
GAN, DCGANに引き続きGAN手法のお勉強。


次はCGAN (Conditional GAN)を勉強しよう。
日本語で言うと「条件付き敵対的生成ネットワーク」といったところでしょうか。
CGAN (Conditional GAN)
CGAN (Conditional GAN)は2014年にarXivで公開された論文 Conditional Generative Adversarial Netsで提案された生成手法。arXivで公開されただけで、学会発表はしていないようです。中身も割とあっさりした論文。学会発表されていない論文が後に引用される時代か。
CGANは以下の図のように、Generator, DiscriminatorによるGANの基本構造を踏襲しつつ、条件を与えられるように拡張されている↓
G:Generator
D:Discriminatorz:ノイズベクトル
y:条件ベクトル
x:本物のデータ (学習データ)
G(z):Generatorが生成した偽のデータ
オリジナルのGANとCGANの大きな違いは、Generatorの入力にノイズベクトルだけでなく、条件ベクトルも与えている点。それに伴い、Discriminatorも条件ベクトルに相当する条件データを入力できるよう改良されている。
CGANの目的関数
そのため、CGANの目的関数は以下の式のように、GANの目的関数に条件ベクトルyを加えた形になる↓
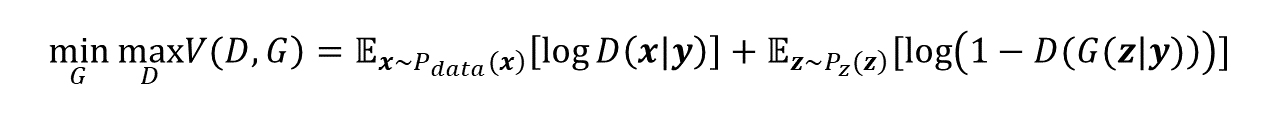
ノイズだけでなく、条件の情報を入力することで、CGANは特定の条件のデータを生成できるようになっている。ここで「条件」として使用する情報はほとんどの場合クラスラベルや文章などですが、他にもあらゆる情報を想定できるそうです。(Pix2Pixは条件に画像を使ったCGANです)
Generatorの入力
通常のGANのGeneratorの入力をn桁のノイズベクトルだとすると、CGANの入力は、n桁のノイズベクトルに条件ベクトル分の桁を結合したベクトルとなる。
つまり、ノイズベクトルの要素が100個、条件ベクトルの要素が10個だとすると、110個の要素を持つベクトルがGeneratorの入力となる。
条件ベクトルはone-hot表現のベクトルとして与える。
例えば0~9までの数字画像を生成する場合、4という数字を表す条件ベクトルは [0, 0, 0, 0, 1, 0, 0, 0, 0, 0]となる。
Discriminatorの入力
通常、GANのDiscriminatorの入力はwidth × heightの実データ(画像)または生成データ(画像)だけだが、CGANではデータ生成時の条件も入力する。
しかし、実装上DiscriminatorにはGeneratorのように条件ベクトルをそのまま入力することができないため、条件をwidth × heightのデータ(画像)として入力する。これは、Generatorに入力するone-hot表現の条件ベクトルの各要素をそれぞれ1枚の条件画像に変換するということ。(条件数分チャンネルを持った1枚の画像とも言えますが)
例えば、0~9までの数字を条件とする場合は10枚の条件画像を用意することになる。この場合、4という数字に相当する5枚目の条件画像のピクセル値は全て1で埋める。
CGANの学習
CGANも通常のGANの考え方に則り、GeneratorとDiscriminatorを競わせるように学習する。
CGANの学習ステップは通常のGANとほぼ同様なので割愛。
MNISTデータセットを用いた実験
MNISTデータセットを使い、数字のラベルを条件として使用した実験結果↓

Generatorの入力となる条件ベクトルが数字の指定、ノイズベクトルが同じ数字のバリエーションを生成するパラメータとして機能している。
ちなみに、CGANもDCGANのようにネットワークを畳み込み層で構成すると、DCGANと同様に高品質な画像を特定の条件で生成できるようになる。これはCDCGAN (Conditional DCGAN)と呼ばれたりもする。ネットでCGANの実装例を探すと、むしろCDCGANの実装例の方が多い気がする。
この他、論文ではFlickrの画像データを用いてタグ情報を条件に使用した実験も行っている。
CGANの実装
これをフォークして自分で実装を試してみてるけど、まだ実装途中です。。。
https://github.com/NegativeMind/Pytorch-conditional-GANs
PyTorchでの実装例はCDCGANのサンプルばかりで、純粋なCGANの良い例が見つけられない。。。
次はいよいよPix2Pix。

Pix2Pix以降はこれに従って順に勉強していこう↓
関連記事
FreeMoCap Project:オープンソースのマーカー...
WordPressで数式を扱う
openMVG:複数視点画像から3次元形状を復元するライブラ...
ArUco:OpenCVベースのコンパクトなARライブラリ
PSPNet (Pyramid Scene Parsing ...
第25回コンピュータビジョン勉強会@関東に行って来た
OpenCV 3.3.0-RCでsfmモジュールをビルド
Rerun:マルチモーダルデータの可視化アプリとSDK
OpenSfM:PythonのStructure from ...
Qlone:スマホのカメラで3Dスキャンできるアプリ
NeRF (Neural Radiance Fields):...
Googleが画像解析旅行ガイドアプリのJetpac社を買収
VGGT:マルチビュー・フィードフォワード型3Dビジョン基盤...
openMVGをWindows10 Visual Studi...
LLM Visualization:大規模言語モデルの可視化
CycleGAN:ドメイン関係を学習した画像変換
OpenGV:画像からカメラの3次元位置・姿勢を推定するライ...
Connected Papers:関連研究をグラフで視覚的に...
Composition Rendering:Blenderに...
Point Cloud Libraryに動画フォーマットが追...
書籍『仕事ではじめる機械学習』を読みました
Houdiniのライセンスの種類
OpenCVで顔のランドマークを検出する『Facemark ...
KelpNet:C#で使える可読性重視のディープラーニングラ...
R-CNN (Regions with CNN featur...
書籍『3次元コンピュータビジョン計算ハンドブック』を購入
C#で使える遺伝的アルゴリズムライブラリ『GeneticSh...
OpenCVで顔のモーフィングを実装する
SDカードサイズのコンピューター『Intel Edison』
PCA (主成分分析)
Leap MotionでMaya上のオブジェクトを操作できる...
GAN (Generative Adversarial Ne...
Digital Emily Project:人間の顔をそっく...
Pylearn2:ディープラーニングに対応したPythonの...
AnacondaとTensorFlowをインストールしてVi...
OpenCVで動画の手ぶれ補正
DensePose:画像中の人物表面のUV座標を推定する
Caffe:読みやすくて高速なディープラーニングのフレームワ...
YOLO (You Only Look Once):ディープ...
写真から3Dメッシュの生成・編集ができる無料ツール『Auto...
Point Cloud Consortiumのセミナー「3D...
UnityでOpenCVを使うには?


コメント