

R-CNNに続き、Fast R-CNNのアルゴリズムについて勉強しよう。
再びこちらの系譜図を引用する↓



系譜図にはR-CNNとFast R-CNNの間にSPPnetというのがあるのでSPPnetについて軽く触れておく。
SPPnet
SPPnetは、ECCV2014で発表された論文 Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognitionで提案された手法。
R-CNNではSelective Searchで検出した領域候補をそれぞれ個別にCNNにかけて特徴抽出していたのに対し、SPPnetでは画像全体をCNNに入力して全体の特徴マップを抽出する。互いに重なる部分も多い2000個の矩形領域を個別にCNNにかける冗長性を排除したわけですね。
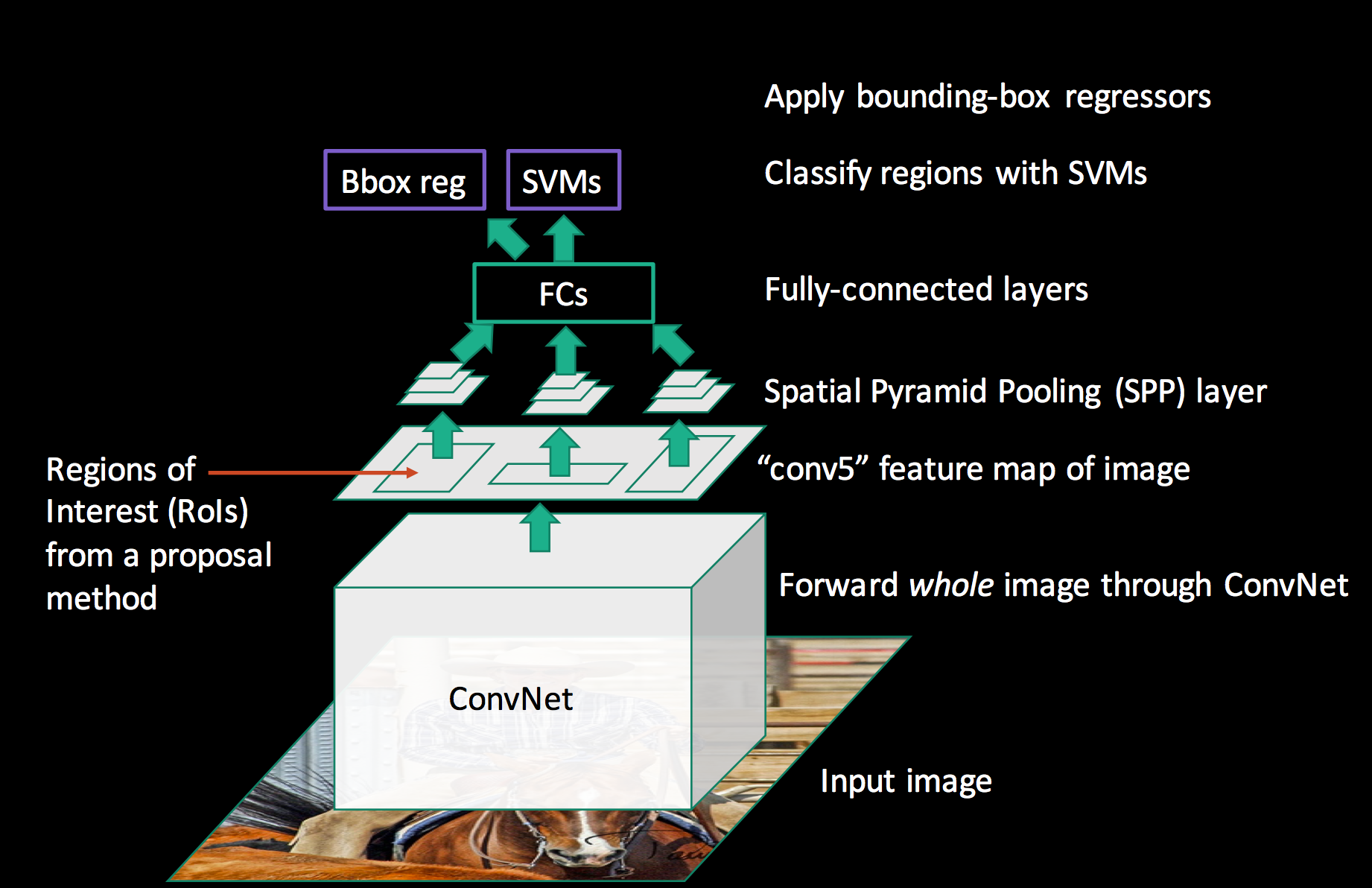
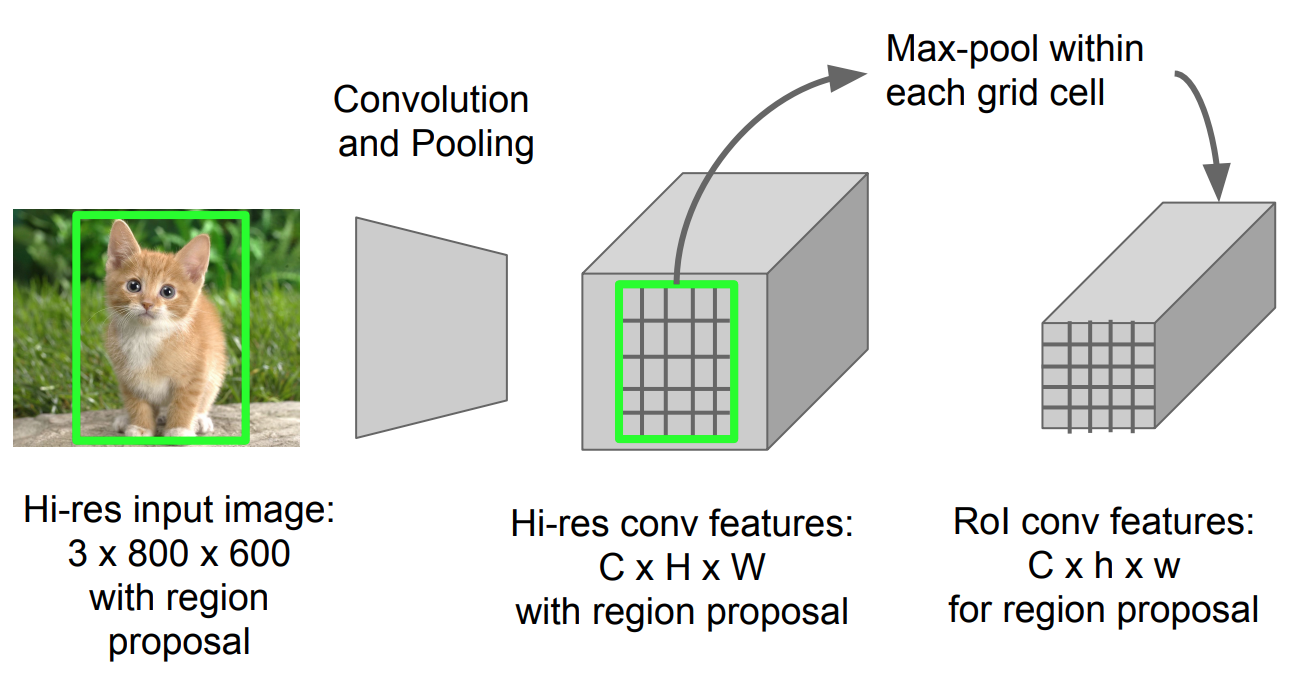
SPPnetの処理の全体像はこちらの図が分かりやすい↓

SPP(Spatial Pyramid Pooling)
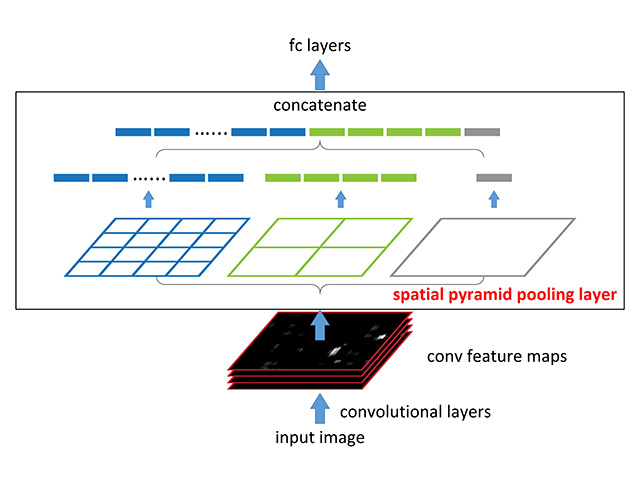
元画像からSelective Searchで検出した矩形に対応する特徴マップの領域にSpatial Pyramid Pooling(空間ピラミッドプーリング)と呼ばれるpooling処理を施す。このSpatial Pyramid Poolingにより、矩形領域のサイズに関わらず固定長のベクトルを得ることができる。
Spatial Pyramid Poolingでは、特徴マップを異なるサイズのウィンドウ(16×16, 4×4, 1×1)でmax-poolingした結果を平坦化して連結し、固定長のベクトルにしてから次の全結合層の入力とする。

そして、全結合層からの出力をR-CNNと同様にSVMで分類(Classification)、回帰(Regression)でBounding Boxを求める。
SPPnetの欠点
R-CNNに比べてCNNによる特徴抽出の処理は効率化したが、特徴量を抽出する畳み込み層、全結合層、候補領域を分類するSVMやBounding Boxの回帰などは別々に学習しなければならないまま。
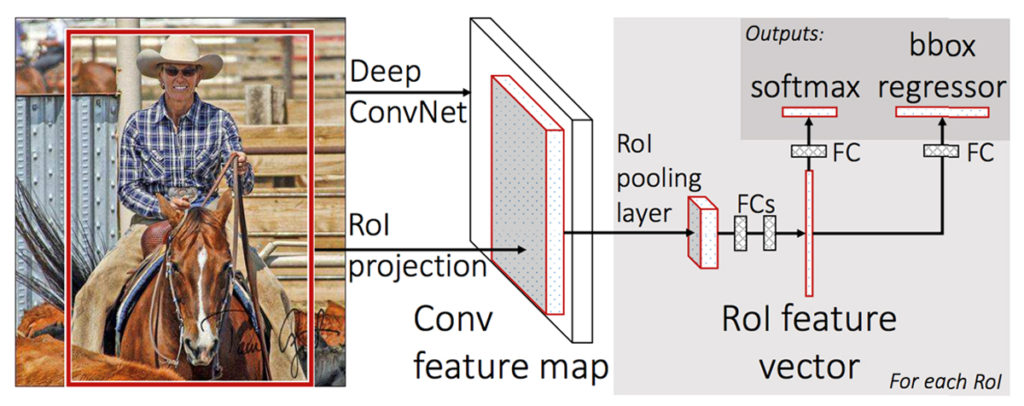
Fast R-CNN
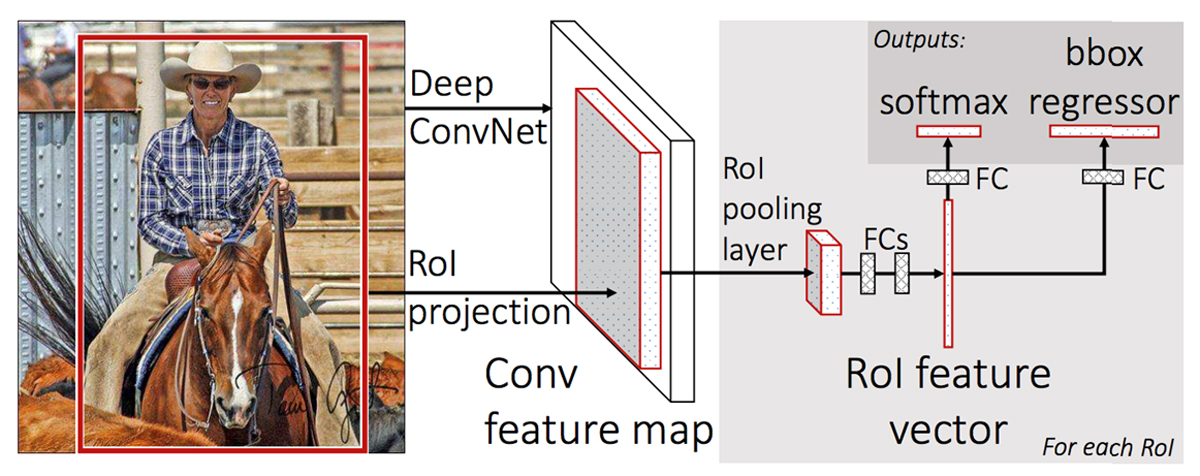
R-CNNと同じ著者(Ross Girshick氏)がICCV2015で発表したFast R-CNNは、画像全体からCNN(ここではVGGを利用)で特徴マップを抽出するまではSPPnetと同様。違うのはこちらのスライドで言うと3~5のプロセス↓
ここからはRegion Proposal(候補領域)という言葉に代わってRegion of Interest(関心領域)という言葉が使われるけど、分類(Classification)対象となる領域を指しているので同じ意味です。
スポンサーリンク
RoI (Region of Interest) Pooling
Fast R-CNNでは、SPP(Spatial Pyramid Pooling)のピラミッドレベルを1つに簡略化したRoI(Region of Interest)Poolingによって検出領域を固定サイズのベクトルに収める。

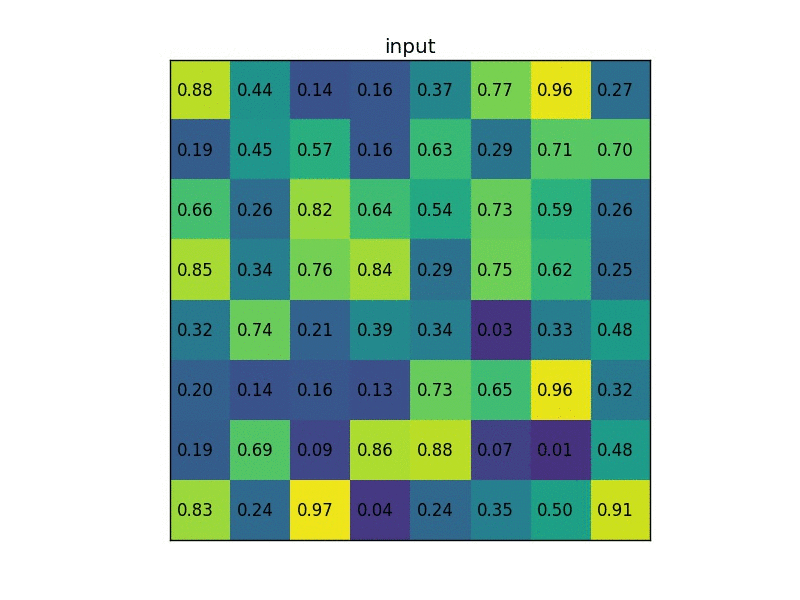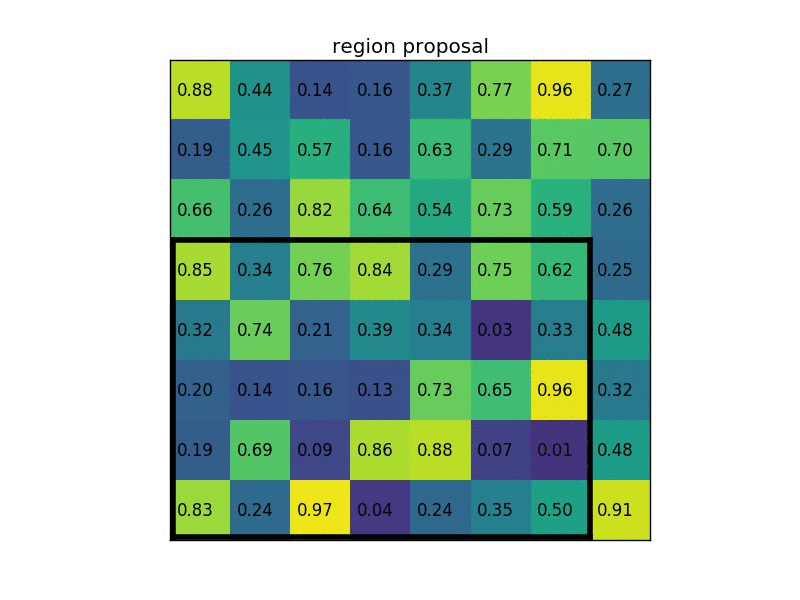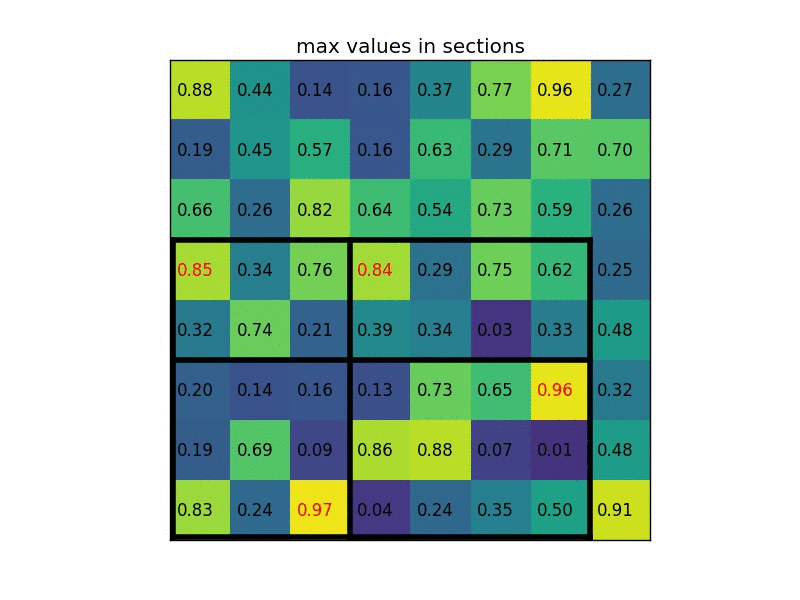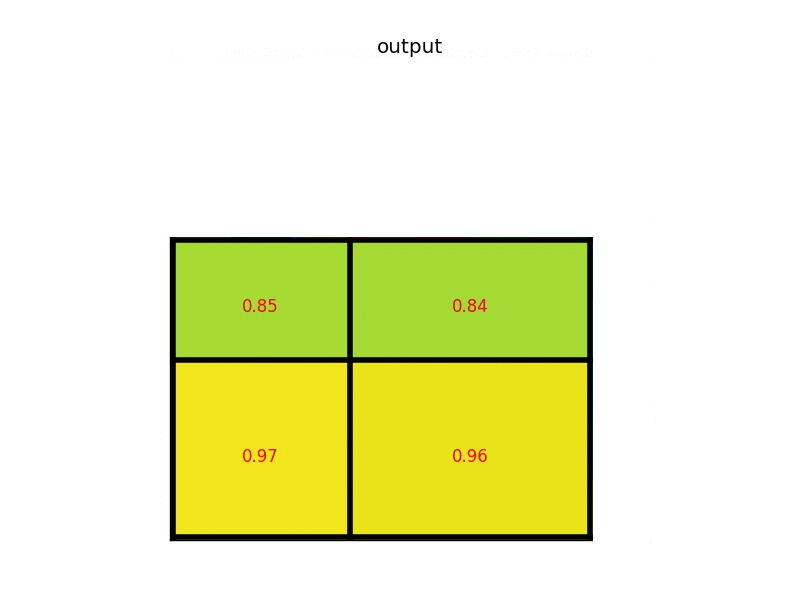
RoI Poolingは、アスペクト比の違いを考慮してMax Poolingを行う処理。
こちらのgifが分かりやすいか(オープンソースのRoIプーリング実装のページの画像)↓

ニューラルネットワークの分岐
RoI Poolingによって固定サイズ化された領域は、全結合層(Fully connected layers)を経てRoI feature vector(RoI特徴ベクトル)となる。このRoI feature vectorを、以下2つの全結合層の入力とする。
- 候補領域(物体)の分類(Classification)タスクを学習する全結合層
- Bounding Boxの回帰(Regression)タスクを学習する全結合層
つまり、ここからニューラルネットワークが2つに分岐し、タスクごとの全結合層を経て出力層へ向かう。

Multi-task Loss
物体の分類とBounding Boxの回帰という2つのタスク(Multi-task)を学習するために、この2のタスクの推定誤差を同時に考慮した損失関数(loss function) Multi-task Lossが提案された。
Multi-task Lossを最小化するようニューラルネットワークを学習することで、2つのタスクを同時に習得させることができる。
ここで改めてFast R-CNNのニューラルネットワークの構造を見てみると、R-CNNやSPPnetでは特徴抽出のCNNと分類や回帰の学習が独立していたのに対し、Fast R-CNNでは分類・回帰の学習も同じニューラルネットワークとして繋がっていることが分かる↓

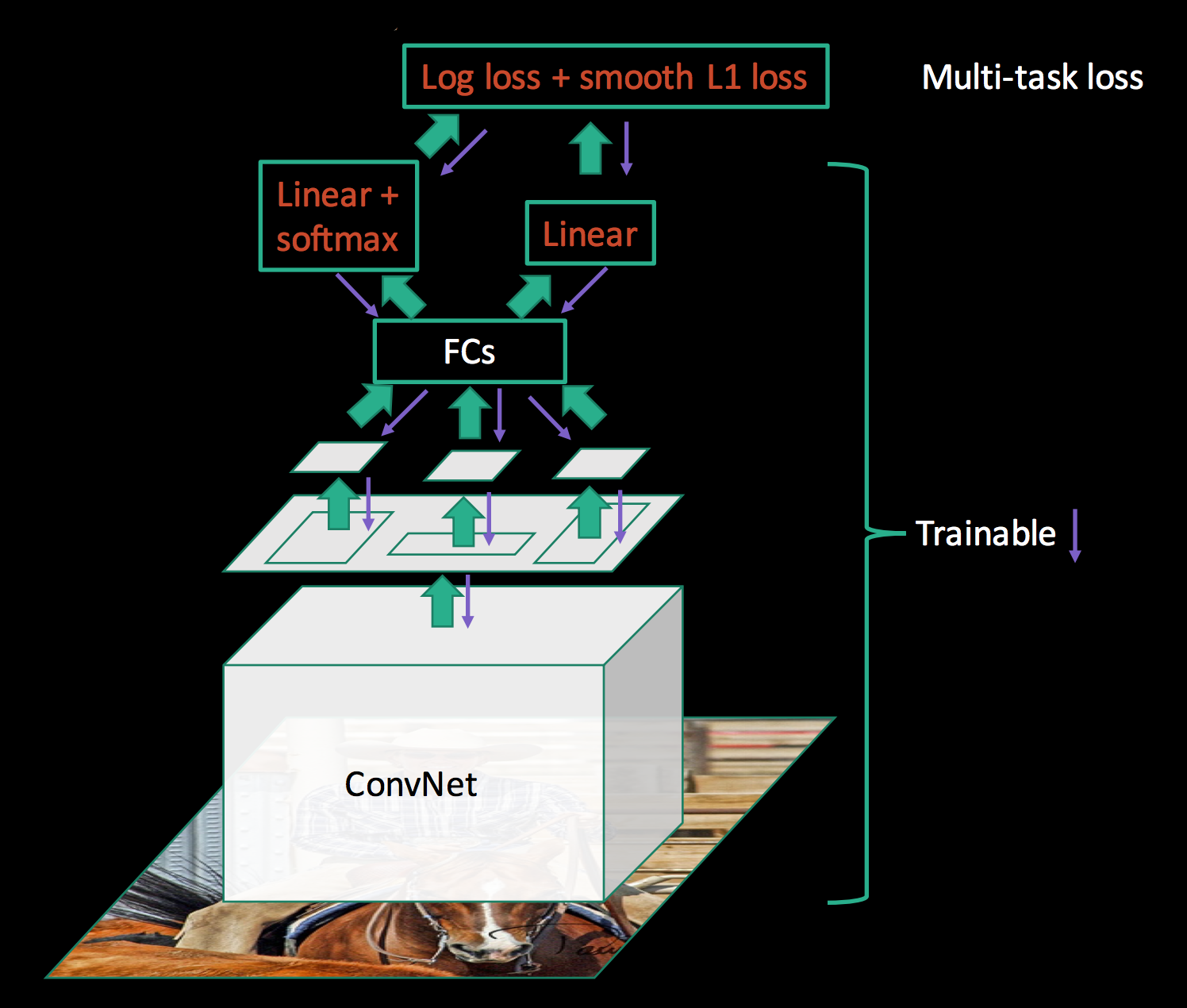
特徴抽出からタスクの学習までが1つのニューラルネットワークに繋がったことで、紫の矢印のように誤差逆伝搬で学習時にネットワークの全てのパラメーターが更新されるようになった。
Fast R-CNNの欠点
さて、特徴抽出から分類・回帰までを一貫したニューラルネットワークにしたことで、R-CNNの頃よりも遥かに効率化しました。
しかし、冒頭の系譜図にもあったようにFast R-CNNがNOT End-to-Endなアプローチに分類される理由は、RoIを求める処理がニューラルネットワークとは独立してSelective Searchで行われているからなのです。
次はFaster R-CNNについてまとめようと思う。

スポンサーリンク