

Faster R-CNN, YOLOに続きEnd-to-Endの手法のSSD (Single Shot Multibox Detector)をお勉強。

またこちらの系譜図を引用↓



SSDはFaster R-CNNと同程度の認識精度で、処理速度はYOLO v1よりも高速(59FPS)な手法。
SSD (Single Shot Multibox Detector)
SSD (Single Shot Multibox Detector)はECCV 2016で発表されたSSD: Single Shot MultiBox Detectorで提案された手法。
SSDはYOLOと同じように、領域スキャンのアプローチを使わずに入力画像からCNNで直接物体の位置を検出するOne-Stage(Shot)と呼ばれるアプローチの手法。
YOLOとの大きな違いは、YOLOがBounding Boxの出力を出力層だけで行っていたのに対し、SSDではCNNの複数の層から物体のBounding Boxを出力する点。
畳み込みニューラルネットワークの性質
畳み込みニューラルネットワークでは、入力画像から特徴を抽出する過程(畳み込みやプーリングなど)で特徴マップが徐々に小さくなっていく。そのため、出力層近くの特徴マップ上で1 pixelの要素であっても、もとの入力画像上では大きな領域に相当する。
この性質により、畳み込みニューラルネットワークを特徴抽出に利用して物体検出を行うと、小さな物体を検出できない場合がある。
各層での特徴マップを利用する
そこでSSDでは、畳み込みニューラルネットワークの途中の各層での大きいサイズの特徴マップも利用することで比較的小さな物体の検出も可能にしている。
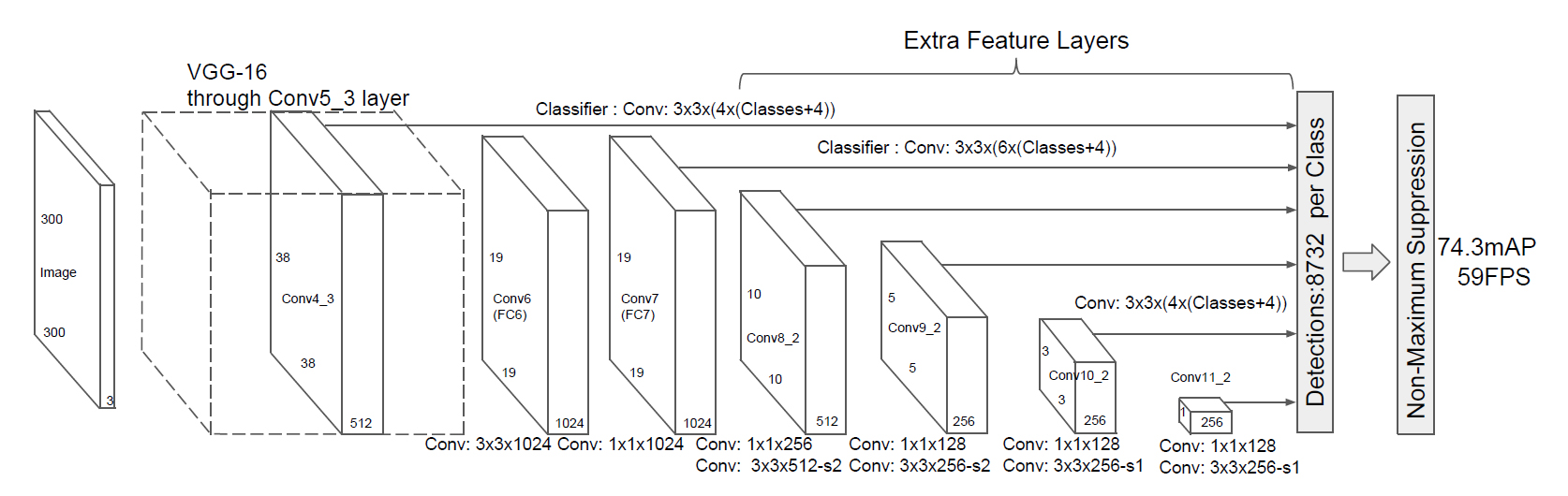
SSDのネットワーク構造は、既存の畳み込みニューラルネットワーク(VGG-16)の構造をベースネットワークとして途中まで流用し、その次にさらに補助となる畳み込みネットワークを追加している。
学習の目標
SSDの教師データはYOLOと同じで、画像とそこに写っている各物体を示すBounding Boxとラベルとなる。
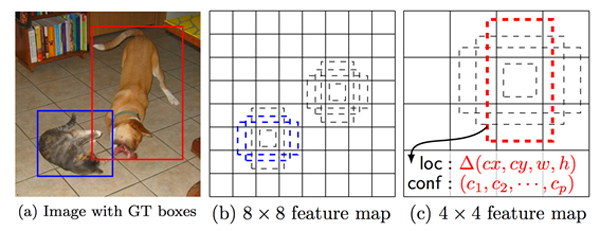
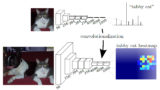
以下の図の例では、(a)のように1枚の画像に対して犬と猫のBounding Boxとラベルがground truthとして与えられている。
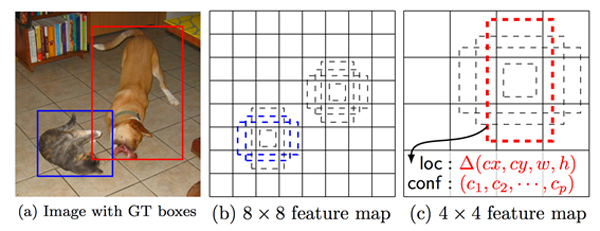
学習時には、(a)の実線の青い矩形(教師データ)と、(b)の点線の青い矩形(推定値)の位置・サイズが一致するように、かつ物体クラスが猫となるようにネットワークの重みを更新する。
同様に、(a)の実線の赤い矩形(教師データ)と、(c)の点線の赤い矩形(推定値)の位置・サイズを一致させ、犬と推定できるように学習する。
default box
SSDでもFaster R-CNNのanchorのように、検出する物体の領域サイズ・アスペクト比のバリエーションに対応するためにdefault boxと呼ばれる複数の矩形パターンを定義する。SSDでは1つの入力画像に対してサイズの違う複数の特徴マップを扱うため、各サイズの特徴マップごとにdefault boxを定義することで物体の候補領域を効率的に離散化している。
例えば、以下の図のように異なるサイズ(8×8, 4×4)の特徴マップ上の各セルの位置について、(この例では)4パターンのdefault boxを適用している。
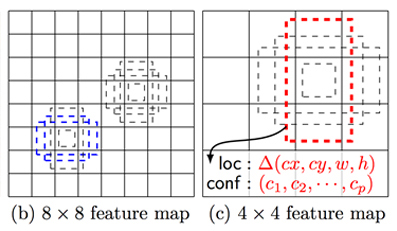
サイズがm × nでpチャンネルある特徴マップに対して、各セルの位置で3×3×pの小さな畳み込みカーネルを使う。そして、default boxごとに物体領域のBounding Boxの位置・サイズのオフセット値(loc:⊿(cx, cy, w, h))と、そのBounding Box内の物体がどのクラスに分類されるかの信頼度(conf:(c1,c2, …, cp))を推定する。(ここで言うオフセット値とは、default boxを基準としたBounding Boxの相対的な位置・サイズのこと)
スポンサーリンク
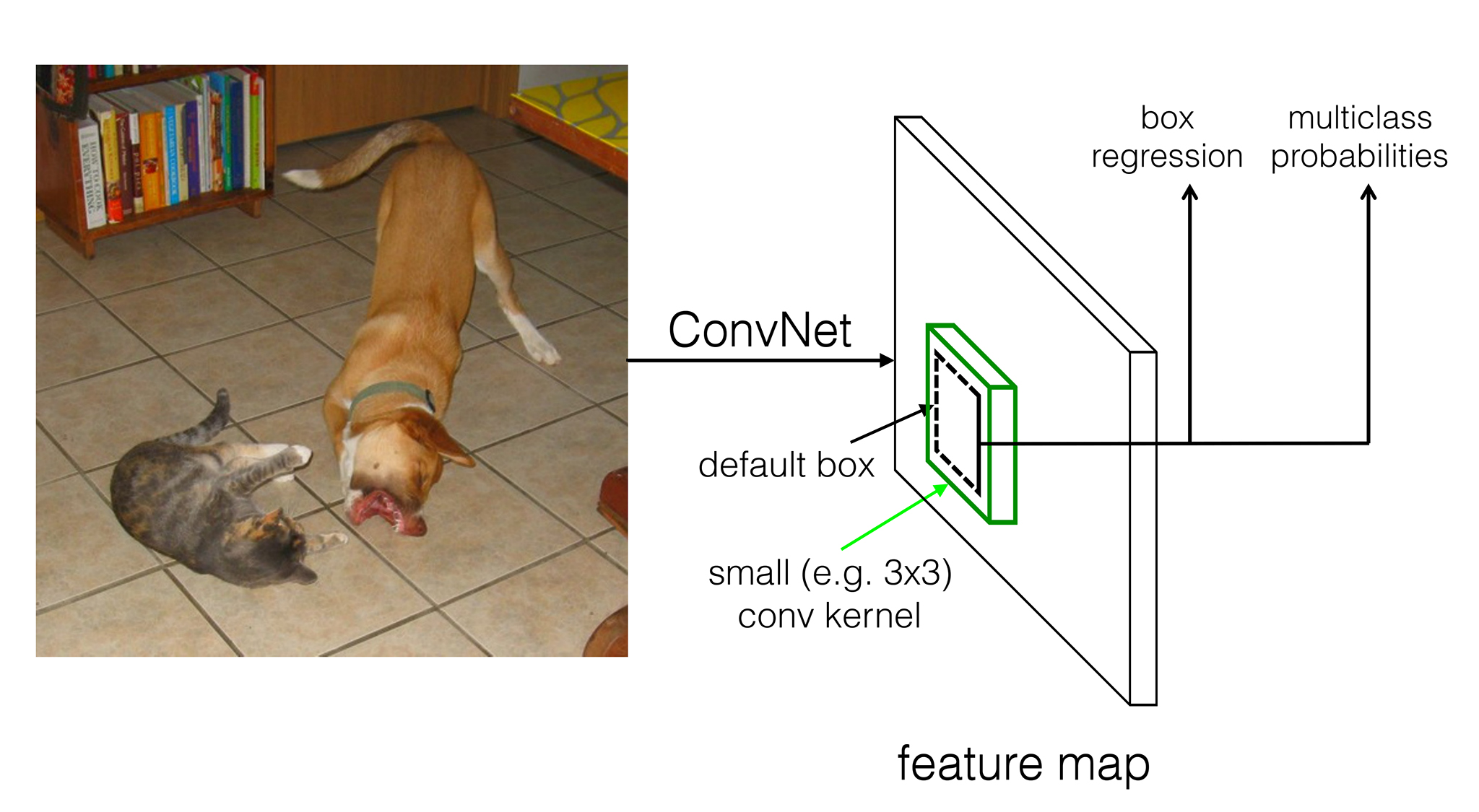
分類のクラス数をc、default boxのパターン数をkとすると、特徴マップの各セル位置から得られる出力の数は合計(c + 4)k個となる。(4は1つのBounding Boxあたりの出力値の数)
つまり、m × nサイズの特徴マップから得られる出力数は(c + 4)kmn個となる。
Multi-Scale Feature Maps
複数サイズの特徴マップについて順に見ていくと、
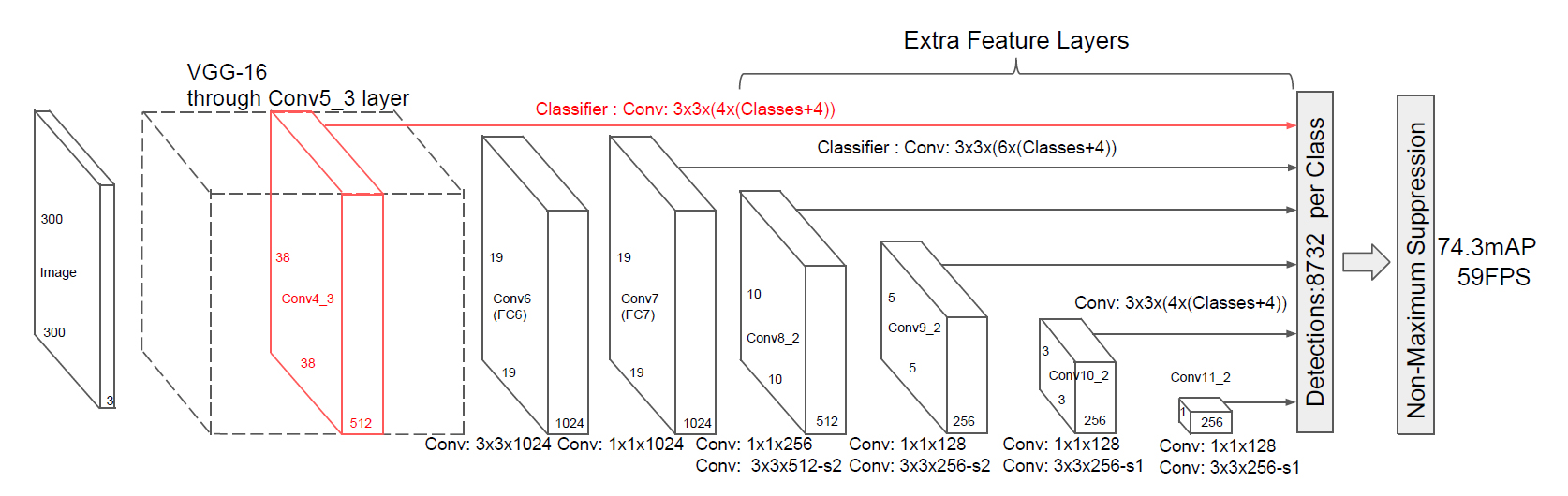
まず300×300×3の入力画像からVGG-16の畳み込み層の途中(Conv4_3)までを利用して38×38×512の特徴マップを抽出する。
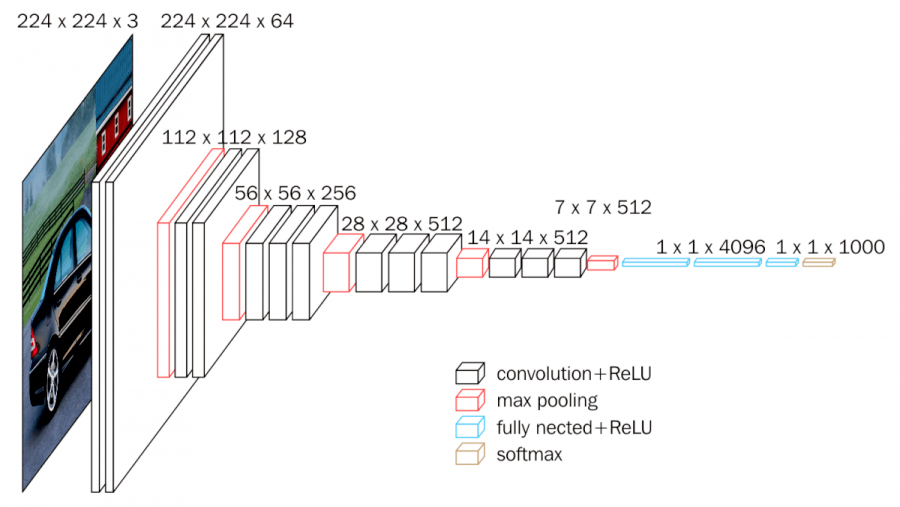
参考:VGG-16のネットワーク構造↓
ここで抽出した38×38×512の特徴マップをネットワークの次の層の入力とし、VGG-16の残りの畳み込み層(Conv5_3)と、3×3×1024、1×1×1024の畳み込みで19×19×1024の特徴マップを抽出する↓
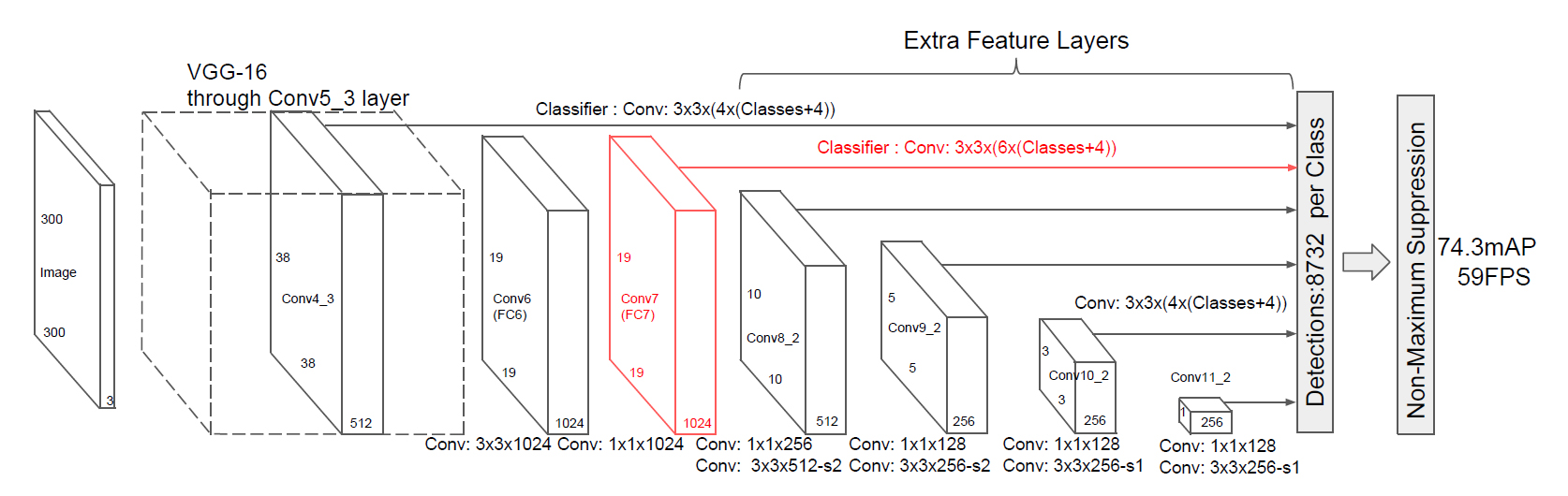
以降は同様に、この19×19×1024の特徴マップをさらに次の層の入力とし、10×10×512の特徴マップを抽出する↓
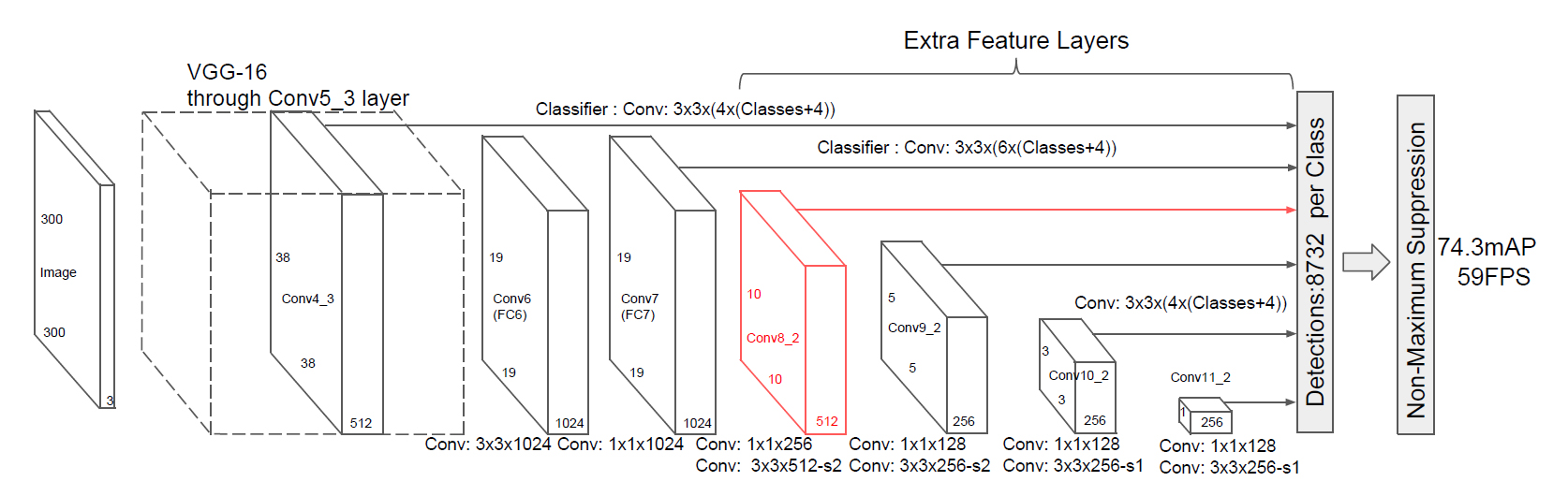
同様に、10×10×512の特徴マップを次の層の入力として5×5×256の特徴マップを抽出↓
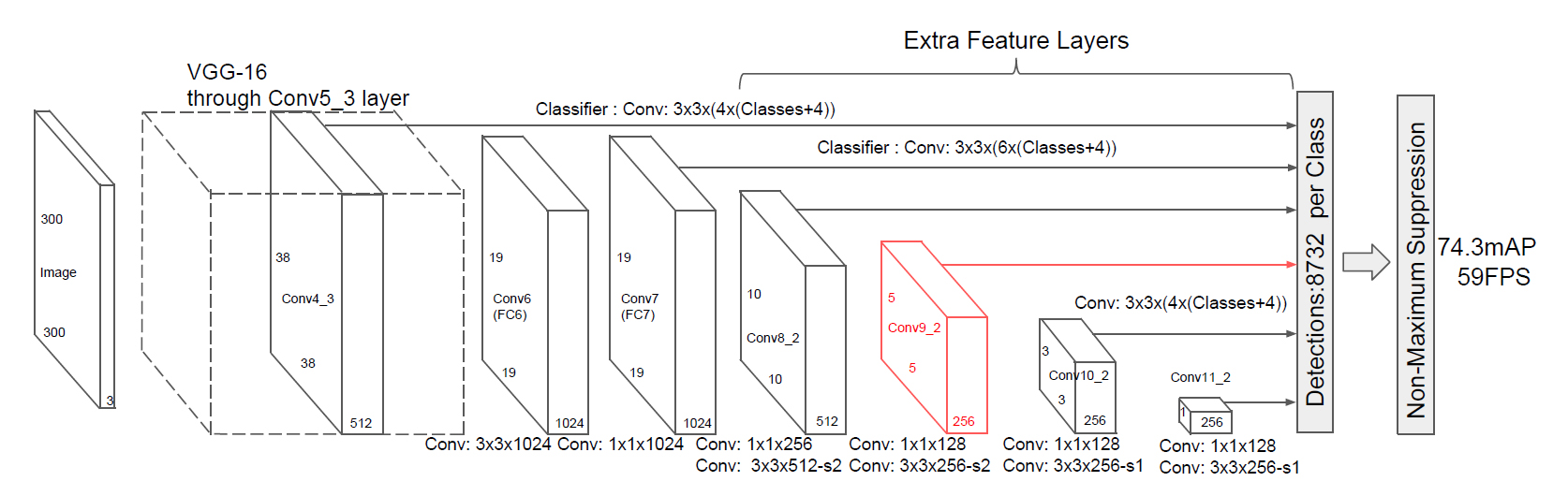
5×5×256の特徴マップを入力として3×3×256の特徴マップを抽出↓
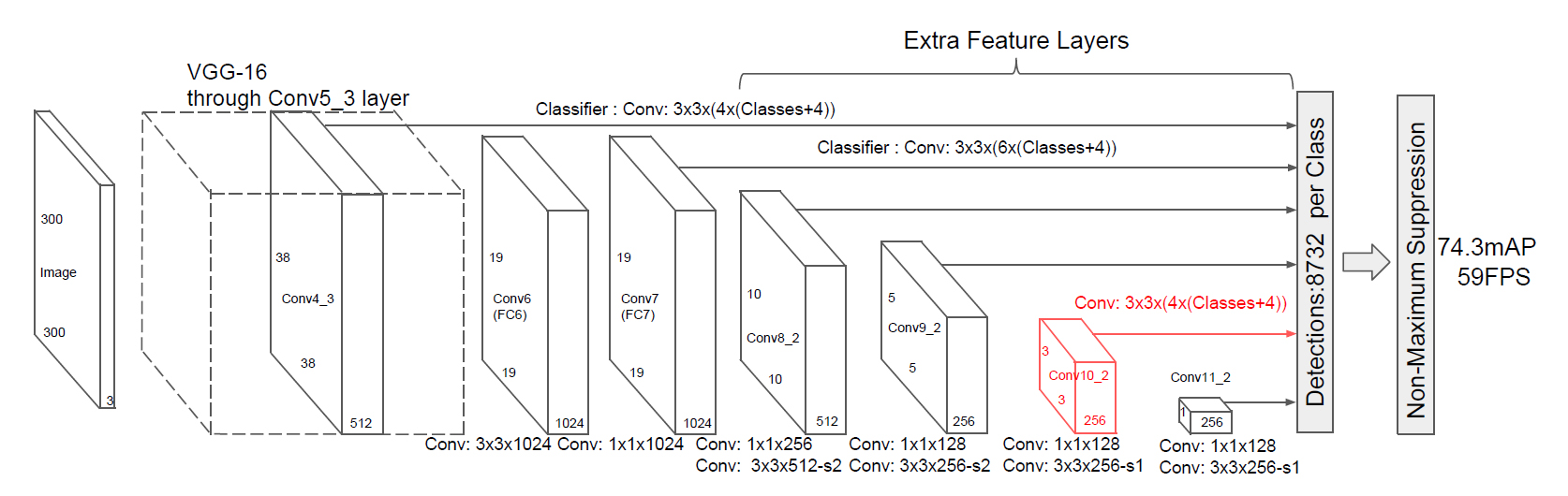
3×3×256の特徴マップを入力として1×1×256の特徴マップを抽出↓
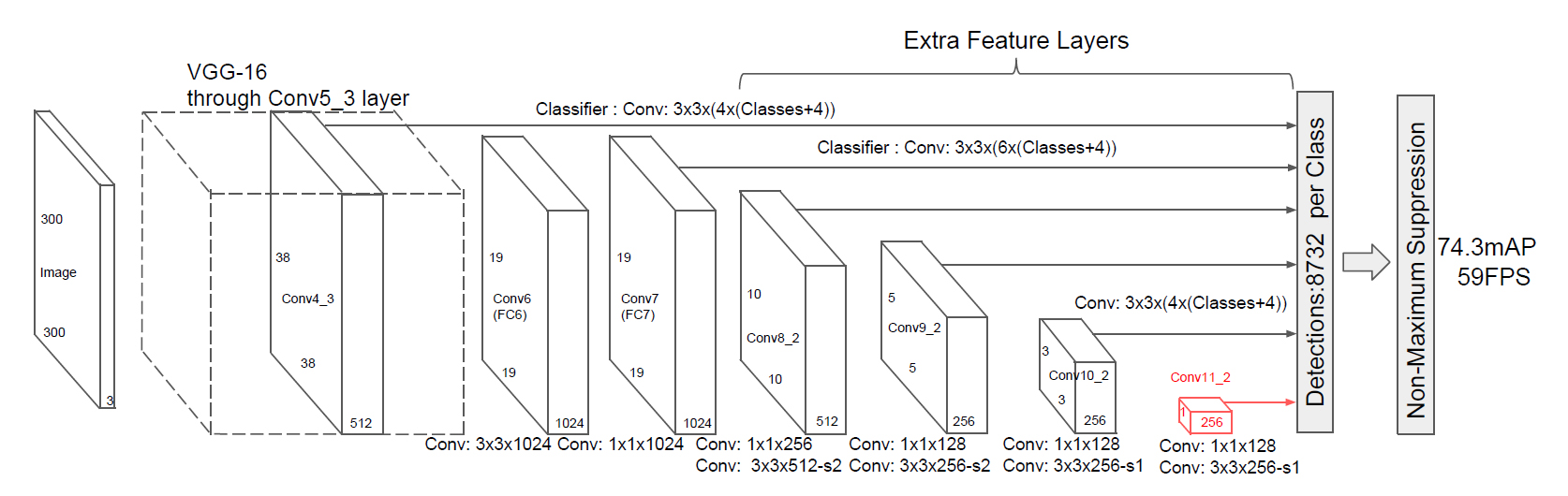
このように、SSDでは6段階のサイズ違いの特徴マップを抽出し、各サイズの特徴マップのセルごとにdefault boxに対するBounding Boxのオフセットを推定する。そのため、1つの入力画像に対して分類クラスあたり8732個の物体領域候補が出力される。
そして、ここで出力される複数のBounding Boxを、YOLOと同様にNMS (Non-Maximum Suppression)によって選別して最終的な検出結果とする。
論文では、入力画像のサイズ違いで300×300と512×512の2パターンの実装・実験を行っており、それぞれの処理速度、認識精度は以下の通り。(NVIDIA TITAN X環境でのVOC2007テスト)
- SSD300 (300×300):59FPS, 74.3%mAP
- SSD512 (512×512):19FPS, 76.9%mAP
次はMask R-CNNと行きたいところだけど、その前にSegmentation系かな。
スポンサーリンク