
これまで、ディープラーニングによる一般物体検出手法について、R-CNNから順にまとめてきた。
こちらの系譜図だと最後にMask R-CNNが位置していたので、とにかくMask R-CNNまではちゃんと勉強したかったのだ↓



Mask R-CNNは一般物体検出(Generic Object Detection)とSegmentationを同時に行うマルチタスクな手法らしいと聞いて、Mask R-CNNを勉強する前にSegmentationの知識も必要かと思ってこれまでSemantic Segmentationについてもまとめてきていたけど↓
Mask R-CNNで行うSegmentationはSemantic Segmentationではなく、より難しいInstance Segmentationと呼ばれるタスクらしい。
まずはこれらのSegmentationタスクの違いについて整理しておく。
Segmentationタスクの種類
Segmentationとは画像の領域分割を行うこと。つまり、画像をpixel単位で分類するタスクと言える。
Semantic Segmentation
Semantic Segmentationは、画像のpixelを「どの物体クラス(カテゴリー)に属するか」で分類するタスク。(そのため、Category-level segmentationとも呼ばれる)
Instance Segmentation
それに対して、Instance Segmentation (Instance-level segmentation)は、画像のpixelを「どの物体クラス(カテゴリー)に属するか、どのインスタンスに属するか」で分類するタスク。これはSemantic Segmentationよりもさらに難しいタスク設定。
「インスタンス」という言い回しが分かりづらいので、例で見て行こう。
例えば、以下の画像に対してSemantic, InstanceそれぞれのSegmentationを行うと、

以下の図のようになる。
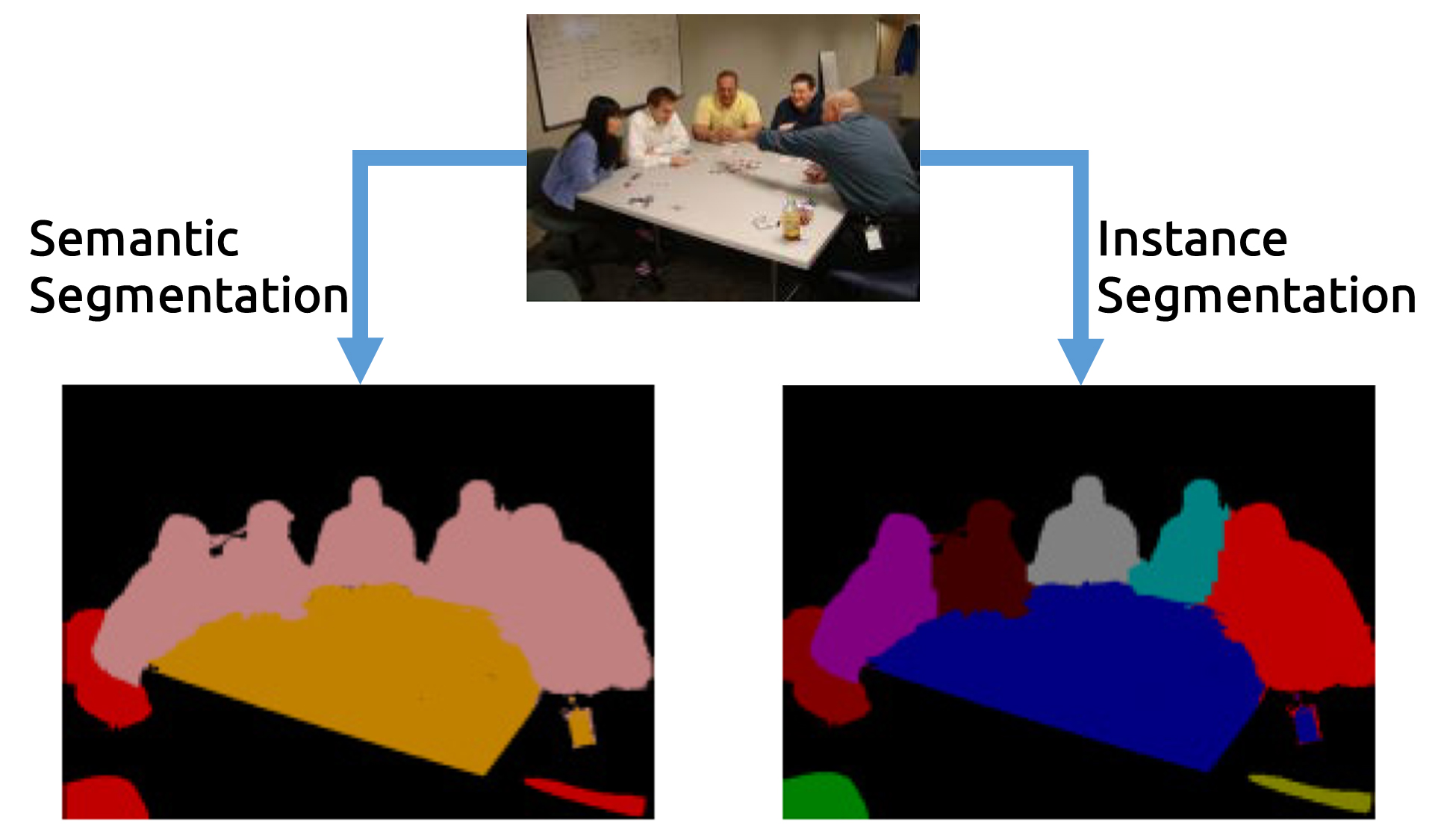
Semantic Segmentationでは、人、テーブル、椅子といった物体クラス(カテゴリー)単位でしかpixelを分類できないため、複数重なった人物同士の境界を判別することができない。つまり、同一クラスに属する別々の物体の分類はできないのだ。
一方、Instance Segmentationは、同じクラスに属する物体同士であってもそれぞれを別の物体として分類するため、重なって写っている人物領域でも1人1人を別の人物として境界を求めることができる。
では、Instance Segmentationがどういうタスクなのか分かったところで本題のMask R-CNNについて↓
Mask R-CNN
Mask R-CNNはICCV 2017で発表された論文 Mask R-CNNで提案された、一般物体検出(Generic Object Detection)とInstance Segmentationを同時に行うマルチタスクの手法。
Learn OpenCVにOpenCVでMask R-CNNを試すチュートリアルがあるので、どんなことができるのか手軽に試したいならまずはこちらのサンプルを動かしてみるのも良いかもしれません↓

https://www.learnopencv.com/deep-learning-based-object-detection-and-instance-segmentation-using-mask-r-cnn-in-opencv-python-c/
Mask R-CNNのネットワーク構成
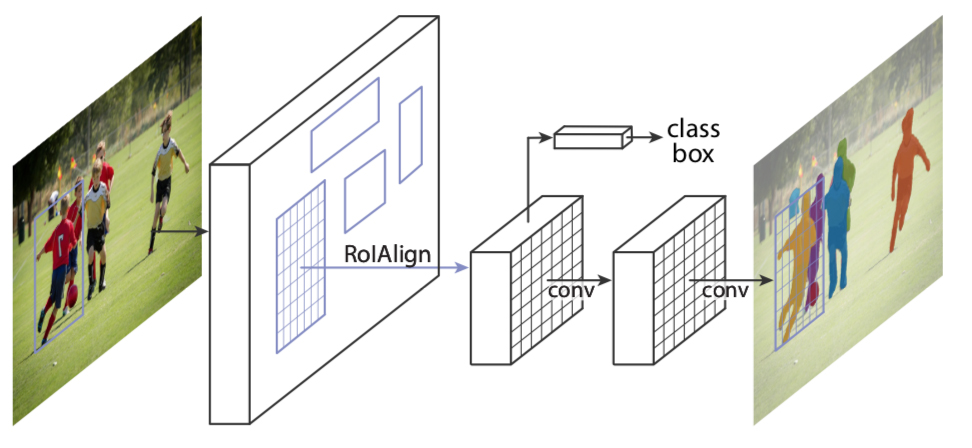
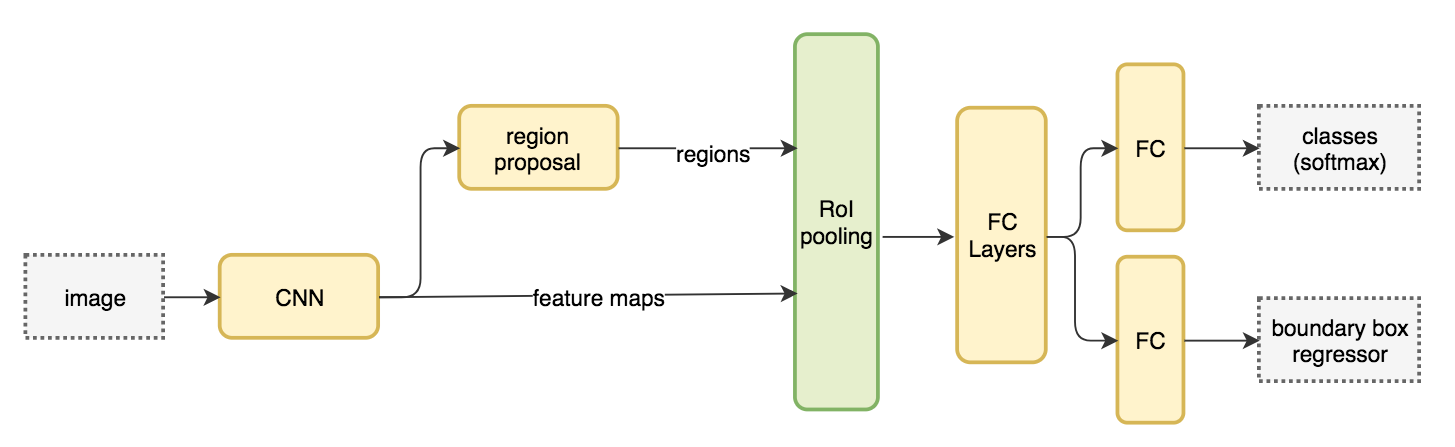
Mask R-CNNのネットワーク構造は、Faster R-CNNのネットワーク構造をベースに改良したもの。

Mask R-CNNもFaster R-CNNと同様に、まずRPN (Region Proposal Network)によって候補領域(region proposal)の検出を行う。
Mask R-CNNのネットワークではSegmentationのマスクを推定するための分岐が追加され、特徴マップの各RoI(Region of Interest:関心領域)を固定サイズのベクトルに収めるRoI Pooing処理の代わりに、それを改良したRoI Alignという新しい手法が導入されている。
Faster R-CNNのネットワーク

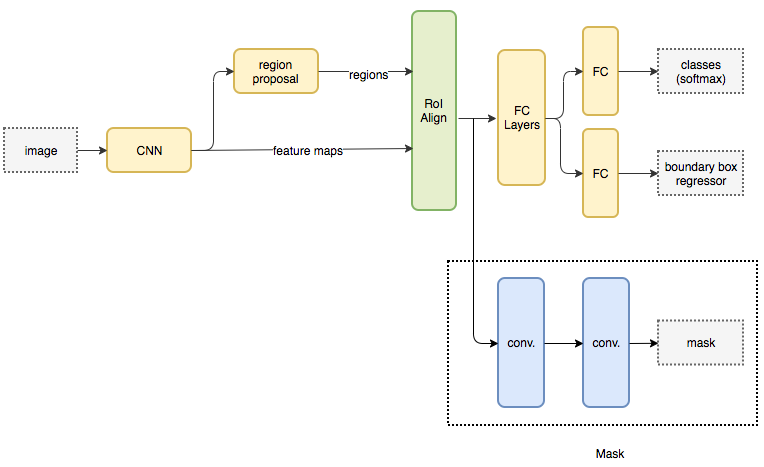
Mask R-CNNのネットワーク
スポンサーリンク

この論文では、Mask R-CNNの基本設計の有用性を示すために、画像から特徴抽出を行うCNN(論文ではbackbone networkと呼んでいる)に複数種類のネットワーク(ResNet, ResNeXt, FPN)を試して結果を比較したり、違うデータセットを使っての比較、別のタスクへの応用例として人体の姿勢推定(OpenPoseのような骨格検出)の実装を示している。
そして、それぞれの実験をCaffe2で実装したソースコードも公開している↓
https://github.com/facebookresearch/Detectron
物体領域のマスクを推定する
Faster R-CNNでは、RoIの特徴ベクトルから全結合層を経てネットワークが2つに分岐し、以下の2種類の出力があった。
- 物体クラス(カテゴリー)の分類
- Bounding Boxの回帰
Mask R-CNNでは、RoIの特徴ベクトルに対してもう1つ分岐が追加されており、以下の3種類の出力がある。
- 物体クラス(カテゴリー)の分類
- Bounding Boxの回帰
- 物体領域マスクの推定(pixelの分類)

Mask R-CNNではこれらの3つの分岐が並列に処理される。
RoIの特徴ベクトルからマスクを推定する分岐は、小さなFully Convolutional Networkで構成されており、畳み込み層によってm×mの物体領域マスクを推定する。分類対象がK種類あるとすると、K種類のクラスごとに二値分類を行うことになり、マスクの推定結果はK×m×mの出力となる。
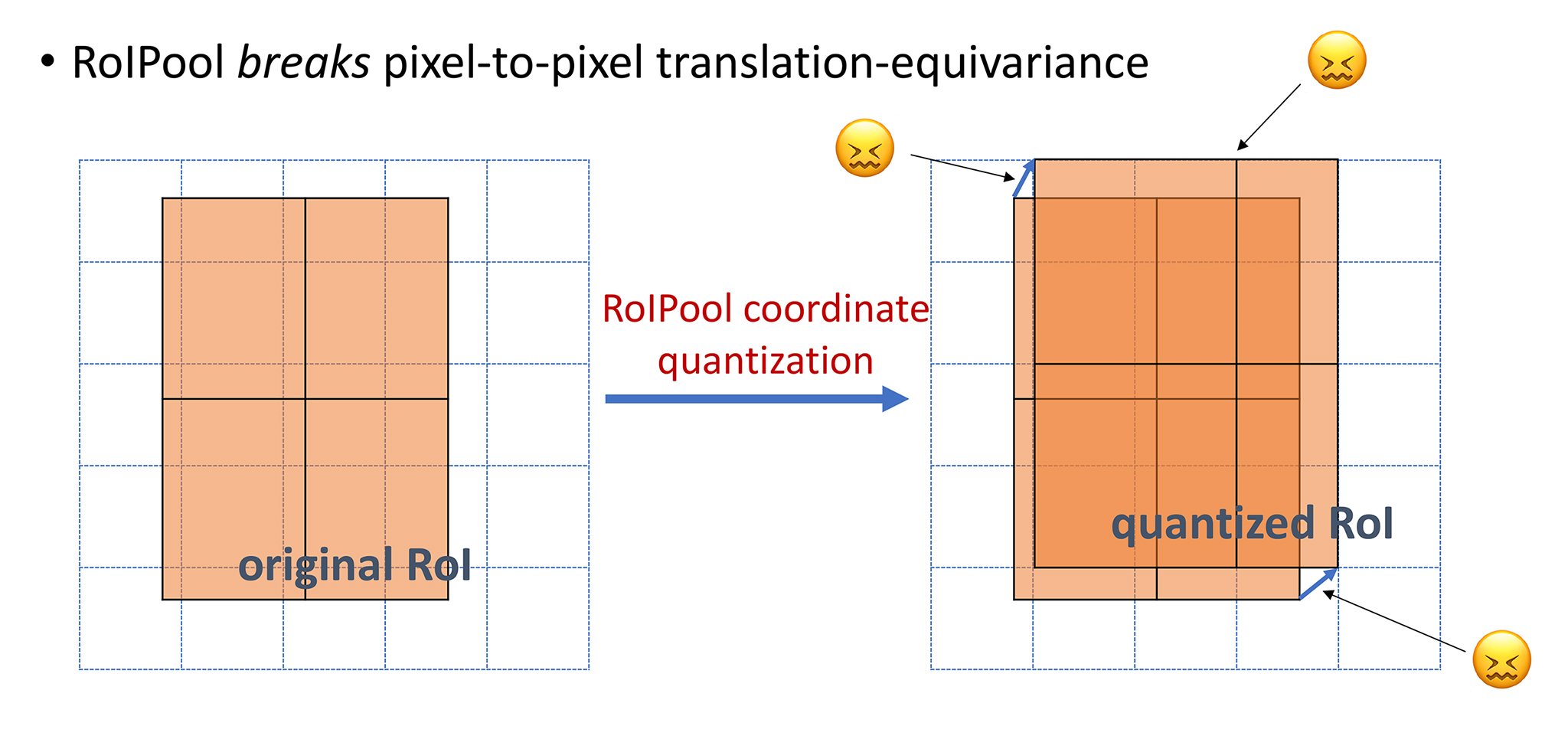
マスクの推定では、推定したマスクのpixel位置と入力画像のpixel位置の一致精度が求められる。しかし、従来のRoI Poolingでは、特徴マップから固定サイズのRoI特徴ベクトルを切り出す際に情報を固定の解像度で離散化して切り捨ててしまうため、精度の高いマスクを推定することができなかった。
RoI Align
マスク推定のpixel精度を上げるために、特徴マップからの情報を大きく損なわずに固定サイズのRoI特徴ベクトル化するRoI Alignという手法が提案されている。Alignment(位置合わせ)を重視したRoI特徴の作成ということですね。
RoI Poolingでは、特徴マップ上のRoIを最大値や平均値で間引いて固定サイズのベクトルへ落とし込んでいた。これでは多くの情報が欠落してしまうため、かなり粗い(雑な)離散化と言える。
それに対してRoi Alignでは、特徴マップをただ間引くのではなく、補間によってsub-pixelレベルの情報を考慮する形で固定サイズのベクトルを作成している。
RoIをN×Nのグリッドに分割し、グリッドの各点の値を特徴マップの4ヶ所からサンプリングした値をバイリニア補間して算出する。そしてその結果をmax poolingあるいは平均poolingして固定サイズのRoI特徴ベクトルとする。
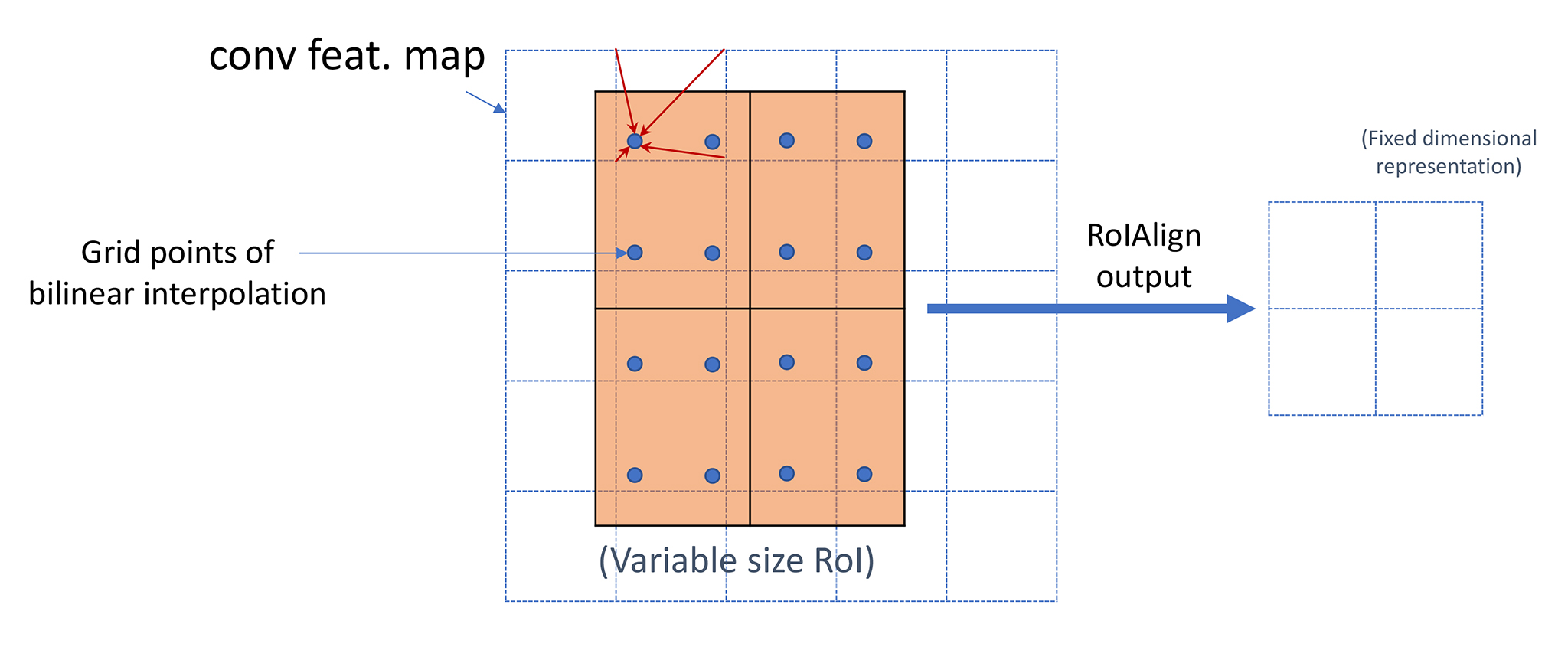
ここで重要なのはsub-pixelレベルの情報を切り捨てずにRoI特徴ベクトルを作成することで、補間方法はバイリニア補間に限らず何でも良いそうです。
実験:人体の姿勢推定(骨格検出)
この論文では、Mask R-CNNを人体の姿勢推定(骨格検出)に応用する実験も行っている。
ここでは、人間の骨格の各関節部位を表すK種類のラベルと、その位置を表すkey-pointがアノテーションされているCOCOデータセットが使われている。
各key-pointの位置をone-hotマスクとし、Mask R-CNNでK個のマスクを推定するタスクとして学習させて当時のstate-of-the-artを達成したらしい。

この推定精度の高さは、Mask R-CNNが物体検出とInstance Segmentationの両方を同時に行えるマルチタスク手法だからこその恩恵だそうだ。
bells and whistles
ところで、完全に余談だけど、Mask R-CNNの論文を読んで”bells and whistles“という慣用句を知った。「追加のオプション」みたいな意味らしい。
自動車文化から生まれた表現らしく、そこから転じて技術論文では「余計な小細工」みたいな意味合いで使われている。「余計な小細工無しで実現できる」と主張したい場合に”without bells and whistles“とか”bells and whistles free“という言い回しが使われる。アドホックな対処を必要とせず、純粋にアルゴリズムが優れていると強調する表現。
ICCV 2017でのMask R-CNN発表動画
ICCV 2017でのMask R-CNN発表の様子がYouTubeで公開されている。

Mask R-CNNの実装
Learn OpenCVにPyTorch実装のチュートリアルがある↓
https://www.learnopencv.com/mask-r-cnn-instance-segmentation-with-pytorch/
さて、GitHubで公開されているディープラーニングによる一般物体検出の発展の時系列をまとめた図に従うと↓


この調子で一般物体検出の勉強を進めるなら、YOLO v3, RefineDet, M2Detと続くのか。次はRefineDetに行ってみるか?
2019年10月 追記:FacebookからInstance Segmentationの新しい手法が↓
https://ai.facebook.com/blog/a-new-dense-sliding-window-technique-for-instance-segmentation/
それよりもGAN (Generative Adversarial Network)についてちゃんと勉強したいな↓

スポンサーリンク