
GANの学習
GANの学習ではGeneratorとDiscriminatorを交互に更新していく。論文では擬似コードのような表現でそのステップを解説している。
GANの学習プロセスは以下2つのステップの繰り返し↓
- Discriminatorの更新
- Generatorの更新
Generatorのパラメータを固定した状態でDiscriminatorを学習する。
ランダム生成したノイズベクトルzをGeneratorに入力し、偽データG(z)を生成する。そして、生成した偽データに対応する教師信号は「偽物」を表す0とし、本物のデータに対応する教師信号は「本物」を表す1としてDiscriminatorに入力して識別を行う。その識別誤差を逆伝搬してDiscriminatorのパラメータを更新する。
Discriminatorのパラメータを固定した状態でGeneratorを学習する。
ランダム生成したノイズベクトルzをGeneratorに入力し、偽データG(z)を生成する。そして、この生成した偽データに対応する教師信号を今度は「本物」を表す1としてDiscriminatorに入力して識別を行う。その識別誤差を逆伝搬してGeneratorのパラメータを更新する。
この1と2のステップを交互に繰り返すことで、GeneratorとDiscriminatorの性能が徐々に向上していく。両者の性能が向上することで、最終的にGeneratorは本物のデータと見分けがつかないほどリアルな偽データを生成できるようになる。
GANによる画像生成
以下の図はGANによって生成された画像。黄色枠で示されているのが学習データ(本物の画像)で、それ以外は全てGeneratorが生成した生成画像。

GANの実装
ここのコードをForkして、MNISTデータセットを使ったGANのPyTorch実装を自分でも試してみた。
PyTorch 1.1で動くようにちょっと修正↓
https://github.com/NegativeMind/GAN-MNIST-Pytorch
300エポックの学習過程を30秒の動画にまとめてみた。
Generatorの性能が徐々に上がっていくのが分かる↓
GeneratorとDiscriminatorのLossの変化だけ見ると何が起こってるのかさっぱり分からんな(笑) ↓
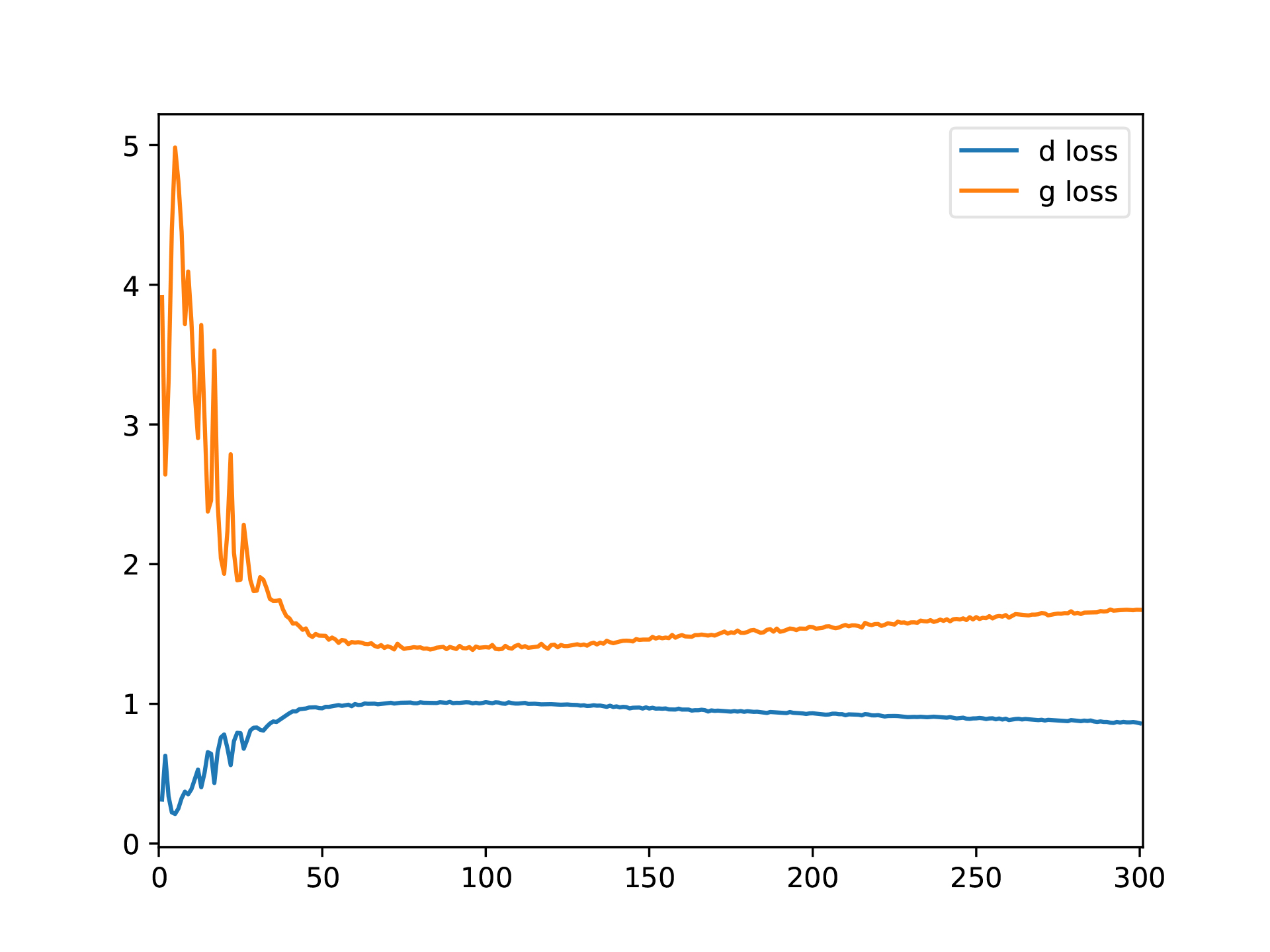
どちらもさほど0に近づいていないという(笑)
GANの学習の不安定性
GANはGeneratorとDiscriminatorの均衡状態を利用して学習を進めるわけですが、実際に均衡状態を維持したまま学習を進めるのはそう簡単ではないようです。
GANの学習を安定させるためのあの手この手が提案されている。という話が先日SSII 2019のチュートリアルセッションで解説されていました↓
派手な生成結果ばかりがGANの研究じゃないんですねぇ。
「naïveにやってみると…」という言い回しがもはや業界用語なのではないかと。。。
cvpaper.challengeでまとめてくれているその後のGAN研究を分類した資料と↓
こちらのPyTorch実装のリポジトリを見ながら勉強していくか↓
https://github.com/znxlwm/pytorch-generative-model-collections
追記:SONYのNeural Network Console公式YouTubeチャンネルでGANの解説が公開されている↓
順番的に、次はDCGAN (Deep Convolutional GAN)について勉強しよう↓



コメント