

一般物体検出の歴史からちょっと脇道に逸れて、ディープラーニングによるSemantic Segmentationについて勉強する。
Semantic Segmentation
画像の領域を分割するタスクをSegmentation(領域分割)と呼び、Semantic Segmentationは「何が写っているか」で画像領域を分割するタスクのことを指す。
画像を物体領域単位で分類する物体認識や物体検出に対して、Semantic Segmentationは画像をpixel単位でどのクラスに属するか分類する。そのためPixel-labelingとも呼ばれる。

もちろんディープラーニング以前から様々な手法が提案されている。
https://news.mynavi.jp/article/cv_future-35/
https://news.mynavi.jp/article/cv_future-36/
ディープラーニングによるSemantic Segmentationの概要については、2年前のPreferred Networksのセミナー動画が分かりやすい↓

スライドはこちら。
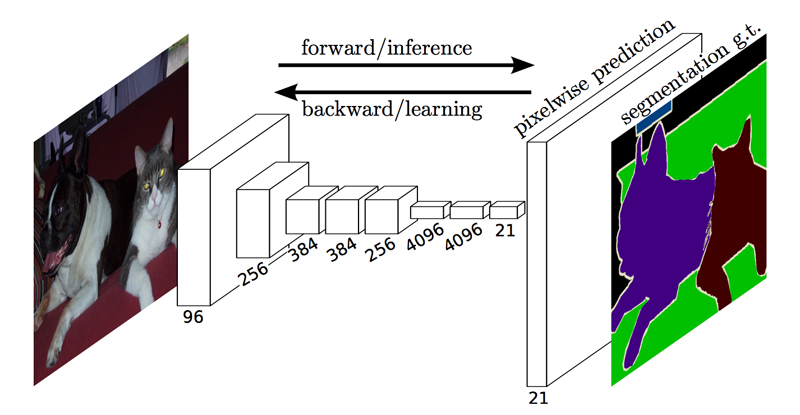
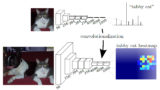
一般物体認識を行うニューラルネットワークでは、入力ユニット数が入力画像のサイズ、出力ユニット数は分類するクラス数だったが、Semantic Segmentationでは出力ユニット数は画像サイズ×分類クラス数となる。(入力ユニット数は同様に画像サイズ)
pixelごとにラベル付けされた教師データを与えて学習することで、入力画像の各pixelがどのクラスに分類されるかの確率を出力できるようになる。
まずはSemantic Segmentationにディープラーニングを使った最初の手法 FCN (Fully Convolutional Network)から勉強しよう。

FCN (Fully Convolutional Network)
FCN (Fully Convolutional Network)は、CVPR 2015, PAMI 2016で発表された Fully Convolutional Networks for Semantic Segmentationで提案されたSemantic Segmentation手法。

公式でCaffeによる実装も公開されている↓
https://github.com/shelhamer/fcn.berkeleyvision.org
FCNの大きな特長は、全結合層を持たず、ネットワークが畳み込み層のみで構成されていること。(だからFully Convolutional Networkと呼ばれる)
一般物体認識用のCNNをSemantic Segmentation用に改良する
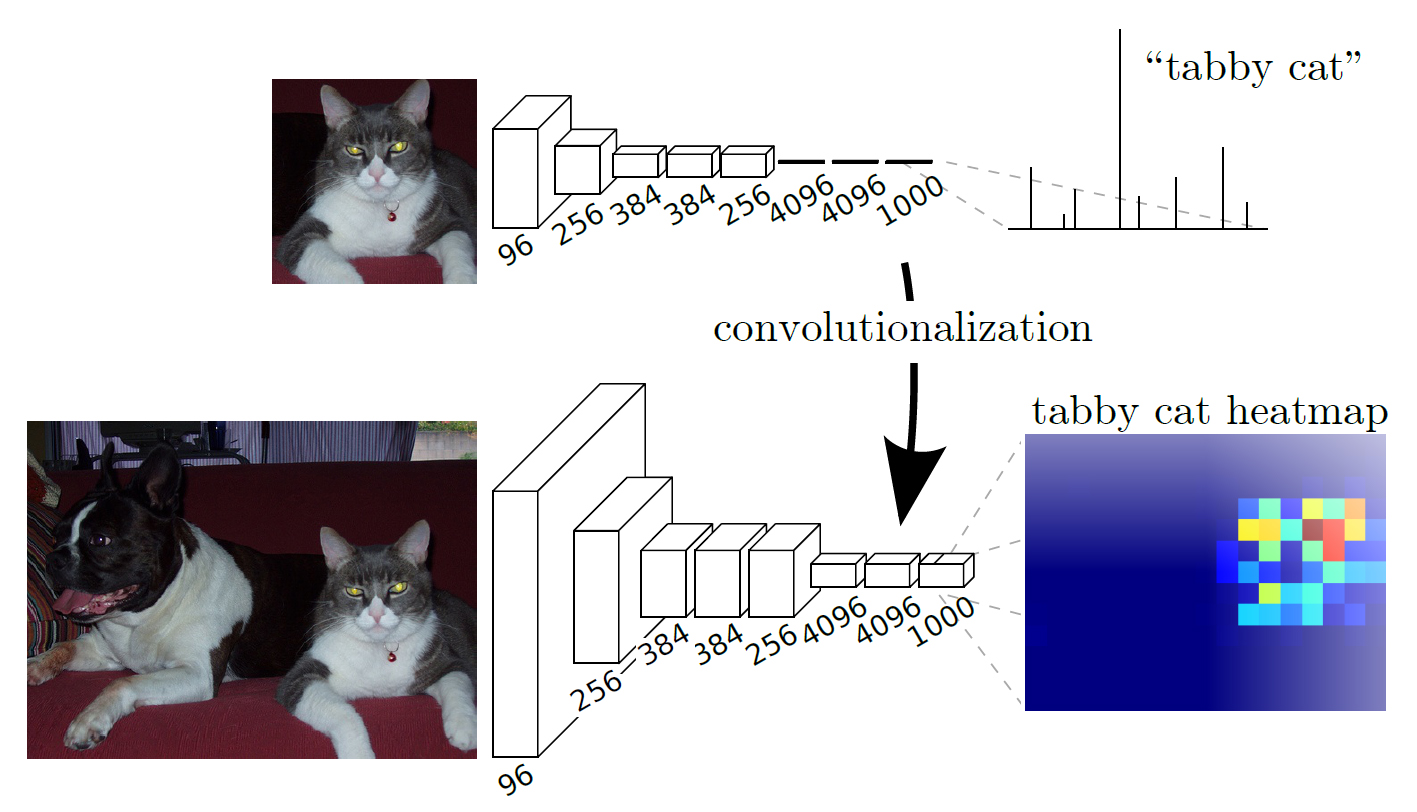
FCNでは、一般物体認識の畳み込みニューラルネットワーク(実装例ではVGG-16)の全結合層を1×1の畳み込み層に置き換えている。(実装例では、特徴抽出には一般物体認識向けにImageNetで学習したVGG-16の畳み込み層を流用してfine-tuningしている)
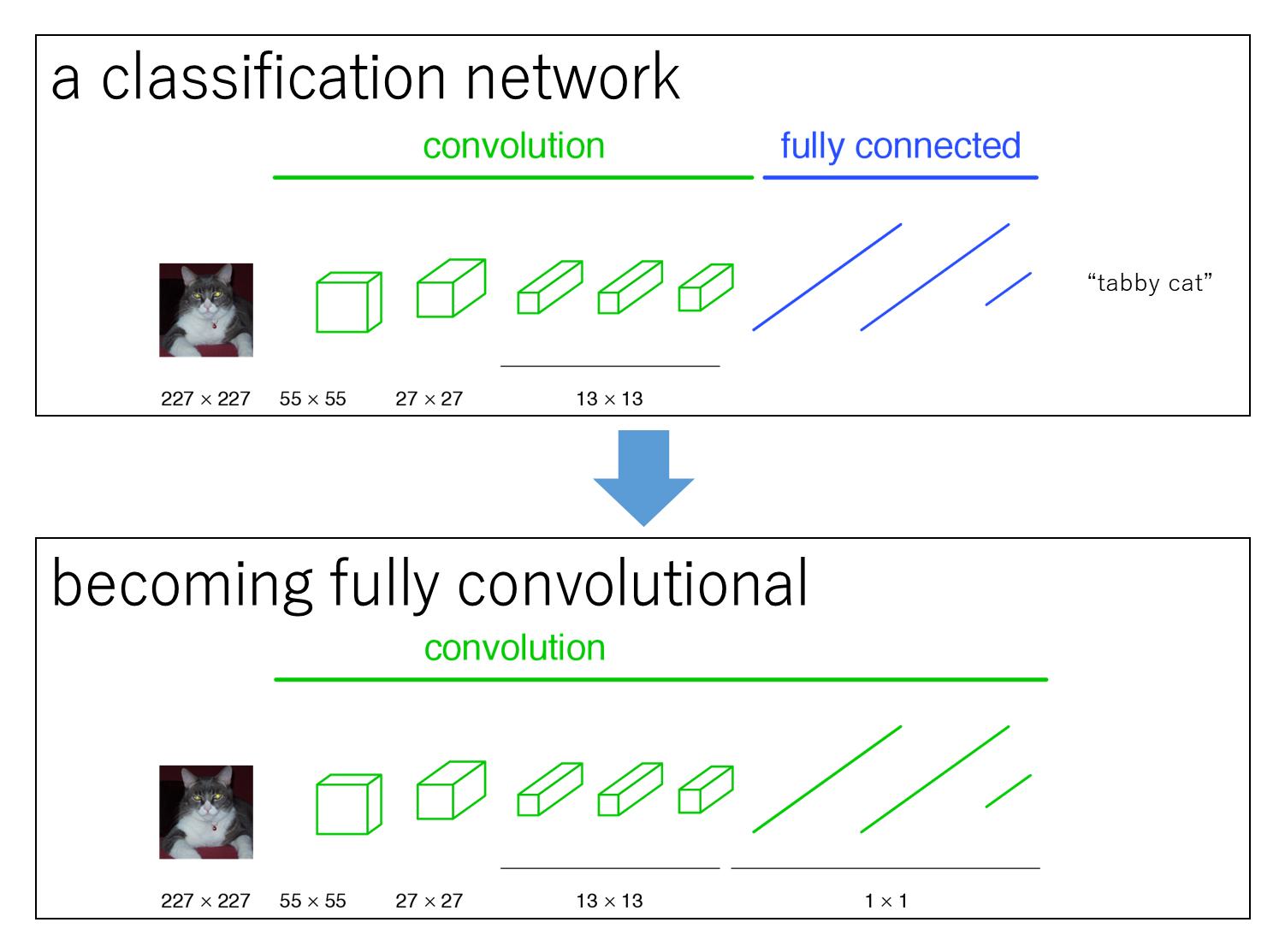
全結合層では、全pixelに対して接続しているノードごとに重みをかける処理を行っていた。これはつまり、ノードの数だけ1×1の畳み込みを行う処理と同等である。
全結合層を無くすことで、従来の畳み込みニューラルネットワークのように入力画像のサイズを固定する制約がなくなった。また、全結合層を畳み込み層に置き換えると、クラス分類の結果がヒートマップとして出力されるようになる。
スポンサーリンク
特徴マップのサイズはMaxプーリングを経て小さくなっているため、入力画像H×Wに対して特徴マップのサイズはH/32×W/32になっている。

アップサンプリング
そこで、小さくなった特徴マップを入力画像と同サイズにアップサンプリングしてpixel単位のクラス分類を行う。
逆畳み込み(Deconvolution)
アップサンプリングには逆畳み込み(Deconvolution)という処理を施す。
逆畳み込みと呼ばれているが、畳み込み(convolution)の逆プロセスというわけではない。そのため、誤解を生まないようup convolutionとかtransposed convolution(転置畳み込み?)などとも呼ばれる。
逆畳み込みのパラメータは畳み込みと似ており、kernel size, padding, strideにそれぞれpixel数を指定する。
逆畳み込みで実際に行われるのは、以下のように特徴マップを拡大してから畳み込む処理。
- 特徴マップの各pixelをstrideで指定したpixel数ずつ空けて配置し
- kernel size-1だけ特徴マップの周囲に余白を取り
- paddingで指定されたpixel数だけ余白を削り
- 畳み込み処理を行う
こちらのgifで具体的に見てみよう。(図中の青が入力、緑が出力)
kernel size=3, padding=0, stride=0の時の逆畳み込み↓

kernel size=3, padding=0, stride=1の時の逆畳み込み↓

kernel size=3, padding=1, stride=1の時の逆畳み込み↓

各pooling層の特徴マップを足し合わせる
特徴マップをアップサンプリングで入力画像と同サイズに拡大するだけではsemantic segmentationの結果は物体の境界がぼやけたものとなる。
そこで、特徴抽出の最終層だけでなく、途中のpooling層で出力される大きいサイズの特徴マップも活用する。特徴マップのサイズは各層で異なるので、最終層の特徴マップから順にアップサンプリングで前の層と同サイズに拡大し、チャンネルごとに足し算する。
以下の図は、VGG-16に5つあるpooling層の内、3~5番目の特徴マップを利用する例。
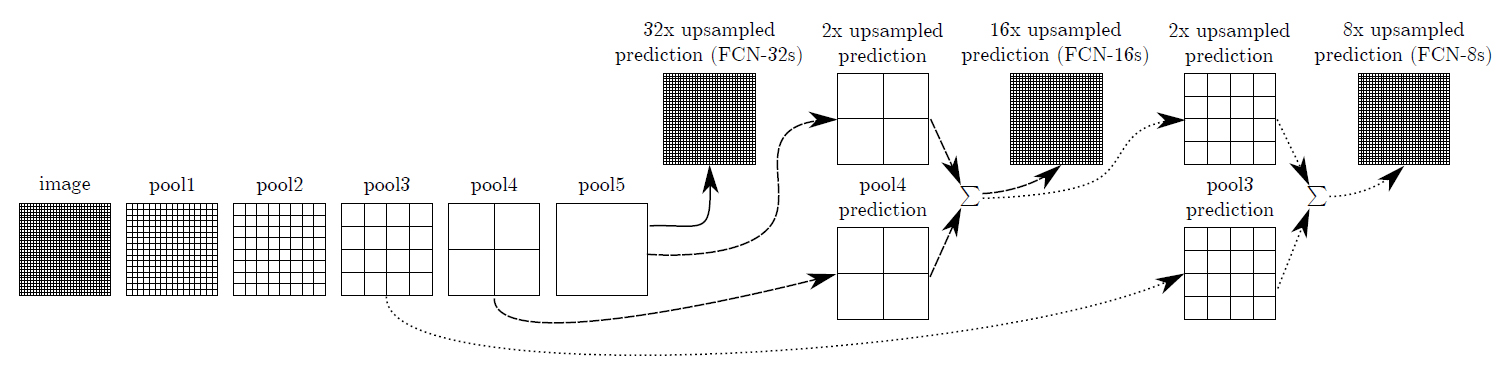
そして、足し算後の特徴マップに対して1×1の畳み込み処理を行う。
途中の層で出力されるサイズの大きい特徴マップを利用することで、物体の詳細な情報を捉えたsemantic segmentationが可能となる。(なんかSSDにも似てるな)
全体平均pooling
FCNの出力層の直前には全体平均poolingが導入されている。これにより、特徴マップの各チャンネルが特定の物体クラスを表すようになる。
サンプルコード
簡単に試せるサンプルコードを探してみたんだけど、データセットの読み込み回りでエラーになるコードが多くてしんどかった。(FCNは入力画像サイズが固定じゃなくなったとはいえ、どんなpixel数の画像でもOKというわけではなく、縦横がアップサンプリング層での拡大率の倍数である必要はある)
やっとシンプルなPyTorch実装のサンプルを見つけた↓(Readmeは中国語だけど)
https://github.com/bat67/pytorch-FCN-easiest-demo
次はSegNetを勉強しようか。



スポンサーリンク