Google I/Oでの発表に合わせて、TensorFlowのネットワークでCG Rendererを扱うためのライブラリ TensorFlow Graphicsが公開された。最近の3DCG系のディープラーニングでよく聞く「微分可能なRenderer」を実装している。
Apache 2.0 Licenseだそうです。
TensorFlow Graphics
ここ数年、微分可能なグラフィックレイヤーの新規手法が続々と登場し、ニューラルネットワークのアーキテクチャに組み込めるようになりました。空間の変換から微分可能なグラフィックスレンダリングまで、これらの新しいレイヤーによって、長年のコンピュータービジョン・グラフィックス研究の知見を活用した効率的な新しいネットワークアーキテクチャを構築できます。
幾何学的な事前情報と制約を明示的にニューラルネットワークとしてモデル化できれば、self-supervisedな方法でより効率的にロバストで重要度の高い要素を学習できるアーキテクチャを実現する第一歩となります。
Overview
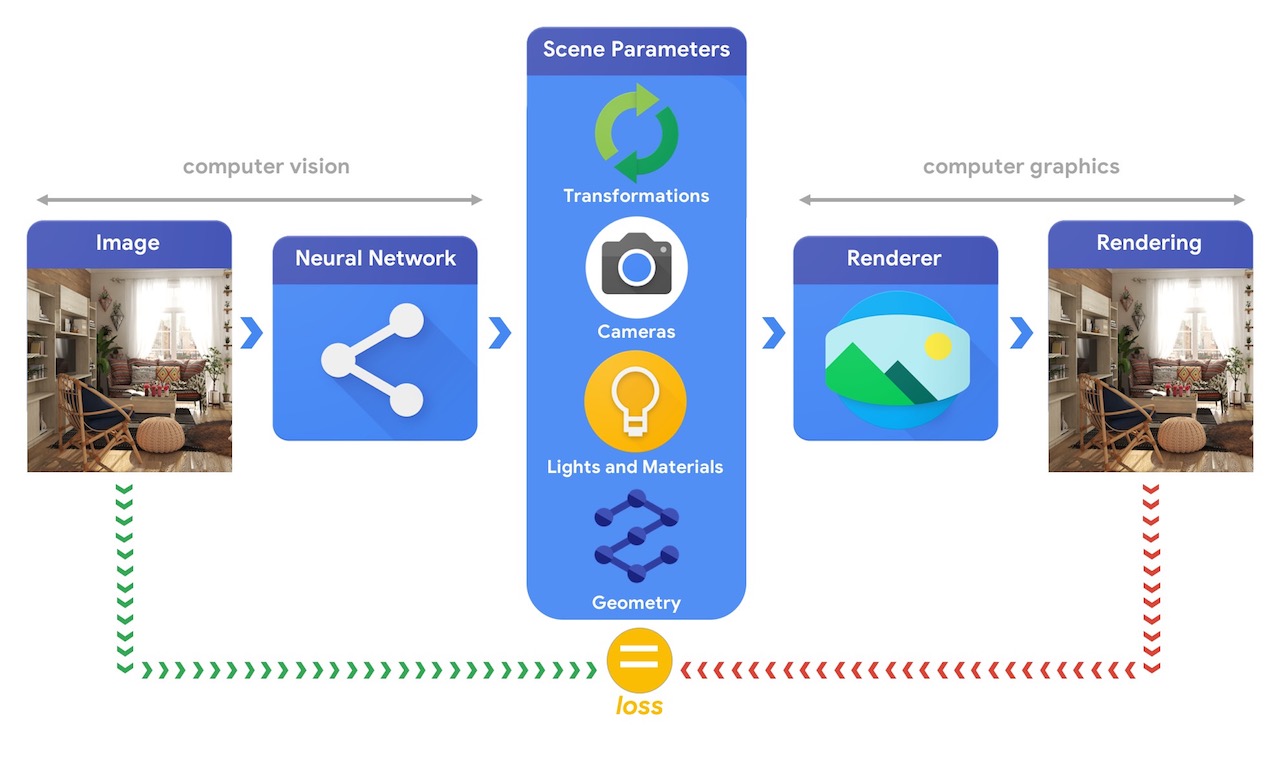
大まかに捉えると、コンピュータグラフィックスのパイプラインでは、まずは3Dオブジェクトを表す情報やそのオブジェクトのあるシーンについて記述した情報(Scene Parameters)が必要となります。位置座標、オブジェクトの素材を表す質感、ライト、カメラといった情報です。
そして、Rendererがシーンの情報を解釈してRenderering画像を生成します。
それに対して、コンピュータービジョンのシステムでは、画像からシーンのパラメータの推測を試みます。シーン内にあるオブジェクトは何か、どのような素材で構成されているのか、それらオブジェクトの3次元位置・方向などを予測するのです。
機械学習を使えばこのように複雑な3D Visionタスクを解決できますが、そのためには大量の学習データが必要です。データのラベル付けプロセスは複雑で費用がかかるため、教師なしで三次元の世界を学習できるモデルを設計する手段があれば大きな価値を持ちます。
コンピュータービジョンとコンピュータグラフィックスの技術を組み合わせれば、ラベル付けされていない膨大なデータも活用することができます。
例えば以下の図のように、コンピュータービジョンで画像からシーンのパラメータを推測し、そのパラメータに基づいてコンピューターグラフィックスで画像をレンダリングして分析するのです。レンダリング画像が元の画像と一致するなら、コンピュータービジョンでシーンパラメータを正確に推測できていると評価できます。この構成ではコンピュータービジョンとコンピュータグラフィックスが密接に関連しており、AutoEncoderのようにself-supervisedで学習できる1つの機械学習システムとして完結しています。
TensorFlow Graphicsは、こういった課題への取り組みの支援と実現のために開発されています。TensorFlow Graphicsは、一連の微分可能なグラフィックス・ジオメトリ(例:カメラ、反射モデル、空間の変換、メッシュの畳み込みなど)のレイヤーと、機械学習モデルの学習・デバックに利用できる3Dのビューア(3D TensorBoard)を提供します。
すでにGoogle Colaboratoryで試せるチュートリアルも公開されている↓
https://colab.research.google.com/github/tensorflow/graphics/
Google I/OでのTensorFlow Graphics発表の動画はこちら↓
動画自体は長いけど、TensorFlow Graphicsの部分だけなら実質10分ぐらい。
TensorFlow Graphicsに実装されているDifferentiable Graphics Layerについてはこちらの記事で解説されている↓
https://medium.com/tensorflow/introducing-tensorflow-graphics-computer-graphics-meets-deep-learning-c8e3877b7668
Differentiable Graphics Layers
以下に、TensorFlow Graphicsで利用可能な機能を紹介します。
ここで紹介するのはTensorFlow Graphicsのごく一部です。TensorFlow Graphicsで利用可能な機能についてより多くの情報はGithubをご覧ください。
Transformations
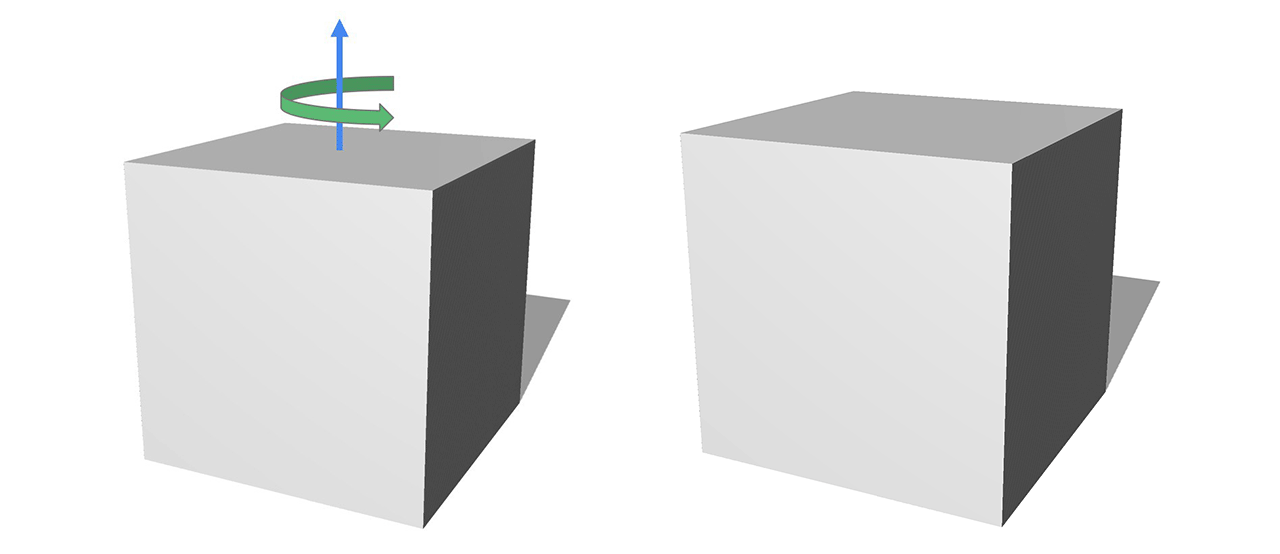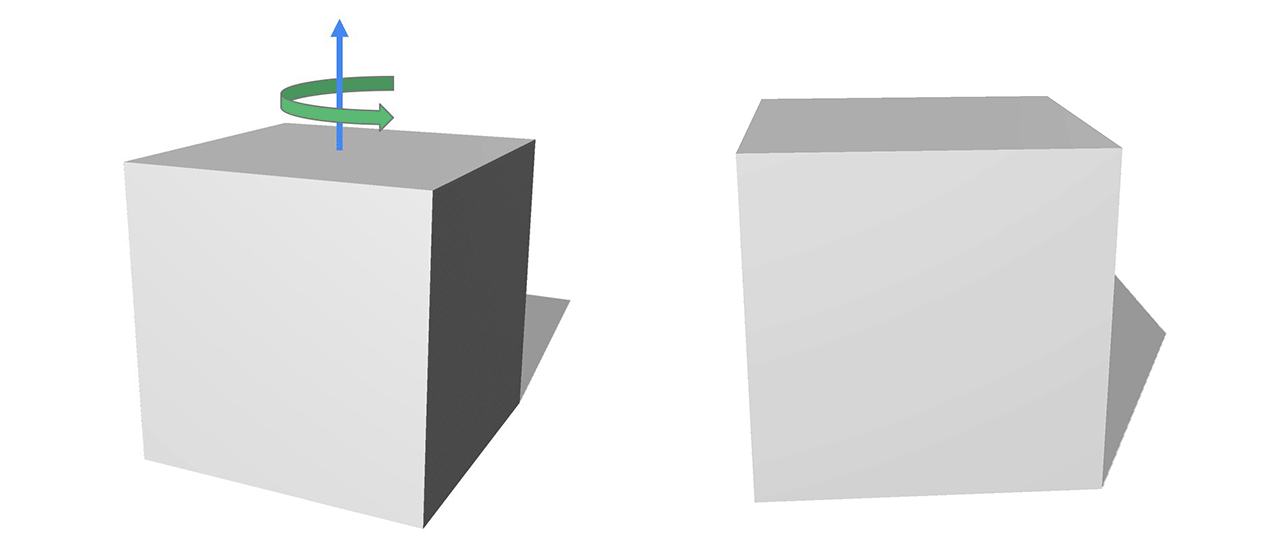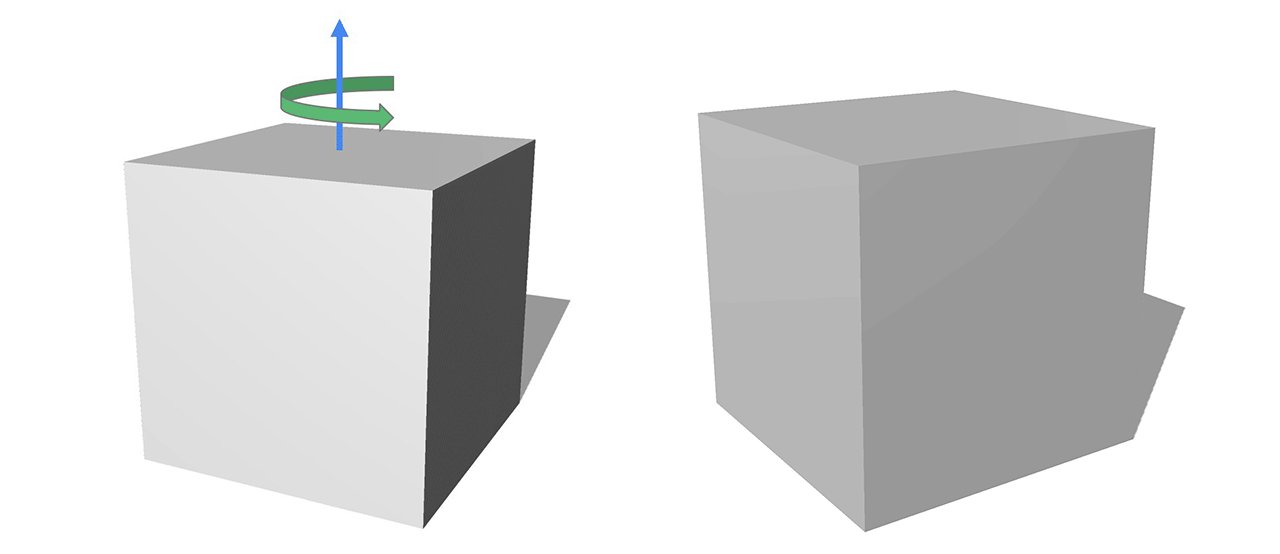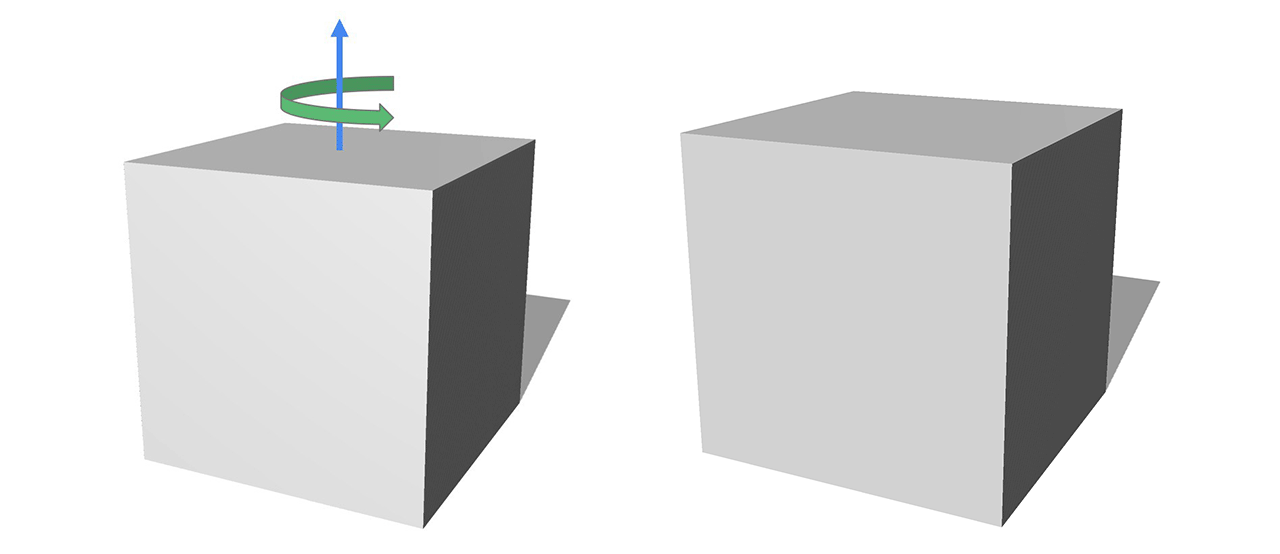
オブジェクトのTransformationは、空間内のオブジェクトの位置を制御します。以下の図では、axis-angle(軸の角度)の形式を使ってCubeを回転させています。回転軸を上向き、角度を正にすると、Cubeは反時計回りに回転します。
このColabのサンプルでは、回転をニューラルネットワークで学習する方法を示しています。ニューラルネットワークはオブジェクトの回転・並進移動の推定できるよう学習します。
このタスクは、環境との相互に作用するロボットなど、多くのアプリケーションの基本となるものです。こういったシナリオでは、ロボットアームで物体を掴むために物体の位置を正確に推定する必要があります。
Modelling cameras
Camera modelsは三次元の物体を画像平面上に投影し、画像の外観に大きく影響します。そのため、コンピュータービジョンにおいて重要な役割を持ちます。
以下の図では、Cubeが拡大・縮小しているように見えますが、実際にはカメラの焦点距離を変化させているだけです。Camera modelsについての詳細とTensorFlowでの使用方法については、このColabサンプルをお試しください。
Materials
Materialモデルは、オブジェクトに光が当たった時の見た目の質感を与える方法を定義します。例えば、石膏などは光を全方向に均一に反射しますが、鏡などは鋭く鏡面反射します。
このColabサンプルでは、TensorFlow Graphicsで以下のようなレンダリングを行う方法を学べます。Materialとライトのパラメータをどのように操作すれば良いシーンに仕上がるのか理解できるはずです。
正確なMaterial推定は、多くのタスクに不可欠なものです。例えば、Materialが正確に推定できると、ユーザーが自分の部屋にバーチャルな家具を配置して、実際の部屋に置いた際の見た目を確認することができます。
Geometry — 3D convolutions and pooling
近年、スマートフォンのDepthセンサーや自動運転車のLidarなど、点群やMesh形式の3Dデータを出力するセンサー達が我々の生活の一部となりつつあります。点群やMeshなどの不規則な構造のデータの畳み込み処理を実装するのは、規則的なグリッド構造を持つ画像データよりもかなり難しいものです。
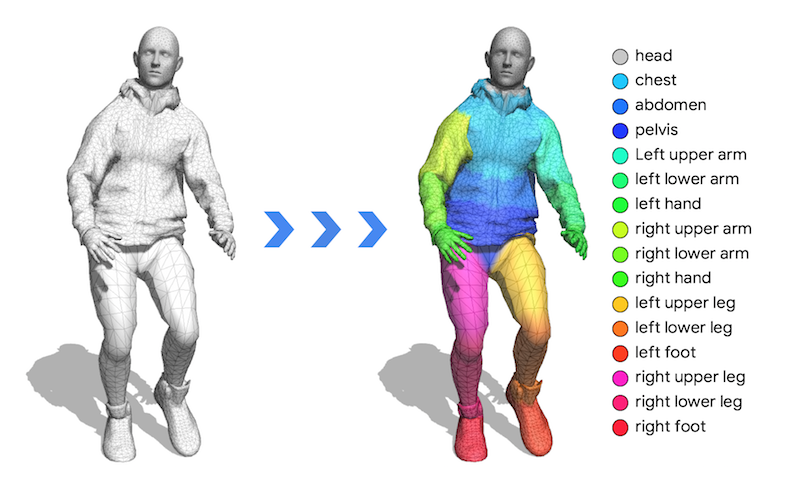
TensorFlow Graphicsには、2つの3D畳み込み層と1つの3D pool層が実装されています。これを使うと、以下の図のようにネットワークを学習してMeshのsemantic part classificationを行うことができます。こちらのColabサンプルで試すことができます。


そろそろ微分可能なRendererについて知りたかったから、これをいじりながら勉強してみるか。(ここ最近はTensorFlowからPyTorch派になりつつありましたが)
この発想、CGでかなり写実的なレンダリングが可能な時代だからこそだよね。これ、反射照明モデルが充実していればInverse Rendereringが一気に実現できそうなフレームワークな気がする。
物体のラベルや姿勢推定に関しては、現実世界と同等程度に物体のCGモデルが存在することが前提のような気も。。。
http://ai-scholar.tech/treatise/renderer-ai-215/
http://blog.abars.biz/archives/52467066.html


コメント