
GAN, DCGAN, CGAN, Pix2Pixに引き続きGAN手法のお勉強。


Pix2Pixからだいぶ時間が空いてしまったけど、次はCycleGANについて。
CycleGAN
CycleGANはICCV 2017で発表された論文 Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networksで提案されたGANによる画像変換手法。
馬をシマウマに変換したこちらの衝撃的な動画が有名ですね↓
Pix2Pixは画像変換の入力画像、出力画像に相当する2つの画像の対応関係を学習することで変換アルゴリズムを獲得できるが、その学習には1対1で対応したペア画像データが大量に必要だった。しかし、1対1で各ピクセルが対応したペア画像データを大量に入手できるケースは稀で、Pix2Pixのために新たに学習データを用意するコストが課題として残されていた。
CycleGANは、2枚の画像の対応する各ピクセルの関係を学習するのではなく、2つの画像データセット同士のdomain(分野、領域)の関係を学習して画像変換を実現する手法。
これによって、CycleGANは大量のペア画像を用意しなくても、2つの違う画像データセットからその関係を学習して画像変換アルゴリズムを獲得できる。
画像データセットのdomainとは?
“domain“とはやや抽象的な概念だが、集合論的に考えると、機械学習用に公開されている各画像データセットはそれぞれ固有のdomainで収集された画像の集合と捉えることができる。(というかsetって集合って意味だよな)
例えば、一般物体認識用にラベル付けされたImageNetなどの画像データセットで考えると、「馬」とラベル付けされた画像は「馬domainの画像データセット」、「シマウマ」とラベル付けされた画像は「シマウマdomainの画像データセット」と見なすことができる。
CycleGANでは、domainの違う2つの画像データセット間に何らかの関係があると仮定し、domain間の対応関係を学習する。
CycleGANの基本構造
CycleGANは、domainの違う2つの画像データセット間の関係を学習するために、以下の図のように2組のGeneratorとDiscriminatorを使った変換と逆変換の循環(cycle)構造になっている↓
G:domain X→domain Yの画像変換Generator
DX:domain Xの画像か識別するDiscriminator
X:domain Xの画像群
x data:domain Xの実画像
x fake:Fが生成した偽のdomain Xの画像F(y)F:domain Y→domain Xの画像変換Generator
DY:domain Yの画像か識別するDiscriminator
Y:domain Yの画像群
y data:domain Yの実画像
y fake:Gが生成した偽のdomain Yの画像G(x)
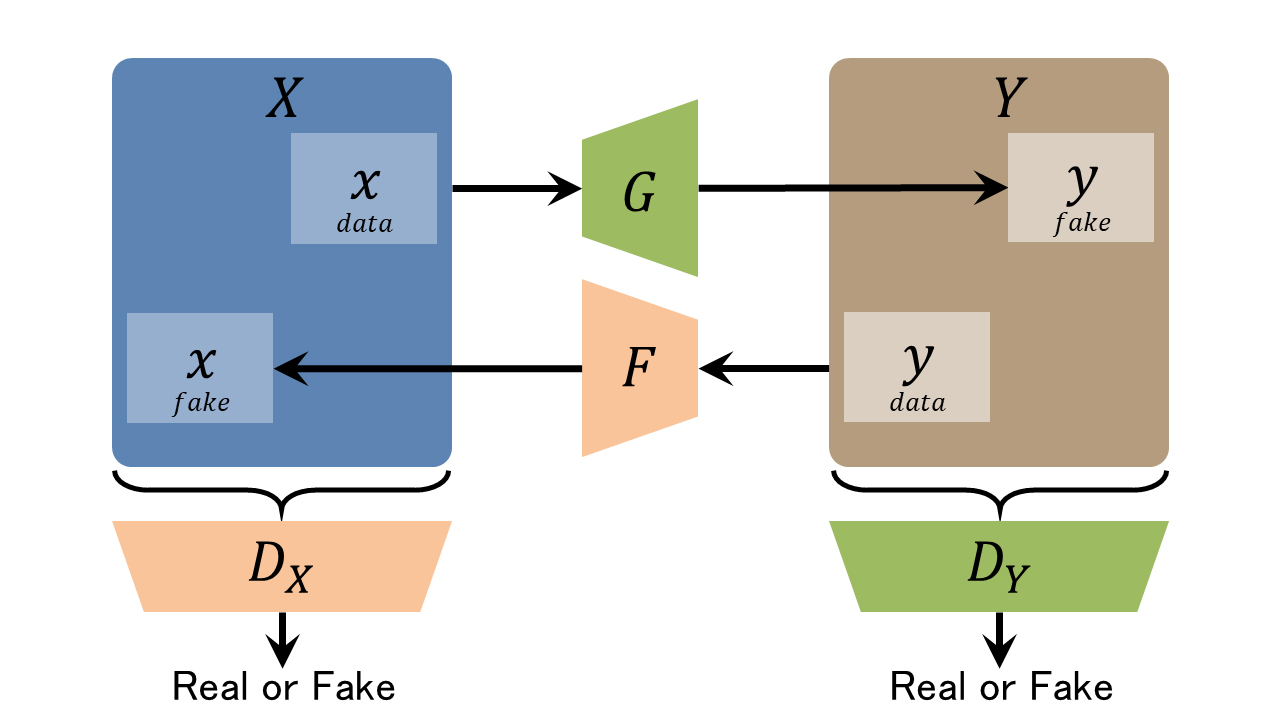
GeneratorとDiscriminatorが2組あるが、それぞれの組は通常のGANと同様に、GeneratorはDiscriminatorを騙すように学習し、DiscriminatorはGeneratorの嘘を見破るように学習する。
学習データとして2種類の画像データセット domain X, domain Yがある場合、
Generator Gはdomain Xの画像xをdomain Yの画像yへ変換し、Discriminator DYは画像yが本物のdomain Yの画像かどうかを識別する。
Generator Fはdomain Yの画像yをdomain Xの画像xへ変換し、Discriminator DXは画像xが本物のdomain Xの画像かどうかを識別する。
Pix2Pixのように1組のGeneratorとDiscriminatorで一方向の変換(生成)だけを学習する場合、入力xを出力yへ変換する関係を習得することはできるが、yからxへの逆変換も成立する関係を習得することができない。
そこで、CycleGANではGeneratorとDiscriminatorをもう1組加え、出力yから入力xへの逆変換の学習も行い、双方向の変換を保証するdomain間の関係を学習する。
定式化
通常のGANのセオリ―に則り、GeneratorとDiscriminatorの組はそれぞれAdversarial Lossで学習する。
よって、domain Xの画像xをdomain Yの画像yへ変換するGenerator Gと、その変換結果を識別するDiscriminator DYの関係は以下の式となり↓
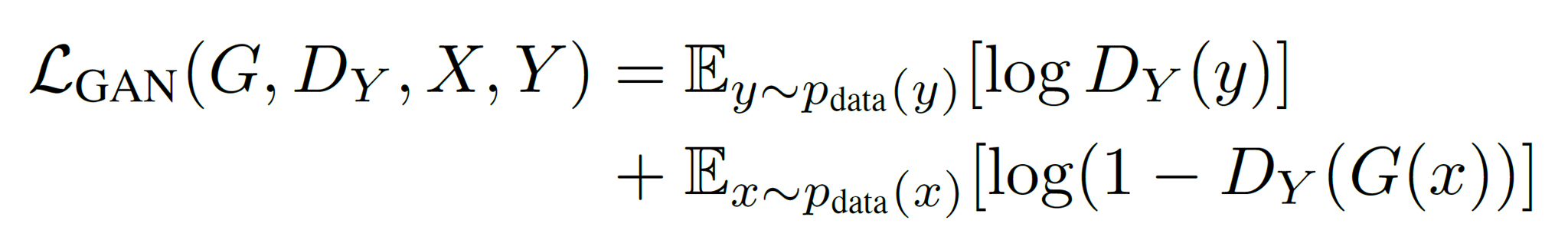
このGeneratorとDisicriminatorの組の学習の目的はこの式のGを最小化、DYを最大化すること↓
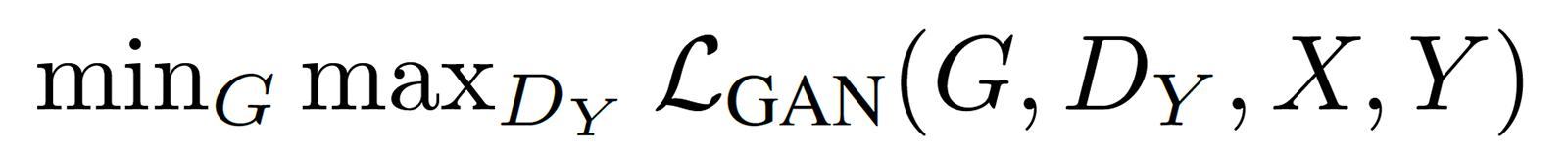
同様にdomain Yの画像yをdomain Xの画像xへ変換するGenerator Fと、その変換結果を識別するDiscriminator DXの学習の目的は以下↓

Cycle Consistency Loss
通常のGANの目的関数だけでは、変換(Generator G)と逆変換(Generator F)の学習がそれぞれ独立したままで、相互変換の学習が上手く収束しない。
変換と逆変換を繰り返す循環での一貫性を保つ関係を学習するために、CycleGANではCycle Consistency Lossという新たな損失関数が導入されている。
Cycle Consistency Lossは、変換と逆変換を経て「画像がどれだけ変換前に戻ったか?」の一貫性(Consistency)を測る指標として、GとFの関係を表す↓
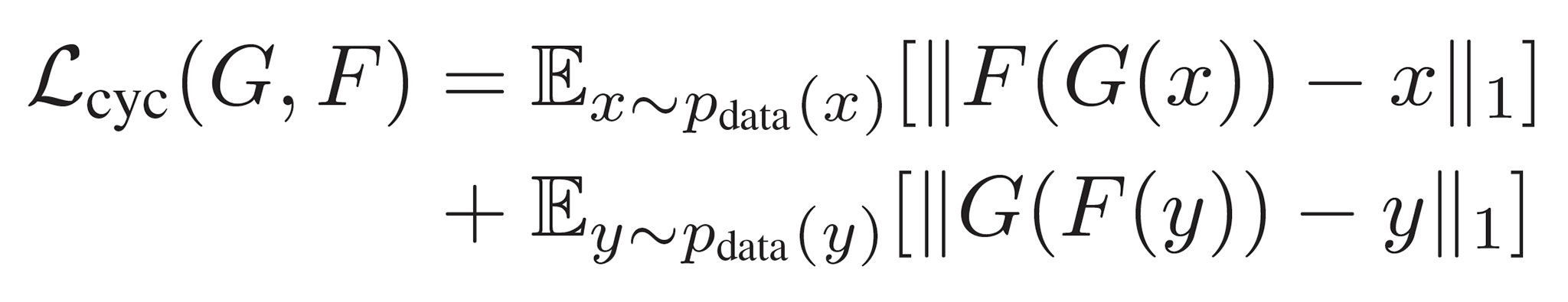
ここまで出てきた式を1つにまとめると以下のようになる↓
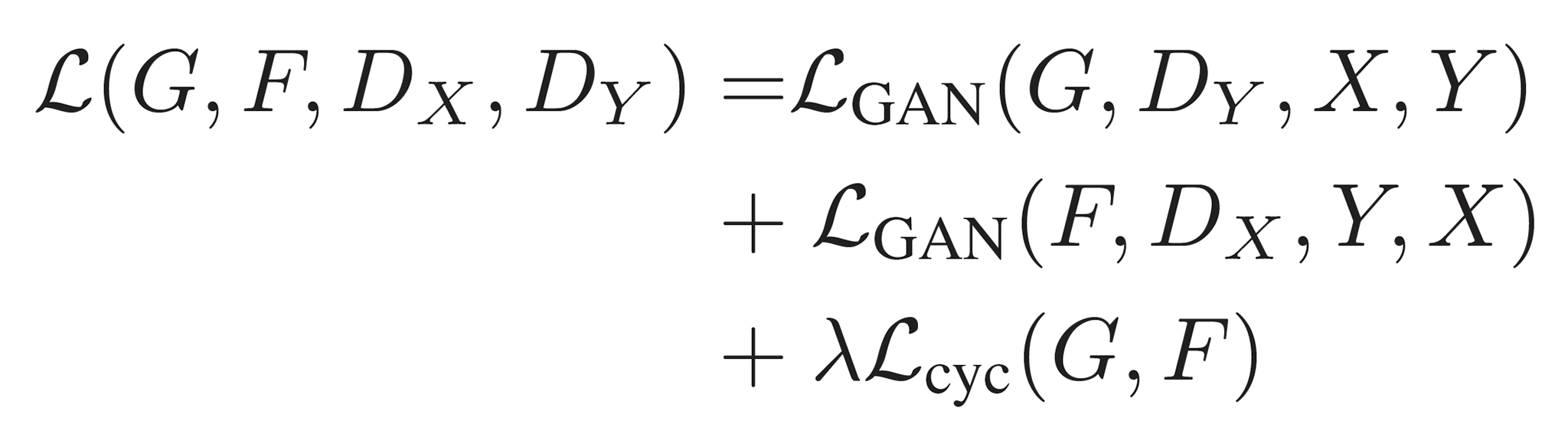
ここでCycle Consistency Lossにかかっているλは、Adversarial LossとCycle Consistency Lossの相対的な重要度を制御する重み変数。
ということで、CycleGANの学習で目指すのは最終的に以下のようになる↓
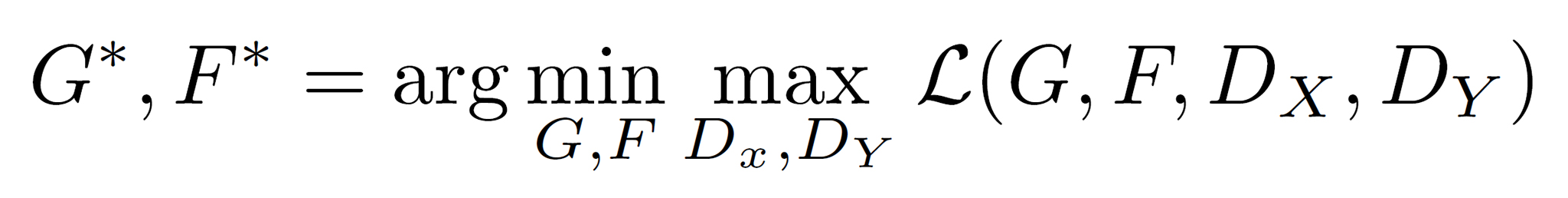
CycleGANのネットワーク
CycleGANのネットワークの実装は、Perceptual Losses for Real-Time Style Transfer and Super-Resolutionのビルディングブロックを踏襲して、stride 2の畳み込み層2つ、residualブロック、stride 1/2のfractionally strided convolution 2つで構成。128×128の画像に対しては 6 ブロック、256×256以上の画像の学習には 9ブロック使い、Instance Normalizationを使用する。
DiscriminatorにはPix2Pixと同じようにPatchGANを採用している。(ここでは70×70のPatchGANを使用)
CycleGANの実験結果
以下の図のようにCycleGANでは、馬とシマウマの画像データセットを学習して画像内の馬のポーズを保ったままシマウマに変換したり、絵画(モネ)と風景写真のデータセットを学習して絵画と風景写真の変換が可能となる。

論文では、Pix2Pixと同様に実験結果に対してAMT(Amazon Mechanical Turk)による知覚評価とFCN Scoreによる評価を行っている。
CycleGANでの失敗例
CycleGANでは、似た形状や同じポーズ、似た構図での色・テクスチャの変換をキレイに行うことができるが、犬の画像を猫の画像へ変換するような、形状の違うデータセット間の変換では失敗してしまう場合が多い↓

CycleGANの実装
公式にCycleGANのPyTorch実装が(Pix2Pixの実装と一緒に)公開されている↓
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
ICCV 2017での発表動画
ICCV 2017でのCycleGANの発表の様子がYouTubeで公開されている↓
今回CycleGANの論文を読むにあたって、最近話題のDeepL翻訳も使ってみた。自然な日本語になる代わりに、上手く訳せない部分がサラッと省略されてしまうこともあるので、論理構造はよく分からなくなってしまうな。CycleGANの論文は文章中に数式も入ってるし。
さて、次はどの手法を勉強しようか。
金森先生のこちらの資料をガイドにして勉強を進めようか↓
動画生成、再照明、3D復元と面白そうな分野が色々あるけど、もう少し画像生成系の論文を読んでみようかな。
次はPGGAN (Progressive Growing GAN)を勉強しよう↓

関連記事
ディープラーニング
映画『シン・仮面ライダー』 メイキング情報まとめ
ZBrush 2021.6のMesh from Mask機能...
フルCGのウルトラマン!?
書籍『The Art of Mystical Beasts』...
映画『ジュラシック・ワールド/炎の王国』のVFXブレイクダウ...
GAN (Generative Adversarial Ne...
Fast R-CNN:ディープラーニングによる一般物体検出手...
trimesh:PythonでポリゴンMeshを扱うライブラ...
ZBrushでアヴァン・ガメラを作ってみる 脚のポーズ調整
ラクガキの立体化 目標設定
UnrealCLR:Unreal Engineで.NET C...
PolyPaint
株式会社ヘキサドライブの研究室ページ
TorchStudio:PyTorchのための統合開発環境と...
Webスクレイピングの勉強会に行ってきた
ZBrushでアヴァン・ガメラを作ってみる 全体のバランス調...
Unityで360度ステレオVR動画を作る
2020年12月 振り返り
ジュラシック・パークのメイキング
画像生成AI Stable Diffusionで遊ぶ
Raspberry Pi 2のGPIOピン配置
Kinect for Windows v2の日本価格決定
ManuelBastioniLAB:人体モデリングできるBl...
Regard3D:オープンソースのStructure fro...
Mechanizeで要認証Webサイトをスクレイピング
ZBrushでアヴァン・ガメラを作ってみる 下アゴと頭部を作...
Pythonの自然言語処理ライブラリ『NLTK(Natura...
ZBrushのZScript入門
Python拡張モジュールのWindows用インストーラー配...
ゴジラ三昧
OpenCVで顔のモーフィングを実装する
Raspberry Pi
ZBrushのハードサーフェイス用ブラシ
OpenCVのバージョン3が正式リリースされたぞ
Kinect for Windows V2のプレオーダー開始
OpenMVSのサンプルを動かしてみる
ZBrush 2018での作業環境を整える
ZBrushでアヴァン・ガメラを作ってみる 甲羅の修正・脚の...
フリーで使えるスカルプト系モデリングツール『Sculptri...
Model View Controller
映画から想像するVR・AR時代のGUIデザイン


コメント