
FCN, SegNet, U-Netに引き続きディープラーニングによるSemantic Segmentation手法のお勉強。

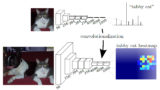
次はPSPNet (Pyramid Scene Parsing Network)について。


PSPNet (Pyramid Scene Parsing Network)
PSPNet (Pyramid Scene Parsing Network)はCVPR 2017で発表されたPyramid Scene Parsing Networkで提案されたSemantic Segmentation手法。
SegNetやU-Netの登場以降、ディープラーニングによるSemantic SegmentationではEncoder–Decoder構造が定番となった。
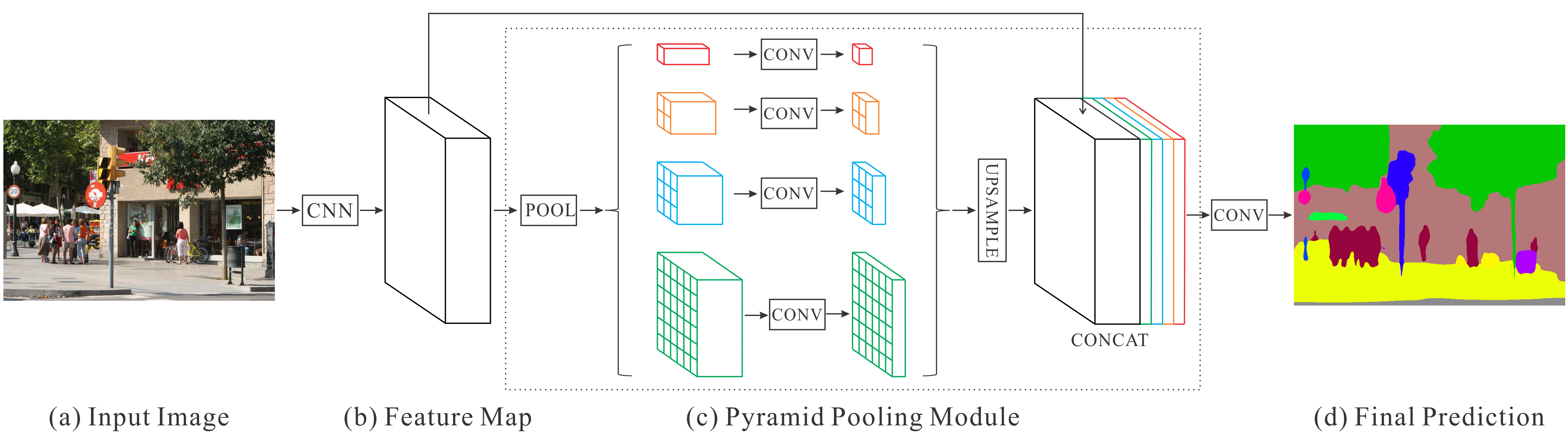
PSPNetでは、EncoderにResNet101(大規模データで学習済み)の特徴抽出層を利用しており、EncoderとDecoderの間にPyramid Pooling Moduleを追加している↓

Fast R-CNNの記事で触れたSPPNetで、似た名前のSpatial Pyramid Pooling(空間ピラミッドプーリング)が使われていた。
同じなのは複数の解像度でmax-poolingを行うという点だけです(笑)
スポンサーリンク
Pyramid Pooling Module
Encoderによって入力画像から抽出された特徴マップのサイズは、ダウンサンプリングされて元の入力画像の1/8になる。
Pyramid Pooling Moduleでは、Encoderで抽出された特徴マップに対して、複数の解像度でmax-poolingをかけてそれぞれのスケールで捉えた特徴マップを得る。これによって、画像の大域的なコンテキストと小さな部分の情報の両方を拾うことができる。
Pyramid Pooling Moduleの階層数や各階層での特徴マップのサイズは、入力される特徴マップのサイズに合わせて設計する。Pyramid Pooling Moduleの階層の数をNとすると、削減後の各特徴マップのチャンネル数は1/Nになる。
論文の例では、以下の図のように階層的に4つの異なるカーネルサイズ(1×1, 2×2, 3×3, 6×6)でmax-poolingを行い、得られた複数スケールの特徴マップを1×1で畳み込んでチャンネル数を削減する。
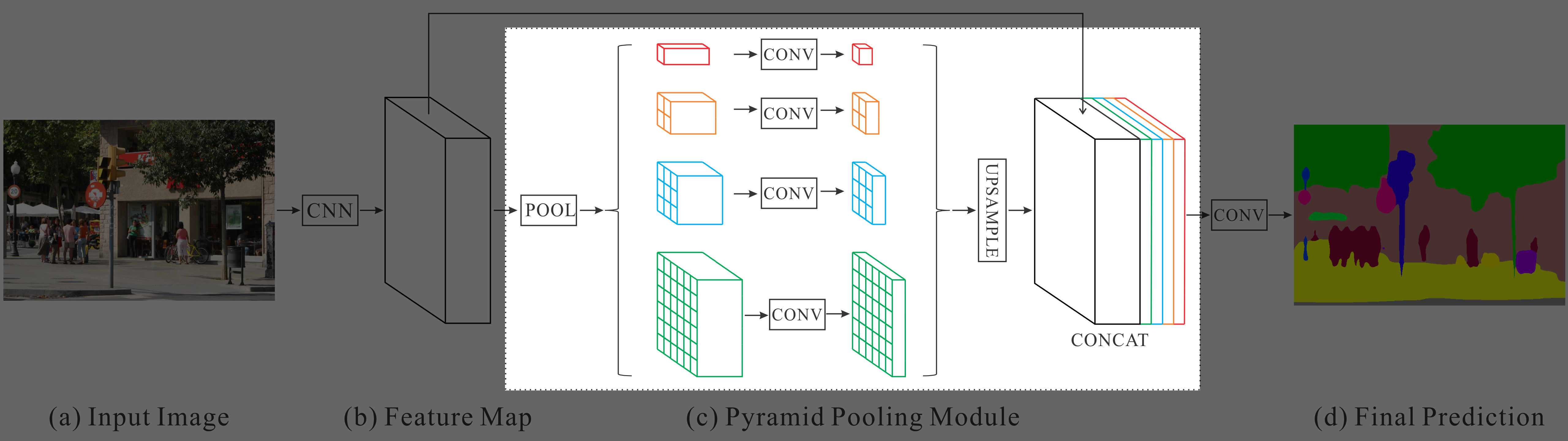
そして、このチャンネル数を削減した特徴マップをバイリニア補間で元の特徴マップと同じサイズにアップサンプリングする。
アップサンプリングしたこれらの特徴マップを元の特徴マップにチャンネルを追加する形で連結し、大域的なコンテキストと局所的な情報の両方を持った特徴マップとする。
最終的に、この連結した特徴マップに対して1×1の畳み込みを行ってSemantic Segmentationの結果を得る。

あれ、何か妙に情報があっさりだぞ。。。
次はRefineNet (Multi-Path Refinement Network)について勉強しよう。
スポンサーリンク