
引き続きGAN(敵対的生成ネットワーク)手法のお勉強。
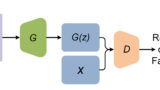

次はGANsの発展形のDCGAN (Deep Convolutional GAN)について。
GANの例としてはオリジナルのGANよりもDCGANの方がよく紹介されているイメージ。
DCGAN (Deep Convolutional GAN)
DCGAN (Deep Convolutional GAN)はICLR 2016で発表された論文 Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networksで提案された生成モデル。
オリジナルのGANでは生成画像がぼやけていたが、DCGANではより自然な画像の生成が可能になっている。
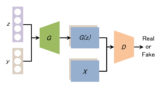
DCGANも基本的にはオリジナルのGANの考え方に則っており、GeneratorとDiscriminatorを競わせるように学習する。なので、全体の構造を概念図として表すとオリジナルのGANと同様になる↓
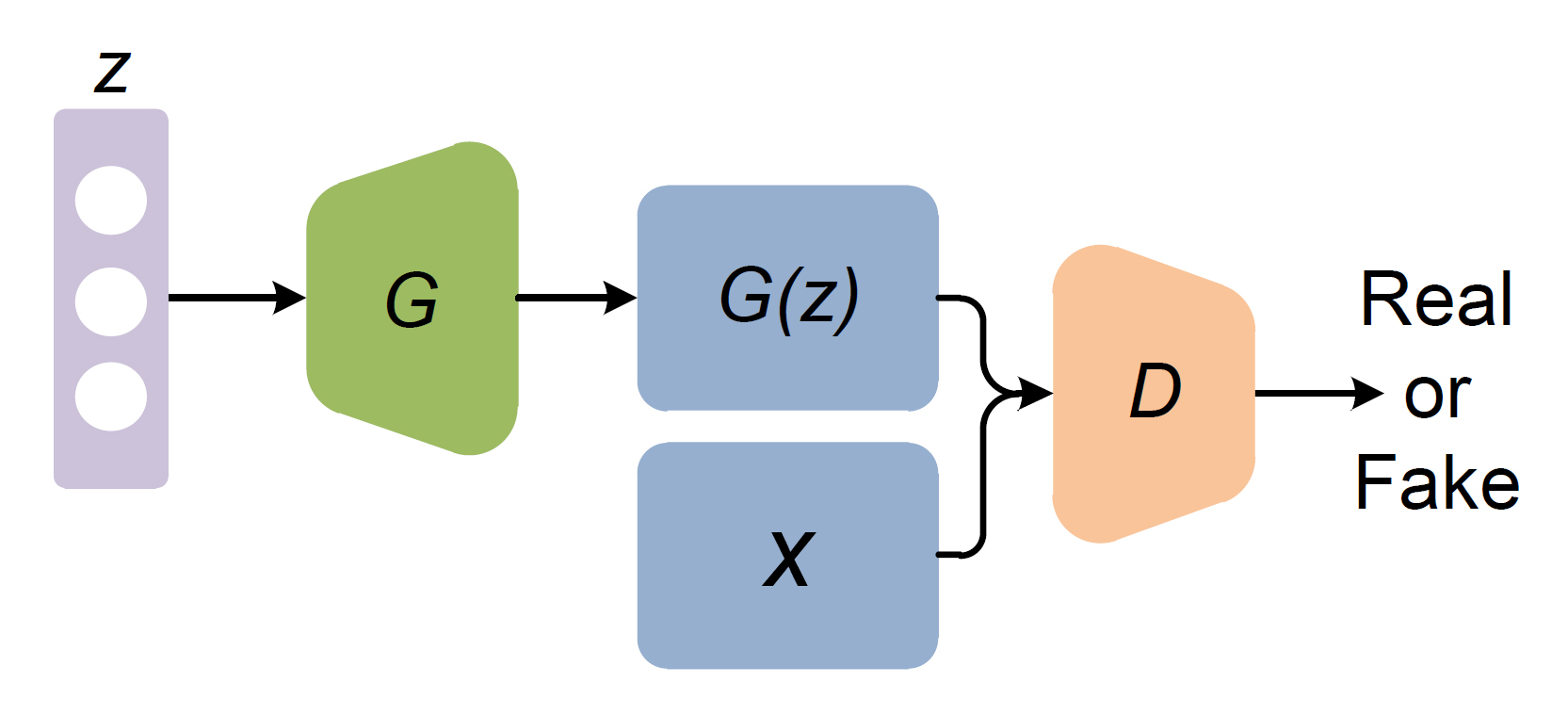
オリジナルのGANとの大きな違いは、GeneratorとDiscriminatorそれぞれのネットワークに全結合層ではなく、畳み込み層(と転置畳み込み層)を使用している点。
そして、GANの学習が安定しない問題に対しては、Batch Normalization (バッチ正規化)の導入や、活性化関数にReLUだけでなくtanh, Leaky ReLUを使用している。
では、Generator, Discriminatorそれぞれのネットワーク構造について詳しく見て行こう。
Generatorのネットワーク構造
Generatorのネットワークでは以下の図のように、入力となる100次元のノイズベクトルZから転置畳み込みによって徐々に64×64サイズの画像へとアップサンプリングしていく↓
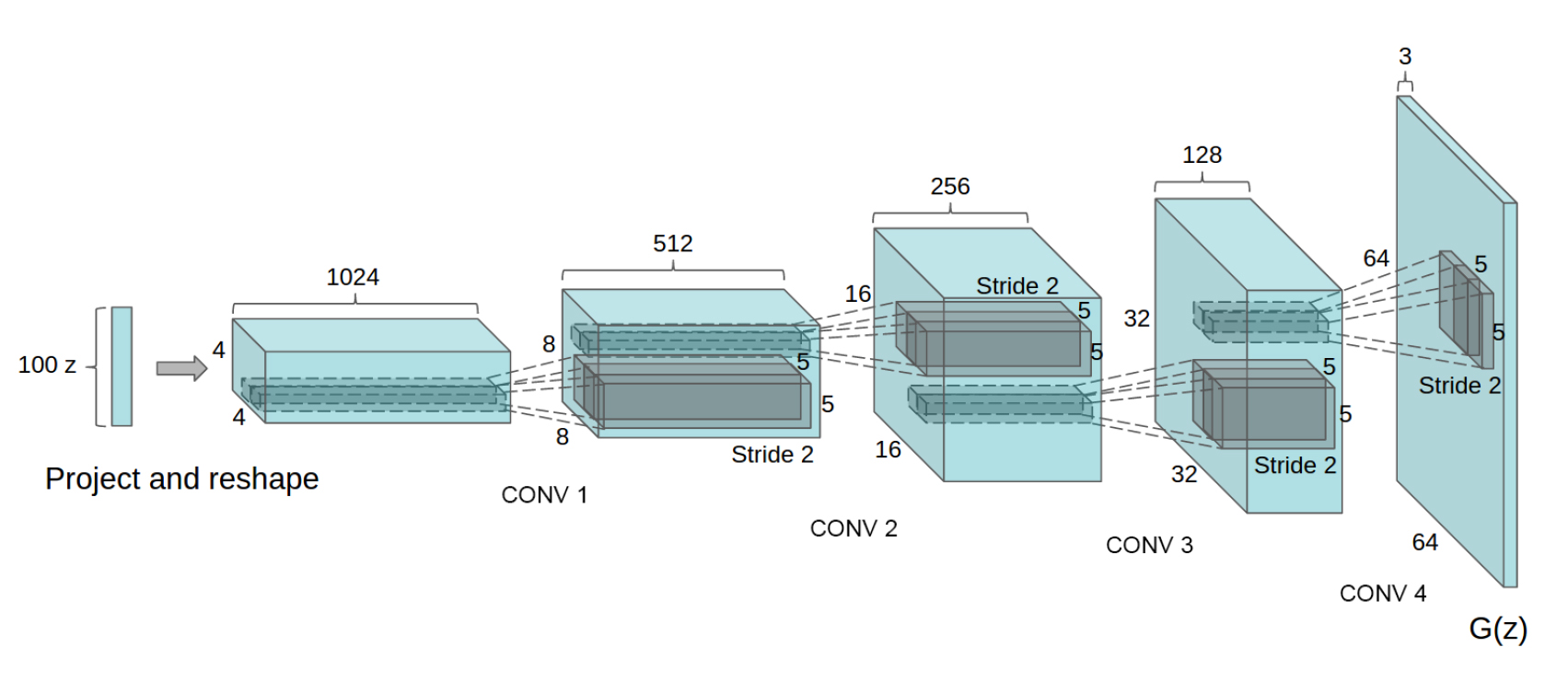
全結合層やpooling層は使用しない。
この図では省略されているけど、それぞれの転置畳み込み層の後にSegNetの記事でも解説したBatch Normalizationと活性化関数が入ります。活性化関数には基本的にReLUを使用し、最終層だけtanhを使用している。
転置畳み込み (transposed convolution)
やや余談ですが、この論文でfractional-strieded convolutionsと呼ばれているアップサンプリング処理は、基本的には以前FCNの記事で逆畳み込み(deconvolution)と呼んでいた処理と同様です。

後の様々な論文で逆畳み込みという呼び方が否定されているので、以後は転置畳み込みと呼ぶことにしましょう。
fractional-strieded convolutionsは基本的にはこの図のような処理で、strideが2でpaddingが0の処理↓

追記;転置畳み込みについてはこちらの図解がとても分かりやすい↓
Discriminatorのネットワーク構造
Discriminatorは、Generatorのアップサンプリング過程を逆にしたようなダウンサンプリング構造になる。
基本的には画像識別の畳み込みニューラルネットワークの構造を踏襲しているが、pooling層が無く、活性化関数にはReLUの代わりにLeaky ReLUを使用する。
poolingを畳み込みで代用する
通常、物体認識の畳み込みニューラルネットワークでは、max poolingで特徴マップを縮小(集約)して被写体の並進移動や形状変化をある程度吸収できるようにしている。これは、物体認識では物体の細かな特徴よりも全体を表す特徴を捉えた方が効果的なため。
一方、GANでは細かな特徴が重要となるため、poolingで細かな情報が欠落しては困る。そこで、DCGANのDiscriminatorでは、poolingの代わりにstride 2の畳み込み処理を行うことで細かな特徴の欠落を防いでいる。
Leaky ReLU活性化関数
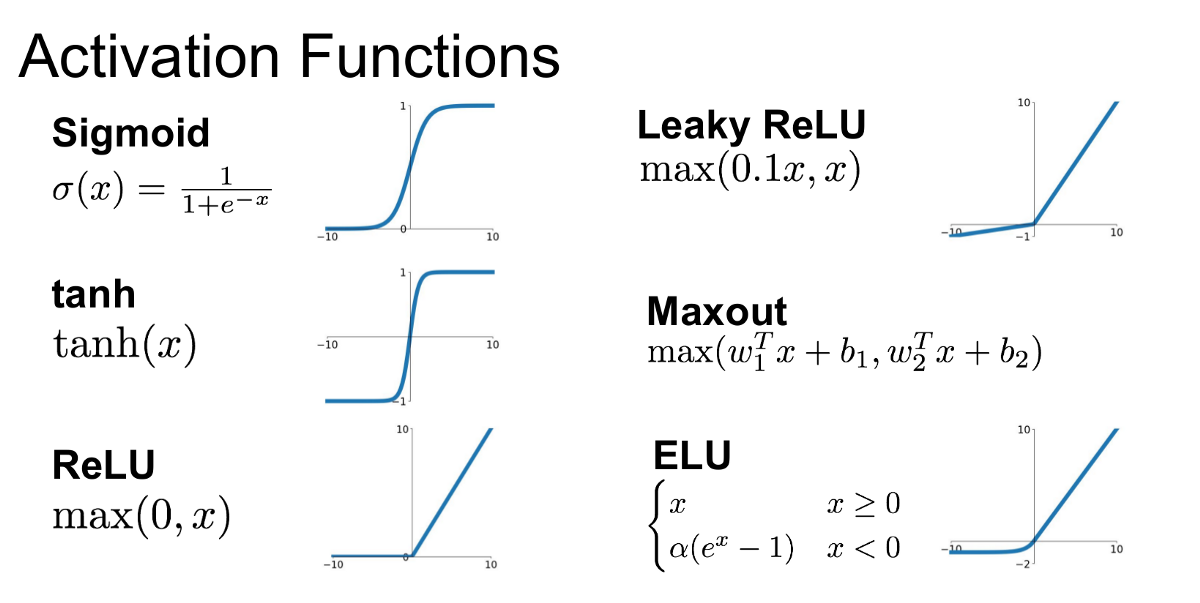
GANの学習の不安定性に対処するため、Discriminatorの活性化関数にはReLUの代わりにLeaky ReLUが導入されている。
通常のReLUでは入力が0未満の場合に出力が0になってしまうが、Leaky ReLUは入力が0未満でも出力が0にならず、負の値を出力する。これによって学習中に勾配が0になってしまうのを防ぐことができ、誤差逆伝搬が滞りにくくなっている。(その代わり、Leaky ReLU用のハイパーパラメータが増えている)
活性化関数ごとの出力値の違いはこちらの比較図が分かりやすい↓
DCGANの学習
DCGANの目的関数や学習ステップはオリジナルのGANと同様なので割愛。
DCGANによる画像生成
論文では、ベッドルームや人の顔画像の生成結果が紹介されている。


入力ベクトルの操作による生成画像の変化
入力ベクトルを変化させることで顔を別の向きへと滑らかに補間できる↓
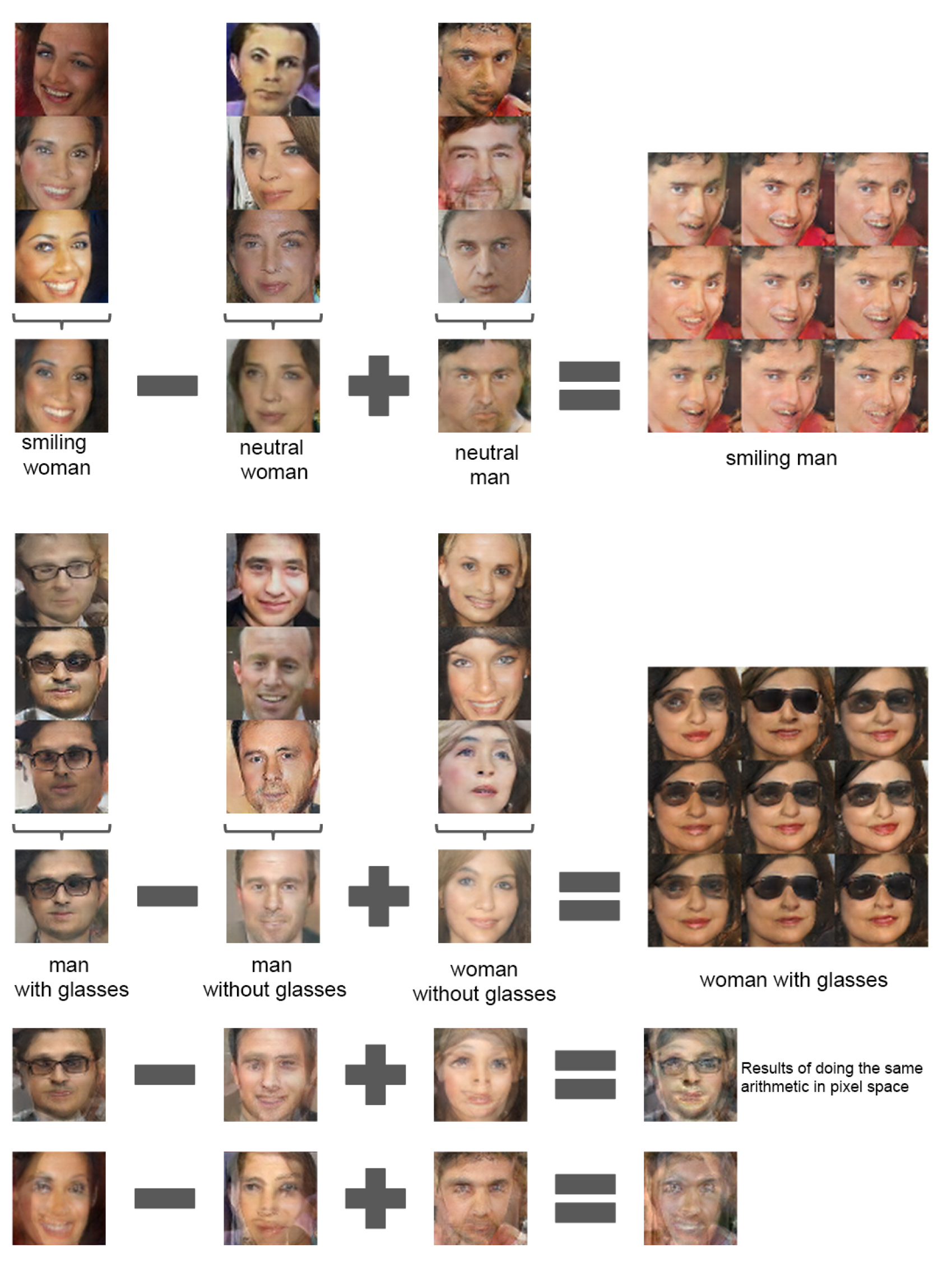
さらに、生成元となる入力ベクトルの演算によって、要素の足し算、引き算を行うことができる。これは自然言語処理のWord2Vecと同じ考え方。
例えば。
- 笑った女性 – 無表情の女性 + 無表情の男性 = 笑った男性
- メガネをかけた男性 – メガネをかけていない男性 + メガネをかけていない女性 = メガネをかけた女性
といった具合↓
ちなみに、入力ベクトルを変えると生成結果が変化する様子を体感できるデモサイトを見つけた↓
https://carpedm20.github.io/faces/
DCGANの実装
PyTorch公式で顔画像を生成するDCGANのチュートリアルがあるので、試すのは簡単。
チュートリアルのソースコードはこちら↓
https://github.com/pytorch/examples/tree/master/dcgan
オイラも試しにやってみた↓
https://github.com/NegativeMind/DCGAN-Face-Pytorch
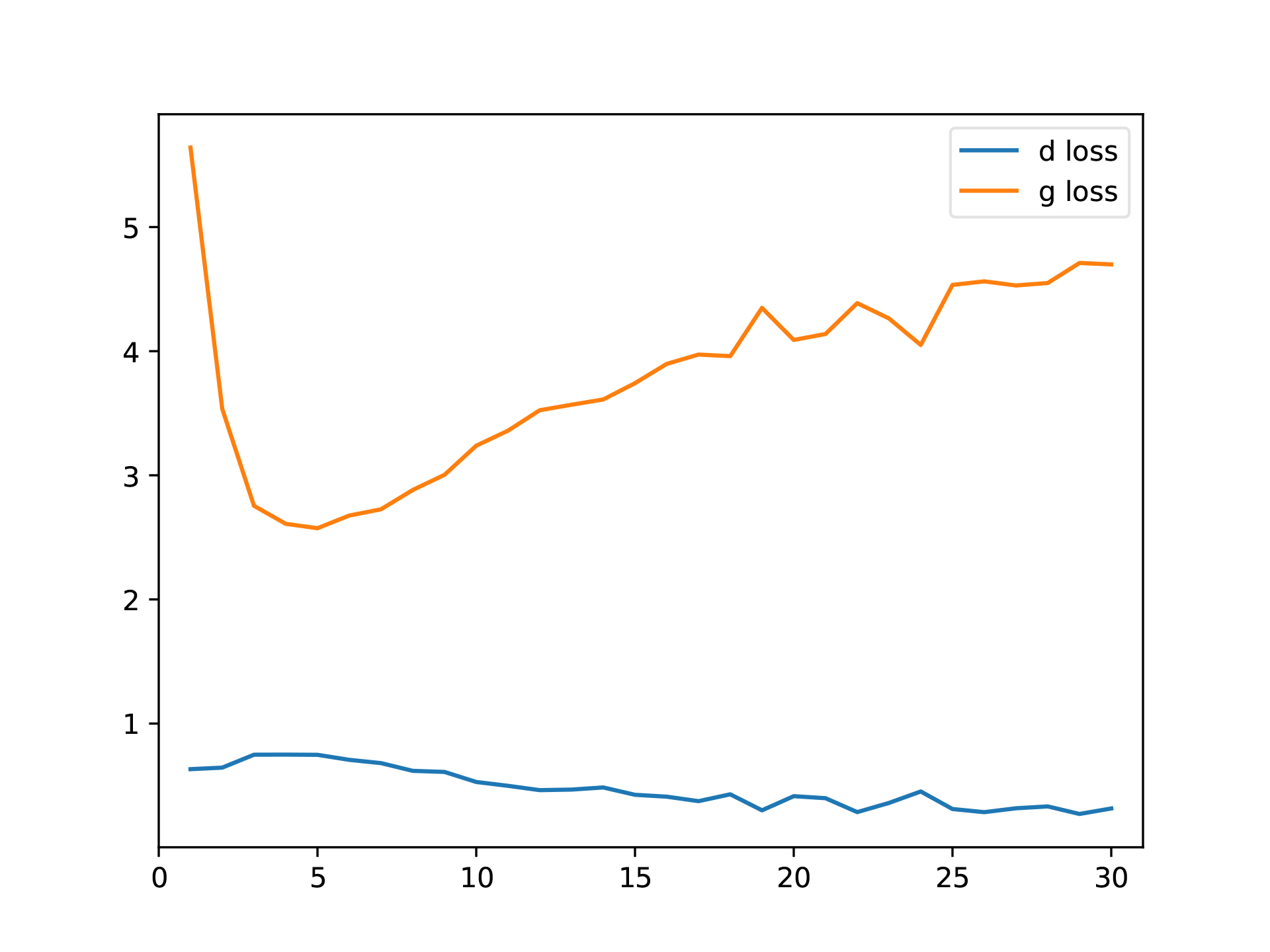
学習過程の可視化
学習過程を可視化した動画↓
例のごとく、GeneratorとDiscriminatorのLossの変化だけを見ると学習が収束へ向かっているのかさっぱりわからない(笑)
次はCGAN (Conditional GAN)を勉強しよう。
関連記事
Math.NET Numerics:Unityで使える数値計...
CGレンダラ研究開発のためのフレームワーク『Lightmet...
UnityでShaderの入力パラメータとして行列を渡す
OpenCVの顔検出過程を可視化した動画
SDカードサイズのコンピューター『Intel Edison』
ZBrushで作った3Dモデルを立体視で確認できるVRアプリ...
Blendify:コンピュータービジョン向けBlenderラ...
Physics Forests:機械学習で流体シミュレーショ...
Python2とPython3
Cartographer:オープンソースのSLAMライブラリ
Python for Unity:UnityEditorでP...
Adobeの手振れ補正機能『ワープスタビライザー』の秘密
Photogrammetry (写真測量法)
OpenAR:OpenCVベースのマーカーARライブラリ
MVStudio:オープンソースのPhotogrammetr...
Unityで学ぶC#
UnityユーザーがUnreal Engineの使い方を学ぶ...
ブラウザ操作自動化ツール『Selenium』を試す
geometry3Sharp:Unity C#で使えるポリゴ...
Kubric:機械学習用アノテーション付き動画生成パイプライ...
LLM Visualization:大規模言語モデルの可視化
Unity ARKitプラグインサンプルのチュートリアルを読...
機械学習手法『Random Forest』
GoB:ZBrushとBlenderを連携させるアドオン
WinSCP
OpenGVの用語
機械学習のオープンソースソフトウェアフォーラム『mloss(...
OpenGV:画像からカメラの3次元位置・姿勢を推定するライ...
VGGT:マルチビュー・フィードフォワード型3Dビジョン基盤...
UnityでPoint Cloudを表示する方法
頭蓋骨からの顔復元と進化過程の可視化
OpenCVでカメラ画像から自己位置認識 (Visual O...
PSPNet (Pyramid Scene Parsing ...
全脳アーキテクチャ勉強会
C++ 標準テンプレートライブラリ (STL)
ManuelBastioniLAB:人体モデリングできるBl...
Quartus II
書籍『仕事ではじめる機械学習』を読みました
Webサイトのワイヤーフレームが作成できるオンラインツール
Theia:オープンソースのStructure from M...
OpenCV 3.1から追加されたSfMモジュール
Amazon Web ServicesでWordPress


コメント