
FCN, SegNet, U-Net, PSPNetに引き続き、ディープラーニングによるSemantic Segmentation手法のお勉強。
次はRefineNet (Multi-Path Refinement Network)について。
RefineNet (Multi-Path Refinement Network)
RefineNet(Multi-Path Refinement Network)は、CVPR 2017で発表されたRefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentationで提案されたSemantic Segmentation手法。RefineNetもEncoder–Decoder構造で設計されている。
これまで、CNNベースのSemantic Segmentation手法は、Encoderで特徴マップを抽出する過程でsub-sampling(down-sampling)を頻繁に行うため、画像のディティールが失われてしまう欠点があった。(そしてそれを克服する方法が模索されてきた)
この問題に対し、RefineNetではEncoderの各層で出力される解像度の違う特徴マップを段階的に結合するアプローチを取り、各ステップで行う畳み込み処理にResNet (Residual Network)のresidual connection(skip connection)の仕組みを採用することで学習効率を高めている。
RefineNetのネットワーク構造
RefineNetはEncoderにImageNetで学習済みのResNet101を利用する。ResNet101の各層から出力される特徴マップを解像度ごと(元の画像の1/4, 1/8, 1/16, 1/32)に4つに分け、それぞれのサイズの特徴マップをDecoderへの入力とする。
Decoderには、入力される各サイズの特徴マップに対応して4つのRefineNet block (RefineNet-1, RefineNet-2, RefineNet-3, RefineNet-4)があり、小さい解像度の特徴マップから段階的にRefineNet blockを適用してアップサンプリング・連結していき、画像のディティールを捉えられるよう工夫されている。
そして、最終的に得られるSemantic Segmentation結果(元画像の1/4の解像度)を、バイリニア補間で元の画像サイズへアップサンプリングする。
RefineNet block
上記図中の1番下で最低解像度(1/32)の特徴マップを入力するRefineNet block (RefineNet-4)のみ1pathの入力で、他のRefineNet block (RefineNet-1~3)は2path入力となっているが、4つのRefineNet blockは基本的に同じ構造をしている。
RefineNet blockは、任意の解像度・チャンネル数の特徴マップを任意の枚数入力できるよう一般化した設計となっている↓
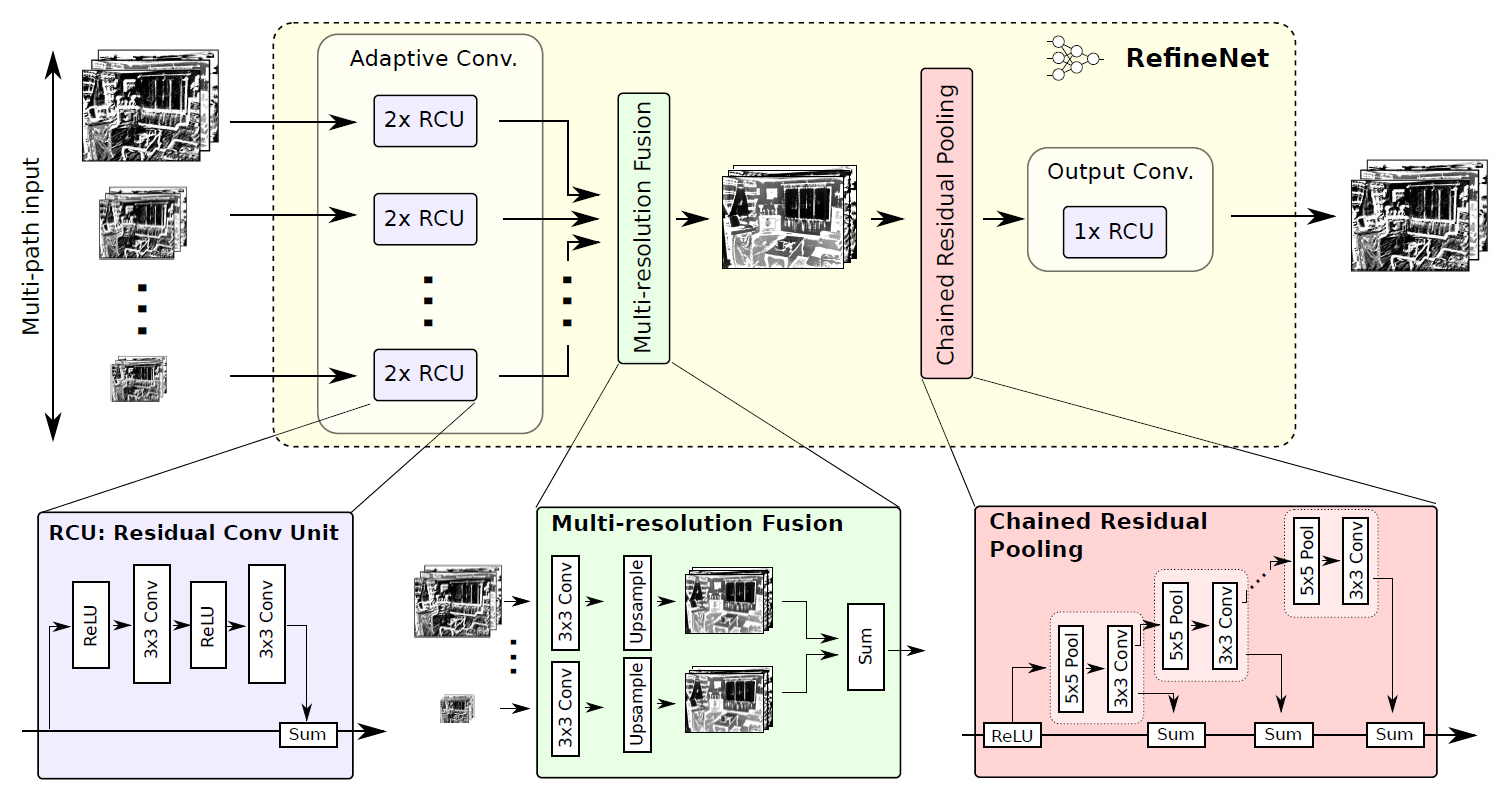
Adaptive Conv
RefineNet blockの内部では、まずImageNetで学習済みのResNetの重みをSemantic Segmentationタスク用にfine-tuningするためのAdaptive Conv (Adaptive Convolution Set)がある。

RCU (Residual Conv Unit)
Adaptive Convには、ResNetのResidual ModuleからBatch Normalizationを無くして単純化したRCU (Residual Convolution Unit)が2つあり、入力された各特徴マップを畳み込む。
ここで適用される畳み込みフィルタの数はRefineNet blockごとに変えており、入力が1pathのみのRefineNet-4では512、それ以外(RefineNet-1~3)では256に設定されている。
Multi-Resolution Fusion
次に、入力された2つの特徴マップをMulti-Resolution Fusionで結合する。(入力が1Pathの場合は何もせずにMulti-Resolution Fusionを通過する)
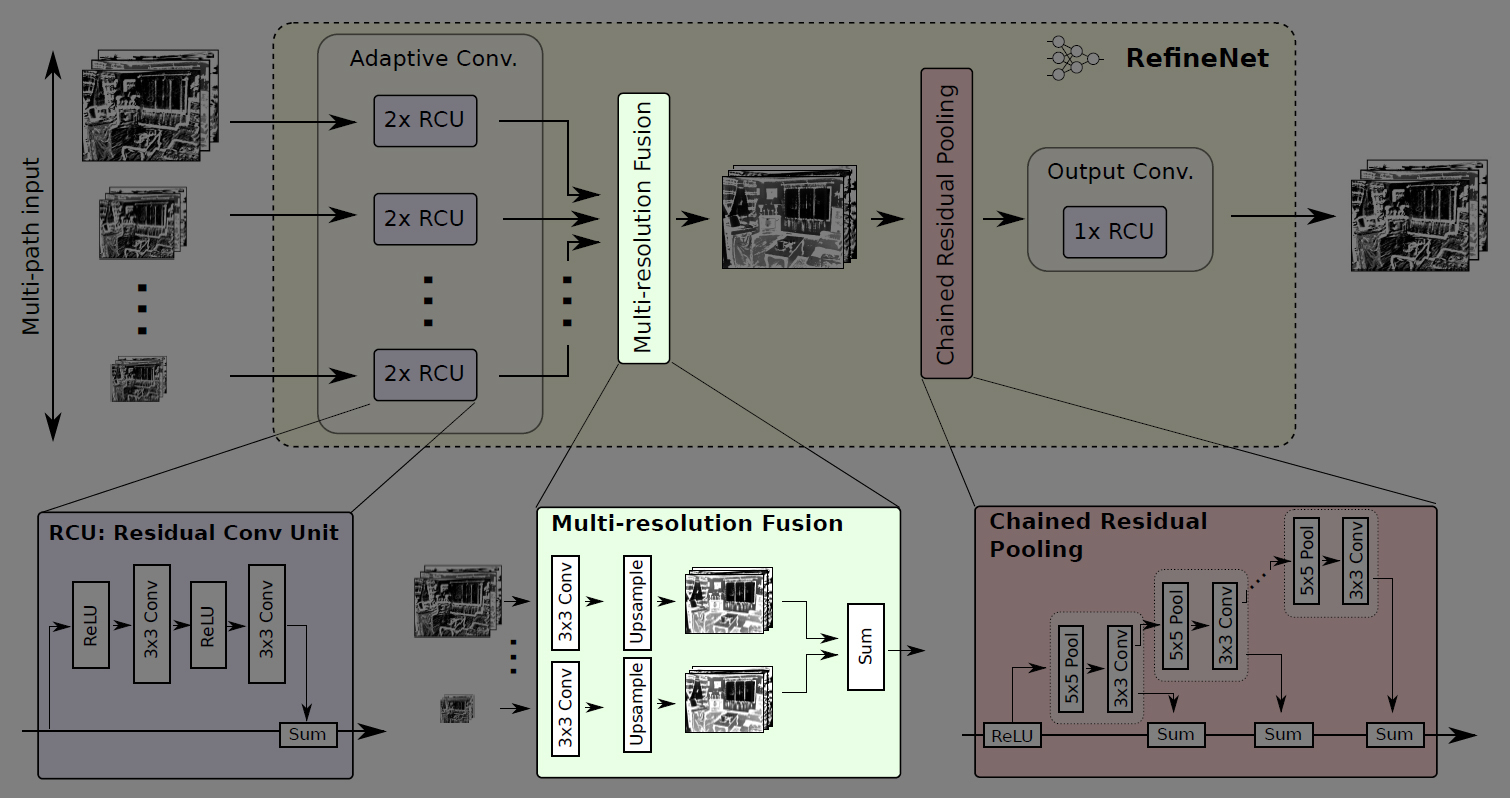
Multi-Resolution Fusionでは、まず2つの特徴マップのチャンネル数を揃えるために畳み込みを行った後、解像度の大きい方の特徴マップに合わせて小さい方の特徴マップをアップサンプリングする。
そして、同じチャンネル数・解像度になった2つの特徴マップを結合して高解像度な特徴マップを得る。
Chained Residual Pooling
次に、Chained Residual Poolingで画像の広い範囲から背景のコンテキストを捉える。
Chained Residual Poolingは複数のpooingブロックを連鎖する構成になっており、1つのpoolingブロックが5×5のmax pooling層と3×3の畳み込み層のセットで構成されている。
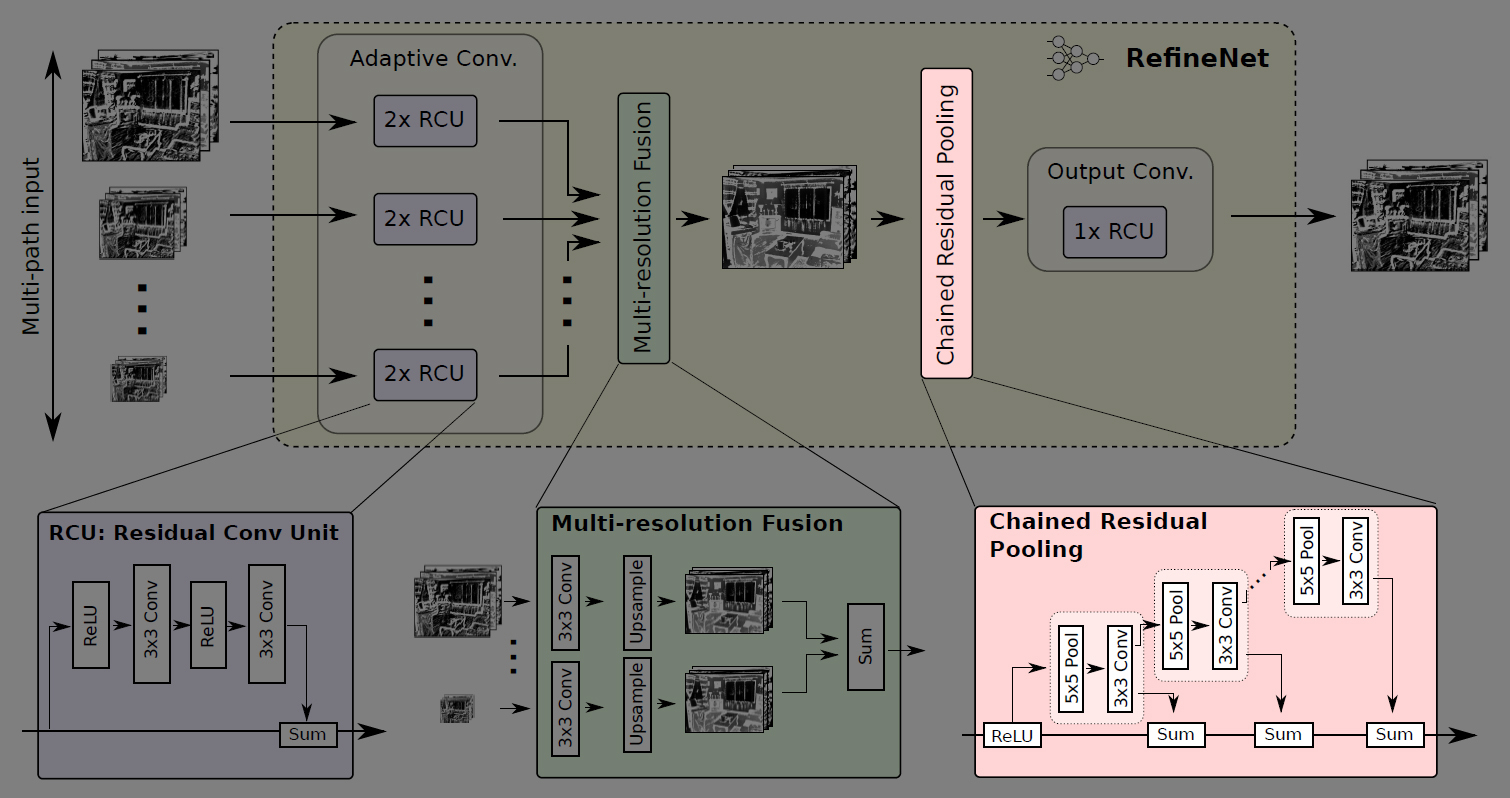
Chained Residual Poolingでは、前のpoolingブロックの出力を次のpoolingブロックの入力とする階層構造により、前のpooling結果を再利用している。これによって、大きなpoolingウィンドウを使用しなくても、画像の大域的な特徴を捉えることができる。ここで行うpoolingのstrideは1なので、特徴マップのサイズは変わらない。
各poolingブロックから出力される特徴マップは、residual connectionによるsum(足し合わせ)で統合される。足し合わせる際の重みは各poolingブロックの最後の畳み込み層で学習する。
Output Conv
RefineNet blockの最後に、もう1つRCU (Residual Conv Unit)がある。つまり、各RefineNet blockには合計3つのRCUが配置されている。
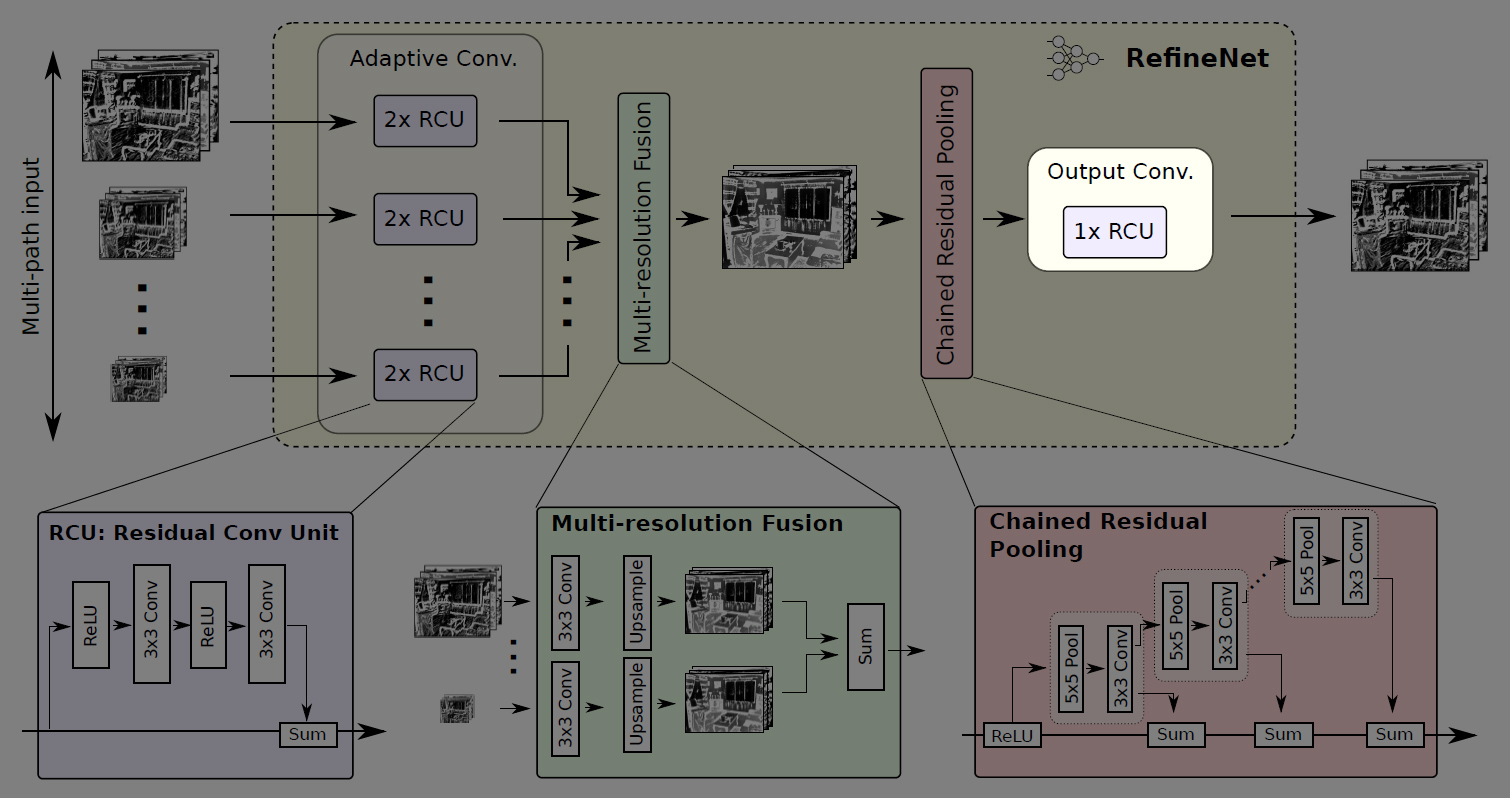
各RefineNet block (RefineNet-2~4)での振る舞いを最後のRefineNet block (RefineNet-1)に反映させるために、ネットワークの最終層のSoftmax関数の前にRCUを2つ追加する。
こうして各RefineNet blockで段階的にアップサンプリング・結合した特徴マップに非線形関数を適用して最終的な特徴マップを得る。
サンプルコード
例のごとくPyTorchの実装例↓
https://github.com/thomasjpfan/pytorch_refinenet
次は再び一般物体検出に戻ってMask R-CNNについて勉強しよう↓

関連記事
3D復元技術の情報リンク集
NumSharp:C#で使えるNumPyライクな数値計算ライ...
Zibra Liquids:Unity向け流体シミュレーショ...
Deep Fluids:流体シミュレーションをディープラーニ...
UnityでPoint Cloudを表示する方法
OpenCVでiPhone6sのカメラをキャリブレーションす...
ポイントクラウドコンソーシアム
OpenCVで顔のモーフィングを実装する
OpenGV:画像からカメラの3次元位置・姿勢を推定するライ...
TensorSpace.js:ニューラルネットワークの構造を...
Houdiniのライセンスの種類
Kinect for Windows V2のプレオーダー開始
OpenCV3.3.0でsfmモジュールのビルドに成功!
viser:Pythonで使える3D可視化ライブラリ
Fast R-CNN:ディープラーニングによる一般物体検出手...
SSD (Single Shot Multibox Dete...
NeRF (Neural Radiance Fields):...
Netron:機械学習モデルを可視化するツール
OpenMVSのサンプルを動かしてみる
PyDataTokyo主催のDeep Learning勉強会
OpenCV 3.1のsfmモジュールのビルド再び
VGGT:マルチビュー・フィードフォワード型3Dビジョン基盤...
OpenCVで平均顔を作るチュートリアル
OpenMVS:Multi-View Stereoによる3次...
書籍『仕事ではじめる機械学習』を読みました
Mitsuba 3:オープンソースの研究向けレンダラ
統計的な顔モデル
SegNet:ディープラーニングによるSemantic Se...
fSpy:1枚の写真からカメラパラメーターを割り出すツール
オープンソースの顔認識フレームワーク『OpenBR』
Runway ML:クリエイターのための機械学習ツール
DCGAN (Deep Convolutional GAN)...
AfterEffectsプラグイン開発
機械学習での「回帰」とは?
OpenAR:OpenCVベースのマーカーARライブラリ
FreeMoCap Project:オープンソースのマーカー...
OpenGVのライブラリ構成
Paul Debevec
U-Net:ディープラーニングによるSemantic Seg...
ドットインストールのWordPress入門レッスン
ベイズ推定とグラフィカルモデル
OpenCV

コメント