
R-CNN、Fast R-CNN、Faster R-CNNときて、次はYOLO (You Only Look Once)のアルゴリズムのお勉強。

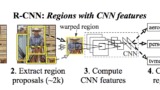
またこちらの系譜図を引用↓
物体検出では認識精度も重要だが、自動運転などの用途ではリアルタイムに近い処理速度が求められる。R-CNNの登場以降、処理速度を重視したYOLO(You Only Look Once)という手法が登場した。
YOLOはEnd-to-Endアプローチの手法の中でも色んな意味で異質な存在。キャラが立っているというか。
YOLO (You Only Look Once)
YOLO (You Only Look Once)はCVPR 2016で発表されたYou Only Look Once: Unified, Real-Time Object Detectionで提案された手法。
ディープラーニング以前の物体検出手法でよく使われていたDeformable Part Modelも含め、YOLO以前の物体検出手法は領域(region)ベースのアプローチだったが、
YOLOの最大の特長は、スライディングwindowやregion proposalといった領域スキャンのアプローチを使わずに、畳み込みニューラルネットワークで画像全体から直接物体らしさと位置を算出する点。
YOLOでは、まず入力画像を正方形(論文の例では448×448)にリサイズし、それを畳み込みニューラルネットワークの入力とする。
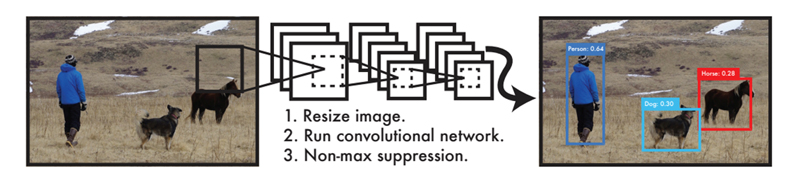
grid cell
YOLOは候補領域検出を行わない代わりに、正方形の画像全体をS × Sのgrid cell(グリッド領域)に分割する。
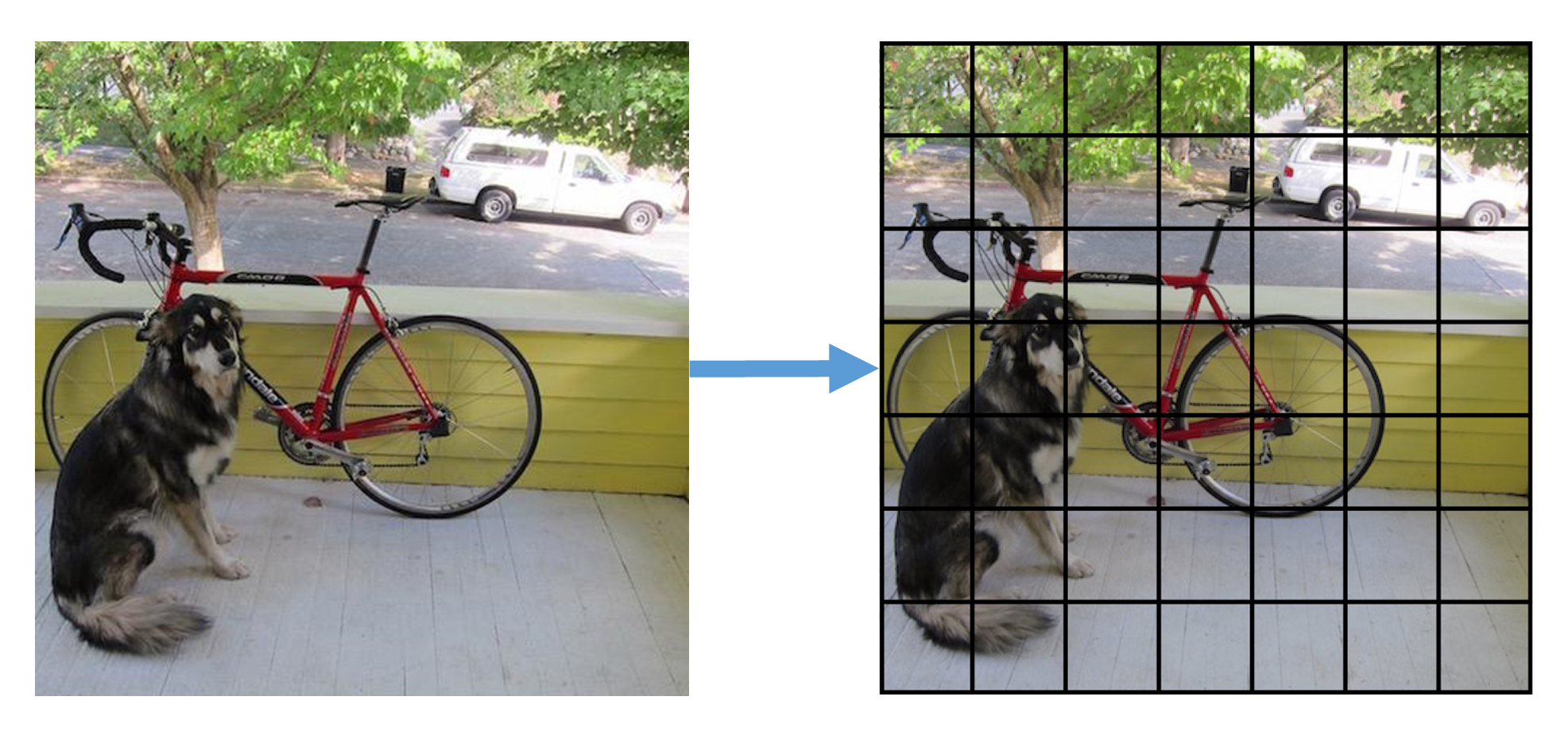
Bounding Boxの推定
分割した各grid cellに対して、B個のBounding Boxを推定する。
1つのBounding Boxにつき、Bounding Boxの座標値(x, y, w, h)と、そのBounding Boxが物体である信頼度(confidence)スコアの計5つの値が出力される。
座標値のx, yはgrid cellの境界を基準にしたBounding Boxの中心座標、幅wと高さhは画像全体のサイズに対する相対値。信頼度スコアはそのBounding Boxが物体か背景かの確率を表す。(物体なら1, 背景なら0)
物体領域の推定精度を測る指標として、正解Bounding Boxと推定Bounding Boxの一致具合を表すIoU (Intersection over Union)がある。
YOLOではBounding Boxの信頼度スコアがIoUを表している。
物体の種類の推定
各grid cell単位で物体の種類も推定する。
C種類の分類クラスで、grid cellが物体である場合にどのクラスに属するかの確率、つまり条件つき確率を推定する。
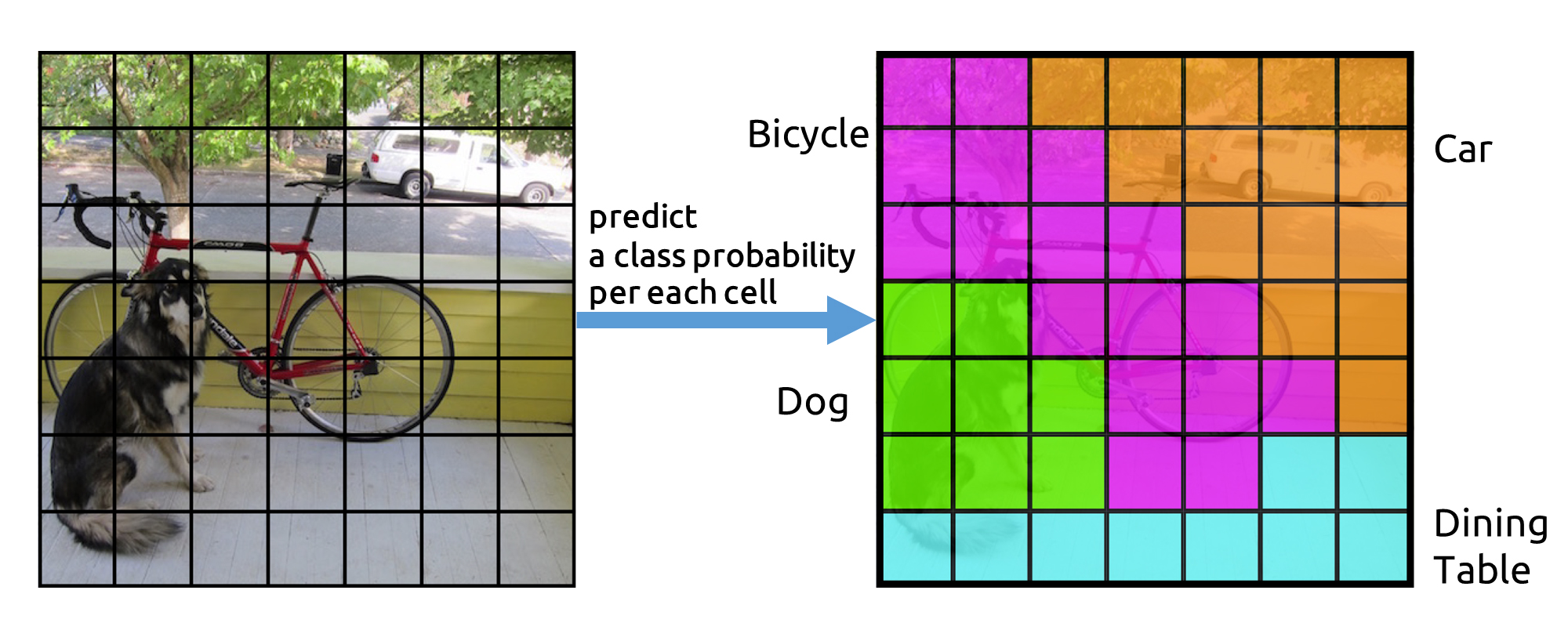
Bounding Boxとclass probability mapの結合
ここで推定したクラス確率を先ほどのBounding Boxと合わせると、何の物体であるかを示す複数のBounding Boxが得られる。

重複領域も含んだこれらのBounding Boxは、信頼度スコアの高いBounding Boxを基準にNMS(Non-Maximum Suppression)という手法で選別する。NMSは、IoU値が大きい(重なり度合いの高い)領域をしきい値で抑制(suppression)する。
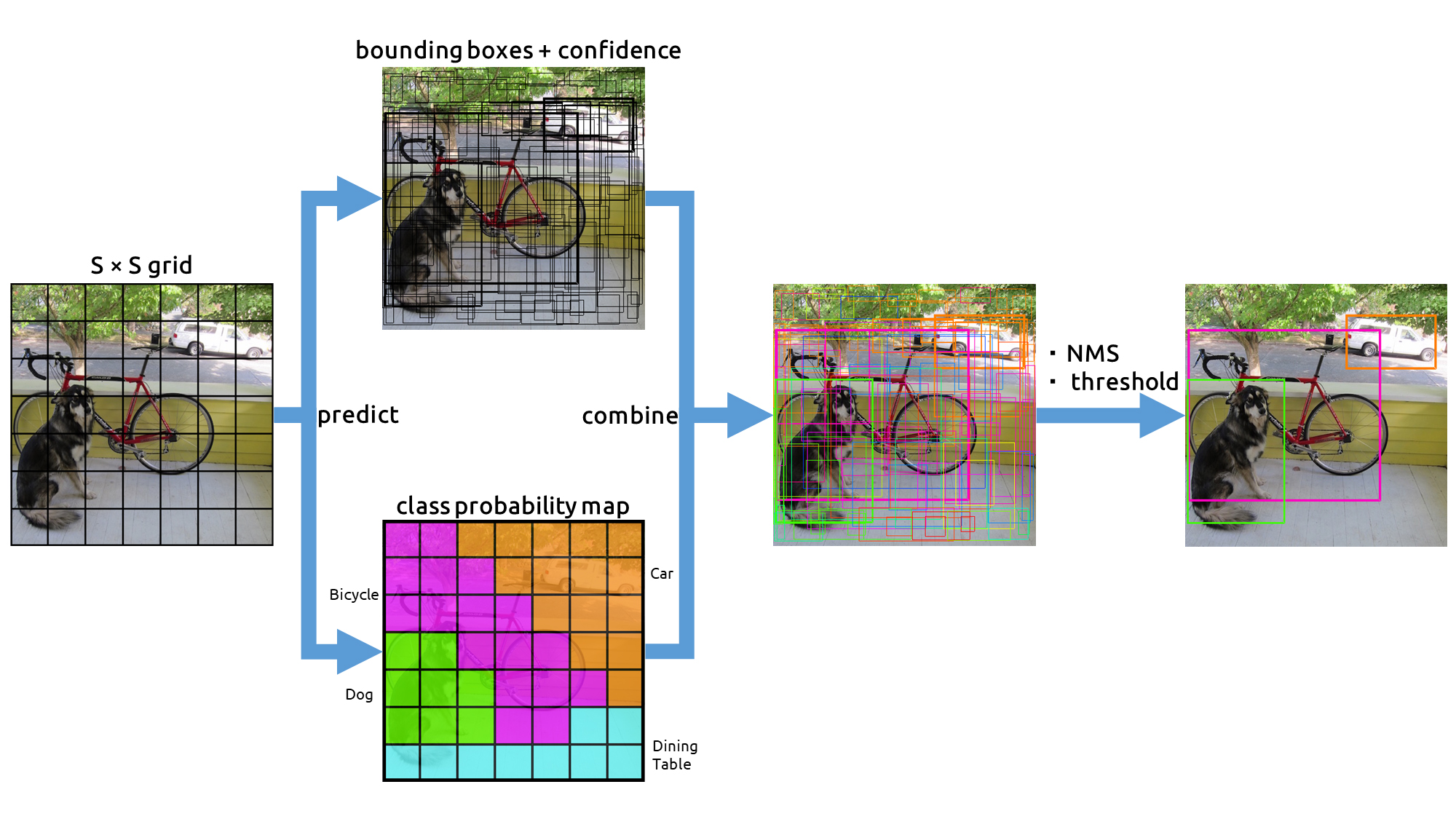
これで物体検出結果が得られる。
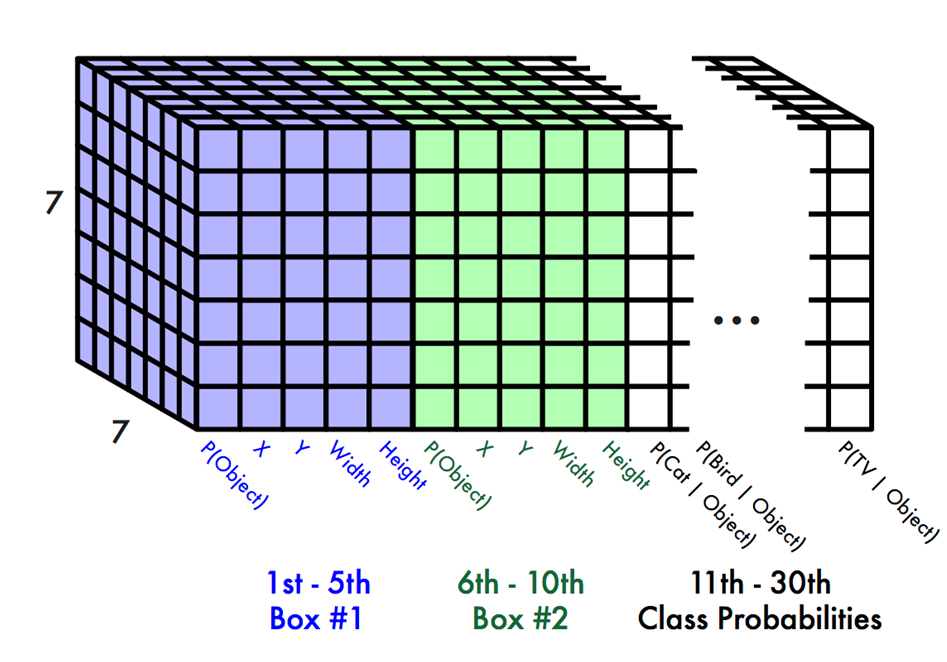
YOLOの出力数
YOLOの出力は、1つのgrid cellにつきB × 5 + C個の出力となり、全体の出力はS × S × (B × 5 + C)個と表せる。
論文の例では、
S = 7
B = 2
C = 20: Pascal VOCデータセットの20種類のラベルを使用
として出力数は合計で
7 × 7 × (2 × 5 + 20) = 7 × 7 × 30 = 1470
となっている。
YOLOのネットワーク
YOLOのネットワーク構造は既存のCNNモデルを流用することなく、YOLO独自のネットワークが設計されている↓
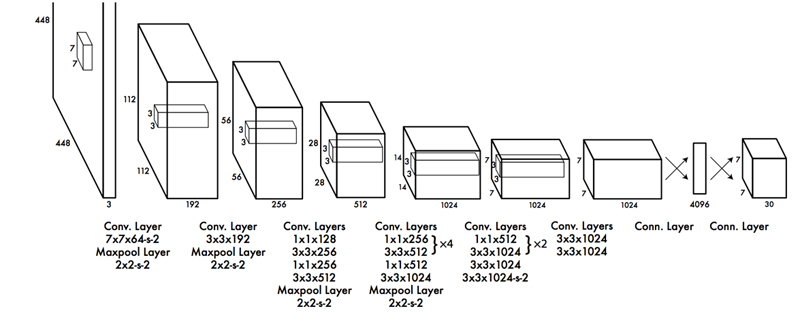
24層の畳み込み層(Conv. Layer)および4層のpooling層を経て画像から特徴を抽出し、2層の全結合層(Conn. Layer)で物体のBounding Box、物体の種類の確率を推定する。
畳み込み層の最終出力サイズ7×7はgrid cellの分割数と一致している。
YOLOによる物体検出の処理時間は画像1枚あたり約22msで、Faster R-CNNの6~7倍ほどの高速化を実現している。
CVPR 2016でのYOLO発表動画
CVPR 2016でのYOLO発表の様子がYouTubeで公開されている。リアルタイム動作デモのために沢山おもちゃを並べている様子に笑ってしまった↓
YOLOは作者のJoseph Redmon氏の独特なキャラクターも有名ですね。
個人サイトデザインや、Darknetという中二病っぽい名前のライブラリなど。(C言語用のディープラーニングライブラリ)
https://github.com/pjreddie/darknet
Joseph Redmon氏はTEDでもプレゼンしている↓
YOLOの改良版
YOLOはその後もYOLO v2, YOLO v3と改良が続いており、認識精度が向上している。
2020年追記:Joe Redmon氏はCV研究からの引退を宣言しました↓
I stopped doing CV research because I saw the impact my work was having. I loved the work but the military applications and privacy concerns eventually became impossible to ignore.https://t.co/DMa6evaQZr
— Joe Redmon (@pjreddie) February 20, 2020
次はSSD(Single Shot Multibox Detector)についてまとめよう↓

関連記事
OpenCVでカメラ画像から自己位置認識 (Visual O...
Zibra Liquids:Unity向け流体シミュレーショ...
Structure from Motion (多視点画像から...
ツールの補助で効率的に研究論文を読む
DUSt3R:3Dコンピュータービジョンの基盤モデル
GoogleのDeep Learning論文
UnrealCV:コンピュータビジョン研究のためのUnrea...
Active Appearance Models(AAM)
ZBrushトレーニング
Rerun:マルチモーダルデータの可視化アプリとSDK
Multi-View Environment:複数画像から3...
機械学習について最近知った情報
「ベンジャミン·バトン数奇な人生」でどうやってCGの顔を作っ...
Google製オープンソース機械学習ライブラリ『Tensor...
PyDataTokyo主催のDeep Learning勉強会
AI英語教材アプリ『abceed』
OpenGVのライブラリ構成
Live CV:インタラクティブにComputer Visi...
fSpy:1枚の写真からカメラパラメーターを割り出すツール
第25回コンピュータビジョン勉強会@関東に行って来た
WordPressで数式を扱う
書籍『OpenCV 3 プログラミングブック』を購入
機械学習手法『Random Forest』
BlenderProc:Blenderで機械学習用の画像デー...
Pix2Pix:CGANによる画像変換
顔追跡による擬似3D表示『Dynamic Perspecti...
BlenderでPhotogrammetryできるアドオン
Fast R-CNN:ディープラーニングによる一般物体検出手...
Caffe:読みやすくて高速なディープラーニングのフレームワ...
ポイントクラウドコンソーシアム
SVM (Support Vector Machine)
Deep Fluids:流体シミュレーションをディープラーニ...
Kornia:微分可能なコンピュータービジョンライブラリ
SegNet:ディープラーニングによるSemantic Se...
Mask R-CNN:ディープラーニングによる一般物体検出・...
海外ドラマのChromaKey
画像認識による位置情報取得 - Semi-Direct Mo...
今年もSSII
Paul Debevec
機械学習での「回帰」とは?
SDカードサイズのコンピューター『Intel Edison』
Super Resolution:OpenCVの超解像処理モ...

コメント
[…] ※3: K210 development boards ※4: 【物体検出手法の歴史 : YOLOの紹介】 ※5: YOLO (You Only Look Once):ディープラーニングによる一般物体検出手法 ※6: Kendryte K210 […]