
GAN, DCGAN, CGAN, Pix2Pix, CycleGANに引き続きGAN手法のお勉強。


次はPGGAN (Progressive Growing GAN)について。
PGGAN (Progressive Growing GAN)
PGGAN (Progressive Growing GAN)はICLR 2018で発表された研究 Progressive growing of GANs for improved quality, stability, and variationで提案された手法。
NVIDIAが発表した研究で、関連資料が沢山公開されていますね↓
https://github.com/tkarras/progressive_growing_of_gans
スライドだけでなくポスターも公開されてるけど、この研究はポスター発表だったのか?
これまで、GANやDCGANで生成できる画像の解像度は64×64程度が限界で、解像度を上げると不安定になって学習が上手く収束しなかった。
Progressive Growing GAN(PGGAN)は、GANで高解像度な画像生成を可能にした手法の1つ。
PGGANでは1024×1024解像度の画像が生成できるようになった↓
言われなければ生成画像とは分からないレベルだ。
PGGANのネットワーク構造
PGGANの大枠のアーキテクチャは通常のGANと同様、本物の画像とGeneratorが生成した偽画像をDiscriminatorが見分けるイタチゴッコを学習する構造だ。
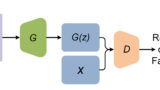
PGGANは畳み込み層、転置畳み込み層を使っているので、DCGANの進化系と捉えた方が分かりやすいでしょうか。

PGGANとDCGANの大きく違う点は、以下の図のように、段階的に学習データの解像度を上げて行き、それに合わせてGeneratorとDiscriminatorのネットワークもその対称構造を保ったまま層を追加して解像度を上げて行くこと↓
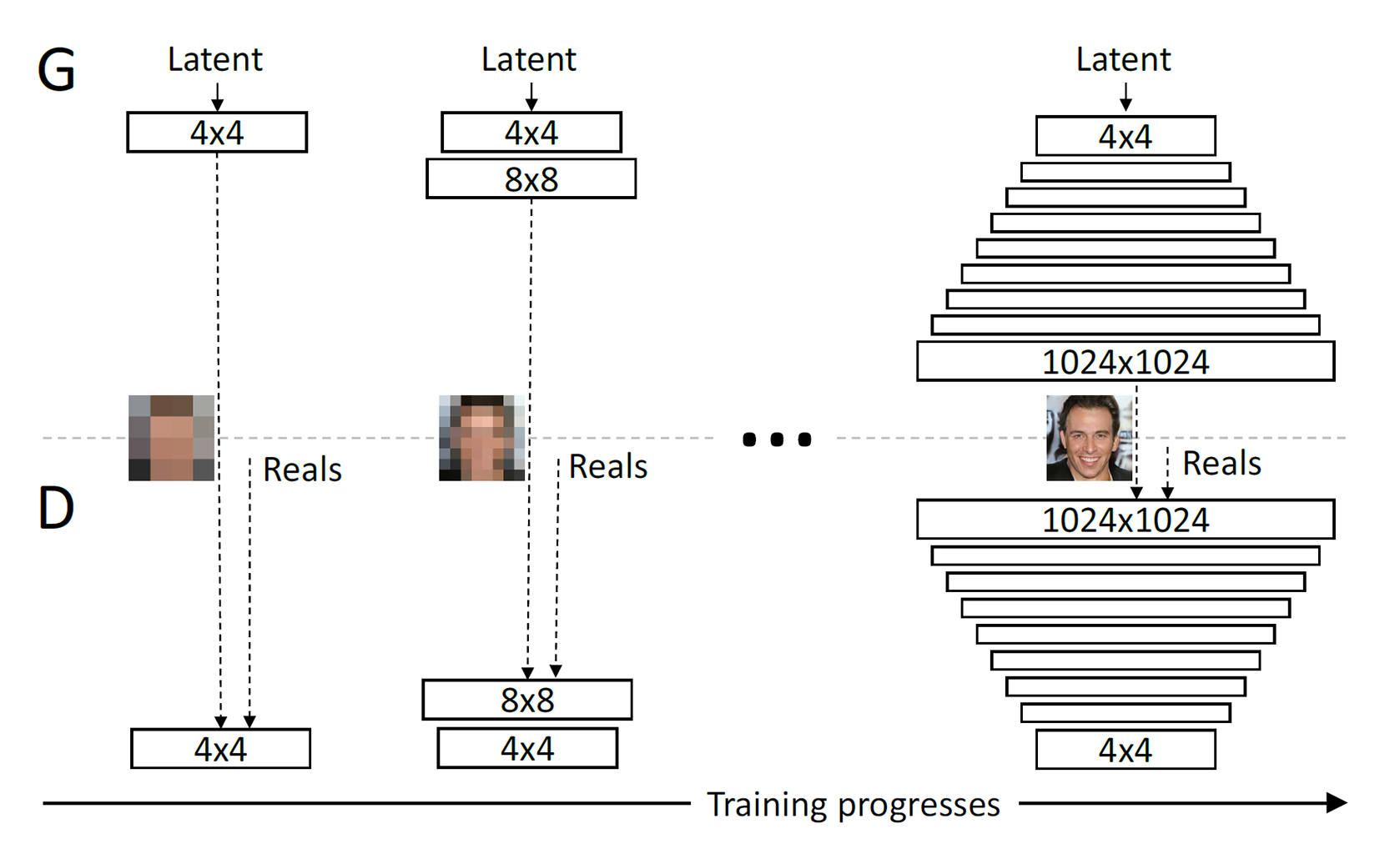
つまり、PGGANでは低解像度の画像生成から学習を始めて、学習が進むのに合わせてGenerator、Discriminatorそれぞれに段階的に解像度の高い畳み込み・転置畳み込み層を追加し、生成画像の解像度を上げていく。この方法によって、PGGANは学習を安定させて高解像度な画像を生成することが可能になった。
PGGANの学習過程
PGGANでは、まずGeneratorはノイズベクトルから4×4の画像を生成し、Discriminatorは入力された4×4の画像が生成画像か実画像かを識別する。この学習の流れは通常のGANの学習と同様だ。
その後、Generatorに転置畳み込み層を追加、Discriminatorに畳み込み層を追加する。
Generatorは8×8の画像を生成するように、Discriminatorは8×8の画像が生成画像か実画像かを識別するように学習する。
このように、学習が進むごとに段階的(縦・横2倍)に層の追加と高解像化を行っていき、最終的に1024×1024解像度まで学習を行う。
これにより、学習の初期段階では低解像度な画像で全体的な特徴を捉え、学習の進度に合わせて解像度を上げていくことで徐々に詳細部分を捉えていくことができる。
PGGANに施された工夫
実際に高解像度の画像を生成するには、単純に層を追加して解像度を上げていくだけでは不十分。PGGANでは、特徴マップの正規化方法やミニバッチの与え方、層の追加方法に工夫を施している。
Pixelwise Normalizationによる特徴マップの正規化
PGGANでは、畳み込み処理によって得られる特徴マップをPixelwise Normalizationという手法でピクセルごとに正規化している。Pixelwise Normalizationは以下の式のようになる↓
ax,yは正規化前の特徴マップのピクセル値、bx,yは正規化後の特徴マップのピクセル値、Nは特徴マップの数。
特徴マップをピクセルごとに正規化することで、特徴マップの値が発散するのを防ぐことができる。
Minibatch Standard Deviation
一般的にGANの学習では、GeneratorがDiscriminatorを騙せる平均的な画像の生成を習得してしまい、本物そっくりの画像生成を学習しない状態に陥ることがある。これは意図とは違う誤った学習だ。
この誤った学習を防ぐために、PGGANではGeneratorが多様な画像を生成できるように、Discriminator側にミニバッチ内のデータの多様性を知らせるMinibatch Standard Deviationという仕組みを導入している。
Minibatch Standard Deviationは、Discriminatorの中間層で、現在の入力画像の特徴ベクトルと、ミニバッチ内の残りの画像の特徴ベクトルとのノルムを算出し、それを元の特徴ベクトルに連結する。
これによって、Generatorに多様性を反映させるような勾配を伝搬させることができる。
層の追加方法
PGGANの学習では、畳み込み層、転置畳み込み層を追加する際に、単に層を追加するのではなく、以下の図のような処理を行っている。この図は16×16から32×32へ解像度が移り変わる際の例↓
G:Generator
D:DiscriminatortoRGB:特徴マップをRGB画像に変換する処理
fromRGB:RGB画像を特徴マップに変換する処理
2×:最近傍補間で解像度を拡大する処理
0.5×:平均値Poolingで解像度を縮小する処理
α:0〜1の範囲で線形増加する重み係数
1つ前の層で生成された特徴マップと、新たに追加された層で生成された特徴マップの解像度を合わせ、2つの特徴マップそれぞれに重みをかけて加算したものを出力特長マップとすることで、安定して画像生成ができるようになる。
PGGANの実装
NVIDIA公式でTensorFlowによる実装が公開されている↓
https://github.com/tkarras/progressive_growing_of_gans
こちらは有志によるPyTorch実装↓
https://github.com/nashory/pggan-pytorch
PGGANぐらいになると、もはやオイラの貧弱なGPU環境では試せないな。。。
PyTorch公式ページにGoogle Colab用のコードと学習済みモデルが公開されているようなので、ただ実行するだけならこっちで遊べば良いかな↓
https://pytorch.org/hub/facebookresearch_pytorch-gan-zoo_pgan/
ここまで何となく有名なGAN手法(もはや古典)を原著論文を読みながらおさらいしてきたけど、ここでいったん生成モデルの括りでオートエンコーダーや変分オートエンコーダーについて改めて勉強しようかな。
関連記事
Super Resolution:OpenCVの超解像処理モ...
この本読むよ
Stanford Bunny
Unityの各コンポーネント間でのやり取り
Boost オープンソースライブラリ
ツールの補助で効率的に研究論文を読む
TensorSpace.js:ニューラルネットワークの構造を...
python-twitterで自分のお気に入りを取得する
ZBrushのお勉強
チャットツール用bot開発フレームワーク『Hubot』
2D→3D復元技術で使われる用語まとめ
スクレイピング
フォトンの放射から格納までを可視化した動画
Maya LTでFBIK(Full Body IK)
MythTV:Linuxでテレビの視聴・録画ができるオープン...
PureRef:リファレンス画像専用ビューア
Seleniumを使ったFXや株の自動取引
Unityで画面タッチ・ジェスチャ入力を扱う無料Asset『...
Composition Rendering:Blenderに...
Model View Controller
AmazonEC2のインスタンスをt1.microからt2....
オープンソースの人体モデリングツール『MakeHuman』の...
PolyPaint
FacebookがDeep learningツールの一部をオ...
Theia:オープンソースのStructure from M...
UnityでLight Shaftを表現する
Open Shading Language (OSL)
フィーリングに基づくタマムシの質感表現
なんかすごいサイト
fSpy:1枚の写真からカメラパラメーターを割り出すツール
AR (Augmented Reality)とDR (Dim...
Unityで学ぶC#
Maya API Reference
Maya 2015から標準搭載されたMILA
参考書
ZBrush4新機能ハイライト 3DCG CAMP 2010
書籍『The Art of Mystical Beasts』...
Unity MonoBehaviourクラスのオーバーライド...
Adobeの手振れ補正機能『ワープスタビライザー』の秘密
ZBrushで仮面ライダー3号を造る 仮面編 ClipCur...
ニンテンドー3DSのGPU PICA200
立体視を試してみた

コメント