
個人的に3Dビジョンの基盤モデルの動向に注目している。
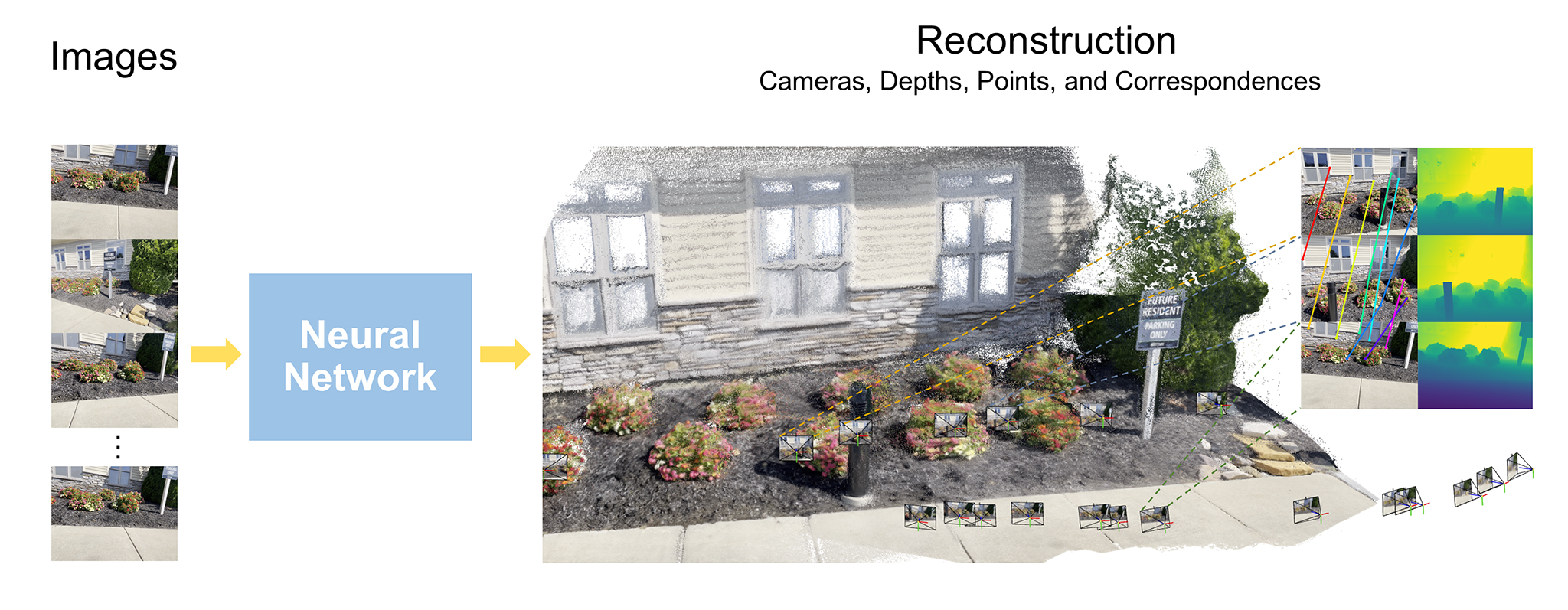
複数枚の画像からシーンの立体構造やカメラ情報を復元する3D Reconstruction(3次元再構成)は、3Dコンピュータービジョンの根幹となる技術。
近年はDUSt3Rのようにディープラーニングによる推論で一気に3次元情報を出力するトップダウンアプローチが登場。AIによる3D空間認識が可能になってきている。

VGGT (Visual Geometry Grounded Transformer)
VGGTは、CVPR 2025で発表された論文VGGT: Visual Geometry Grounded Transformerで提案された3D基盤モデル。
VGGTも、DUSt3Rのようにニューラルネットワークによる推論処理によって3次元情報を推定する。
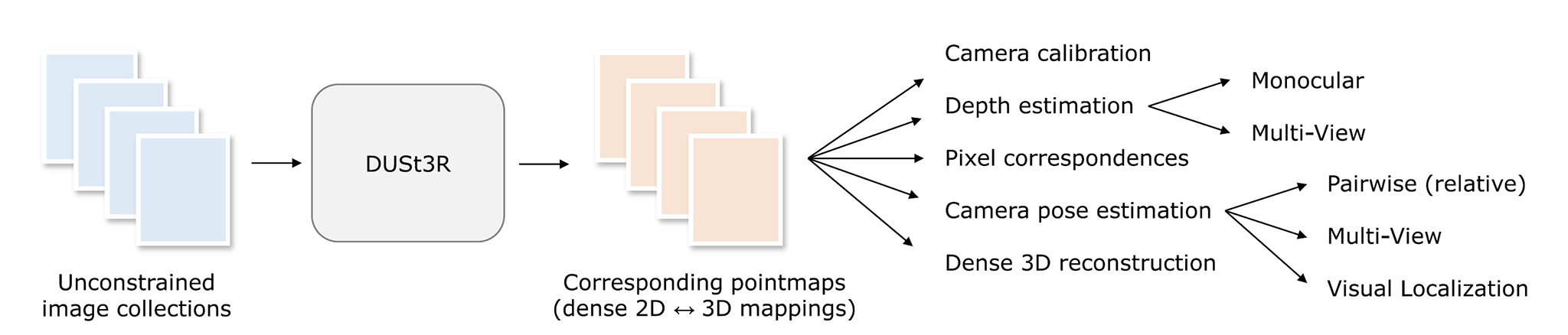
大きな違いは、DUSt3Rのニューラルネットワークが2枚の入力画像からPointmap(各ピクセルの3D位置座標)とConfidence(PointMapの推定信頼度)を推定していたのに対して、VGGTのニューラルネットワークは2枚に限らず100枚を超える画像の同時入力が可能で、PointMapだけでなくDepthMap、Correspondences(各画像間のピクセルの対応関係)、カメラパラメーターを同時に推論できるマルチタスク学習されたネットワーク↓
入力 Images:複数枚のRGB画像 出力 Cameras:Imagesそれぞれに対応するカメラパラメーター Depths:Imagesそれぞれの各ピクセルのDepth値 Points:Imagesそれぞれの各ピクセルの3次元位置座標(1枚目を原点とした同一空間) Correspondences:Imagesそれぞれの画像間の各ピクセルの対応関係
また、DUSt3Rではニューラルネットワークによる推論の後にGlobal Alignmentという反復的な最適化処理を必要としたが、VGGTはニューラルネットワークの推論処理のみで完結する。VGGTは複数枚の画像をまとめてフィードフォワードネットワークに通すだけで結果が得られるため、処理速度が格段に向上した。
VGGTはCVPR 2025のベストペーパーに選ばれた。
VGGTのソースコードはGitHub、学習済みの重みはHugging Faceで公開されており、別途軍事利用を除く商用利用可の学習済み重みも公開されている。
VGGTの仕組みを学びやすいように有志が作成した推論のみのミニマムなコードもある。
VGGTは一般の注目度も高いようで、なぜかGIGAZINEでも紹介されていた。
VGGTの仕組み
VGGTの概要が分かったところで、VGGTの仕組みについて、DUSt3Rとの比較も交えて詳しく見て行こう。
VGGTの設計思想
DUSt3Rの出力はPointMap(と信頼度)のみだった。出力されたPointMapを材料に、後処理で既存の3D幾何計算手法を使ってDepthMap、ピクセルの対応関係、カメラパラメーターを算出するのがDUSt3Rのアプローチ↓
一方VGGTは、「3D幾何計算を後処理に任せず、全てニューラルネットワークに推論させる」というアプローチ。そのためVGGTは、PointMapに限らず、DepthMap、画像間のピクセルの対応関係、カメラパラメーターを全て1つのフィードフォワードネットワークで推論できるようマルチタスク学習されている。
VGGTのこのアプローチは一見冗長な設計にも思える。DUSt3Rのアプローチで分かるように、カメラパラメーターはPointMapからPnP(Perspective-n-Point)問題を解くことで算出できるし、DepthMapもPointMapとカメラパラメーターを使って算出できる。
しかし、これらを明示的に別々に予測するようニューラルネットワークを学習した方が、精度の高い推論結果が得られると実験で示されている。これは、PointMapを直接予測させるよりも、より単純なサブタスク(カメラパラメーター、DepthMap)に分解して学習することの利点と考えられる。
VGGTのネットワーク構造
VGGTもTransformerベースのネットワーク。特徴抽出バックボーンにはDINOv2が使用されている↓

VGGTのネットワークは、大まかに以下のような役割で構成されている。
- パッチ化された入力画像から、DINOv2による特徴抽出(特徴量トークン化)
- 各画像ごとに以下2種類の補助トークンを追加
- Camera Token
- Register Token
- Alternating Attention:以下2種類のSelf-Attentionを交互にL回適用
- Global Self-Attention
- Frame-wise Self-Attention
- 各種予測Headによる出力
- Camera Head:カメラパラメーター
- DPT Head
- DepthMap(各ピクセルの奥行き)
- PointMap(各ピクセルの3D位置座標)
- Track(画像間の各ピクセルの対応関係)
VGGTのネットワークの各段階ごとの役割について解説。
1. DINOv2による特徴抽出(特徴量トークン化)
VGGTでは、3D専用の特徴抽出器を新たに設計するのではなく、ViT(Vision Transformer)ベースの汎用的な自己教師あり手法であるDINOv2を特徴抽出に利用し、DINOv2で得られた特徴を後段のTransformerで3D的に解釈するという構成を取っている。
入力された複数枚のRGB画像は、まずViTで処理可能なトークン列に変換するためにそれぞれ固定サイズのパッチに分割される。パッチ化された画像はそれぞれ1枚ずつ独立に、事前学習済みのDINOv2を用いて高次元の特徴量トークン列へと変換される。DINOv2は各パッチに対して、周囲の文脈を考慮した特徴表現を出力する。
ここで得られる特徴量トークン列は、単なる局所パッチの情報ではなく、物体境界、領域構造、繰り返しパターンや意味的なまとまりなど、後段のTransformerで対応関係や幾何構造を推論するための手がかりを含んだ表現になっている。
2. 画像ごとに補助トークンを追加
DINOv2によって得られた画像の特徴量トークンに対して、VGGTでは各画像ごとに2種類の補助トークンを追加する。
Camera Token
Camera Tokenは、各画像に1つずつ付与される専用トークンで、画像全体を代表するグローバルな情報を保持するためのもの。このCamera Tokenは後段のCamera Headに入力され、カメラパラメーターの推定に用いられる。
VGGTでは、入力された複数枚画像の1枚目がリファレンス画像として扱われ、2枚目以降の非リファレンス画像とは別種のCamera Tokenが割り当てられる。リファレンス用のCamera Tokenと非リファレンス用Camera Tokenの区別により、Transformer内部でどのCamera Tokenがワールド座標系の基準に対応するか、どの画像が他のすべての視点の参照フレームかが明示的に表現される。
その結果、Camera Tokenを通じて推定されるカメラパラメーターや、後段で得られるPointMapは、全て1枚目の画像を原点とした同一座標系で表現される。
Register Token
Register Tokenは、特定の意味的出力や物理量を表現することを目的としたトークンではなく、直接的な出力には使用されない。
Register Tokenは、Transformer内部で発生する行き場のない情報や一時的な相互作用を吸収するためのバッファとして機能し、どのトークンにも強く帰属しないノイズ的な情報を退避させるゴミ捨て場のような役割を果たす。
3. Alternating Attention
VGGTのTransformerでは、性質の異なる2種類のSelf-Attentionを交互に適用するAlternating Attentionと呼ばれる構成が取られている。Alternating Attentionでは、2種類のSelf-Attention Frame-wise Self-AttentionとGlobal Self-Attentionを交互にL回適用する。論文ではL=24とされている。
Frame-wise Self-Attention
Frame-wise Self-Attentionでは、同一画像に由来するトークン同士のみがAttentionの対象となる。
つまり、画像1枚について、の画像パッチトークン、Camera Token、Register Tokenの間でのみSelf-Attentionが計算される。
Frame-wise Self-Attentionは、画像1枚の内部の空間構造の更新、画像パッチ間の局所的・中距離的な関係の整理、特徴の再構成を行う。
Global Self-Attention
Global Self-Attentionでは、全画像に由来する全てのトークンをまとめてSelf-Attentionの対象とする。
全画像のパッチトークン、(リファレンス用を含む)全Camera Token、全Register Tokenが同一のAttention空間に置かれてSelf-Attentionが計算される。
Global Self-Attentionによって、視点をまたいだ情報の交換、リファレンス画像を基準とした関係付け、画像間の対応関係の形成が行われる。
特に、リファレンス画像に対応するCamera Tokenは、このGlobal Self-Attentionを通じて、他の画像のCamera Tokenや画像パッチトークンと相互作用し、座標系の基準としての情報を伝播する役割を担う。
4. 予測Head
Alternating AttentionをL回適用した後、Transformer内部のトークン表現は、以下のような情報を内包している。
- 画像パッチトークン:視点間の対応関係や奥行き情報を含むピクセル対応の特徴表現
- Camera Token:リファレンス画像を基準とした画像単位の幾何情報
- Register Token:推論過程で生じた不要・中間的な情報
VGGTでは、これらのトークンを用途ごとに2種類の予測Headへ分岐させ、最終的な出力を得る。
Camera Head:カメラパラメーターの推定
Camera Headは、Camera Tokenのみを入力として用いる予測Headで、各画像に対応するCamera Tokenからカメラパラメーターを直接回帰する。
ここで推定されるカメラパラメーターは、入力画像の1枚目のリファレンス画像を原点とした座標系で表現される。
DPT Head:Depth、Point、Trackの推定
DPT Headは画像パッチトークンを入力として用いる密な予測用のHeadで、以下3種類の出力を担当する。
- DepthMap(各ピクセルのDepth)
- PointMap(各ピクセルの3次元位置)
- Tracking / Correspondence(画像間の対応関係を表す特徴量)
DPT Headは、Transformerの最終層だけでなく複数の中間層の特徴を利用し、高解像度な空間構造を復元する構成が取られている。これは、Transformerのレイヤーを深く重ねるにつれて空間分解能が低下し、抽象度が高くなる性質を補うため。
Tracking / Correspondenceは、画像間の対応関係を直接列挙するものではなく、対応関係を復元可能な特徴表現として出力される。
この表現は、多視点間の対応学習、Depth / Point 推定の補助的拘束として利用され、Transformer内部で形成された視点間関係をピクセルレベルに落とし込む役割を担う。
参考資料
コンピュータビジョン最前線が終了してしまったので、日本語の資料はWebだけ。有志による勉強会の発表資料がとても重宝する。
関連記事
日本でMakersは普及するだろうか?
Facebookの顔認証技術『DeepFace』
機械学習での「回帰」とは?
Blendify:コンピュータービジョン向けBlenderラ...
Pylearn2:ディープラーニングに対応したPythonの...
MeshLab:3Dオブジェクトの確認・変換に便利なフリーウ...
OpenCV 3.1とopencv_contribモジュール...
uGUI:Unityの新しいGUI作成システム
ZBrushでアヴァン・ガメラを作ってみる 爪とトゲを追加
タダでRenderManを体験する方法
pythonの機械学習ライブラリ『scikit-learn』
書籍『仕事ではじめる機械学習』を読みました
書籍『イラストで学ぶ ディープラーニング』
ポリ男からMetaHumanを作る
UnityでPoint Cloudを表示する方法
映画『ゴジラ-1.0』 メイキング情報まとめ
今年もSSII
Stanford Bunny
Unreal Engineの薄い本
ZBrushでゴジラ2001を作ってみる 身体のアタリを作る
BlenderProc:Blenderで機械学習用の画像デー...
株式会社ヘキサドライブの研究室ページ
ZBrushでアヴァン・ガメラを作ってみる 口内の微調整・身...
OpenMayaRender
libigl:軽量なジオメトリ処理ライブラリ
geometry3Sharp:Unity C#で使えるポリゴ...
ZBrushでゴジラ2001を作ってみる 頭の概形作り
Mayaのポリゴン分割ツールの進化
OpenCV バージョン4がリリースされた!
機械学習に役立つPythonライブラリ一覧
MLDemos:機械学習について理解するための可視化ツール
ZBrushでアヴァン・ガメラを作ってみる 下アゴと頭部を作...
Blender 2.81でIntel Open Image ...
OpenCV
畳み込みニューラルネットワーク (CNN: Convolut...
iPadをハンディ3Dスキャナにするガジェット『iSense...
CEDEC 3日目
SIGGRAPH論文へのリンクサイト
第25回コンピュータビジョン勉強会@関東に行って来た
映画『シン・仮面ライダー』 メイキング情報まとめ
hloc:SuperGlueで精度を向上させたSfM・Vis...
Siggraph Asia 2009 カンファレンスの詳細

コメント