FCN, SegNetに引き続きディープラーニングによるSemantic Segmentation手法のお勉強。

次はU-Netについて。
U-Net
U-Netは、MICCAI (Medical Image Computing and Computer-Assisted Intervention) 2015で発表されたU-Net: Convolutional Networks for Biomedical Image Segmentationで提案されたSemantic Segmentation手法。(学会に採択されたタイミングで言うとSegNetよりも先ということか?)
学会名や論文タイトルからも分かる通り、医用画像のSegmentationを目的とした研究です。(例にHeLa細胞の画像とかが出てくる)
U-Netは2015年の ISBI (IEEE International Symposium on Biomedical Imaging)でDental X-Ray Image Segmentation ChallengeとCell Tracking Challengeの2部門で優勝している。
著者による概要動画も公開されている↓
U-Netのネットワーク構造
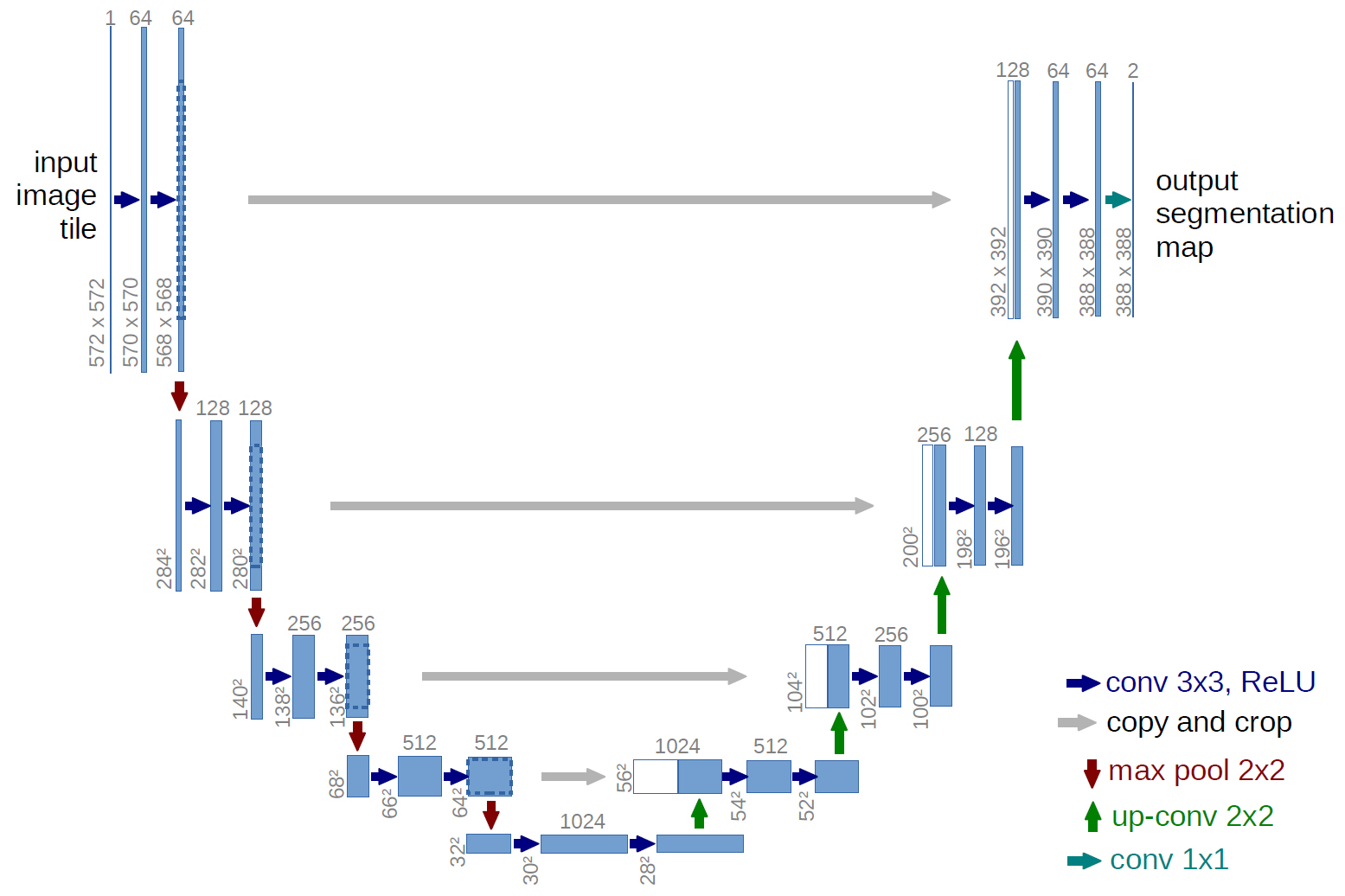
以下がU-Netのネットワーク図。ネットワーク構造がU字に見えるからU-Netと呼ぶらしい↓
青ボックス:画像、特徴マップ
白ボックス:コピーされた特徴マップ
ボックスの上の数字:チャンネル数
ボックスの左下の数字:縦横のサイズ青矢印:kernel size 3×3, padding0の畳み込み、ReLU
グレー矢印:特徴マップのコピーをクロップ
赤矢印:kernel size 2×2のmax-pooling
緑矢印:kernel size 2×2、stride2の逆畳み込み
青緑矢印:kernel size 1×1の畳み込み
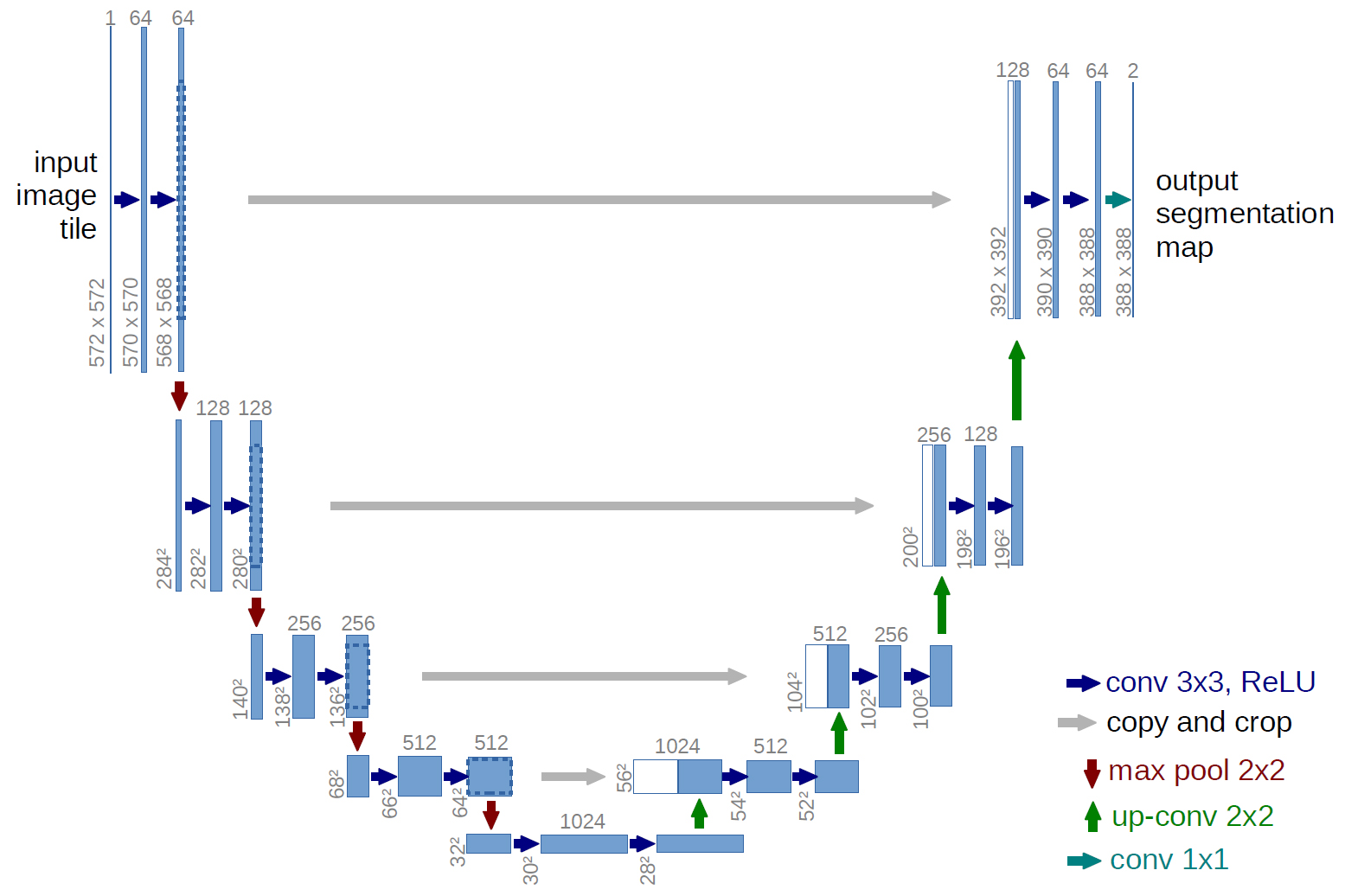
※このネットワーク図では具体例として入力画像と特徴マップのサイズも記載されているが、U-Netは全結合層を持たないため、入力画像サイズを固定する必要はない。
この論文では細胞と背景のセグメンテーションが目的なので出力は2チャンネル(2クラス分類)。
Encoder-Decoder構造
U-NetもFCNやSegNetと同様に全結合層を持たず、畳み込み層で構成されている。U-NetもSegNetのようにほぼ左右対称のEncoder–Decoder構造で、Encoderのpoolingを経てダウンサンプリングされた特徴マップをDecoderでアップサンプリングしていく。
U-NetとSegNetの大きな違いは、Encoderの各層で出力される特徴マップをDecoderの対応する各層の特徴マップに連結(concatenation)するアプローチを導入した点。このアプローチはスキップ接続と呼ばれているみたいですね。
Encoderの構造はVGGの特徴抽出層とほぼ同様だが、畳み込み時のpaddingが0なため、畳み込み後は特徴マップのサイズは少しだけ小さくなる。(実装ではpaddingしているU-Netも見かけるけど…)
スキップ接続
SegNetでは、EncoderとDecoderが直列に接続されていたため、特徴が伝搬する過程でpixelディティールが失われてしまい、元の画像に対してSegmentation結果が粗くなりやすい欠点があった。
U-Netでは、Encoderの各層で出力される特徴マップを、Decoderの対応する層の特徴マップに直接連結することでpixelのディティールを補っている。
前の層の特徴マップと統合するという点ではFCNのアプローチにも似ているが、FCNでは違う層の特徴マップ同士をチャンネルごとの値の足し算で統合しているのに対し、U-NetではEncoderで出力された特徴マップを別チャンネルとしてDecoderの特徴マップに追加する形で連結している。
Encoderではpadding=0の畳み込みを行って特徴マップが少しずつ小さくなっているため、Decoderで2倍にアップサンプリング(逆畳み込み)してもEncoderの特徴マップとサイズが合わない。
そのため、Encoderの特徴マップの中央部分を切り出し(crop)してDecoderの特徴マップとサイズを一致させて連結している。
※Encoderでpaddingを行えばEncoderとDecoderの特徴マップのサイズが一致するのでそのまま連結することができる。(そういう実装例もある)
論文では電子顕微鏡で撮影された細胞の画像を細胞と背景に分割する2クラスの分類が行われている。また、少ないデータセットで学習するためのData Augmentation方法についても記載されていた。
U-Netはその後改良版のU-Net++というのも発表された。
https://github.com/MrGiovanni/UNetPlusPlus
物体検出のネットワークだと矩形の出力とかで実装が複雑になりがちだけど、畳み込み層のみで構成されたネットワークはそのまま画像が出力される分構造がシンプルで理解しやすい気がする。(学習に委ねる範囲が多いということでもあるのか?)
U-NetはPix2PixのGeneratorのネットワークにも使用されている。

以前線画の自動着色で話題になったPreferred NetworksのPaintsChainerのGeneratorネットワークに使用されているのもU-Net。
https://qiita.com/taizan/items/cf77fd37ec3a0bef5d9d
https://qiita.com/taizan/items/7119e16064cc11500f32
サンプルコード
例のごとくPyTorchの実装を探す。やっぱりpaddingしてるよなぁ。
https://github.com/hszhao/PSPNet
前も言ったけど、U-Netに限らずSemantic Segmentation系のPyTorch実装をひとまとめにしたリポジトリもある↓
https://github.com/meetshah1995/pytorch-semseg
次はPSPNetについて勉強するかな。
関連記事
Windows10でPyTorchをインストールしてVSCo...
Leap MotionでMaya上のオブジェクトを操作できる...
UnityユーザーがUnreal Engineの使い方を学ぶ...
書籍『イラストで学ぶ ディープラーニング』
BlenderでPhotogrammetryできるアドオン
OpenGVのライブラリ構成
機械学習のオープンソースソフトウェアフォーラム『mloss(...
Point Cloud Consortiumのセミナー「3D...
2D→3D復元技術で使われる用語まとめ
OpenCVの顔検出過程を可視化した動画
OpenCVの三角測量関数『cv::triangulatep...
3D Gaussian Splatting:リアルタイム描画...
OpenMVSのサンプルを動かしてみる
CGAN (Conditional GAN):条件付き敵対的...
OpenCV3.3.0でsfmモジュールのビルドに成功!
3D復元技術の情報リンク集
動画で学ぶお絵かき講座『sensei』
Mitsuba 2:オープンソースの物理ベースレンダラ
OpenCV 3.3.0-RCでsfmモジュールをビルド
書籍『OpenCV 3 プログラミングブック』を購入
Accord.NET Framework:C#で使える機械学...
UnityでOpenCVを使うには?
GAN (Generative Adversarial Ne...
Facebookの顔認証技術『DeepFace』
第25回コンピュータビジョン勉強会@関東に行って来た
FreeMoCap Project:オープンソースのマーカー...
represent
Fast R-CNN:ディープラーニングによる一般物体検出手...
Two Minute Papers:先端研究を短時間で紹介す...
R-CNN (Regions with CNN featur...
手を動かしながら学ぶデータマイニング
Kaolin:3Dディープラーニング用のPyTorchライブ...
COLMAP:オープンソースのSfM・MVSツール
第1回 3D勉強会@関東『SLAMチュートリアル大会』
OpenCV バージョン4がリリースされた!
データサイエンティストって何だ?
Structure from Motion (多視点画像から...
VGGT:マルチビュー・フィードフォワード型3Dビジョン基盤...
DensePose:画像中の人物表面のUV座標を推定する
今年もSSII
OpenCV 3.1とopencv_contribモジュール...
TeleSculptor:空撮動画からPhotogramme...
コメント