
カーネギーメロン大学が公開している2D画像からの人体骨格推定ライブラリOpenPoseの元の研究である”Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields“が発表されて以降、2D画像・動画からの骨格推定の研究とソースコードの公開が活発な印象。
DensePoseは、骨格ではなく、動画中の人物領域の3DサーフェスのUV座標を推定するという、とても具体的なタスクの研究。面白そうなので論文がarXivに公開されてからすぐに読んだのでした。
ただ、CGに詳しくない人には課題設定がピンと来ないんじゃないかな。
DensePose: Dense Human Pose Estimation In The Wild
Dense human pose estimation(密な人体姿勢推定)は、画像中の人物のRGB画素全てを3Dの人体サーフェスへマッピングすることを目的としています。
- 5万枚のCOCOデータセットの画像に対して人力で2D画像と3Dサーフェスの対応関係をアノテーションした大規模なground-truthデータセット「DensePose-COCO」を提案します。
- Mask-RCNNを改良し、動画の毎秒複数フレームに写るそれぞれの人物領域の各人体パーツのUV座標を密に回帰推定する「DensePose-RCNN」を提案します。
DensePose-COCOデータセットも公開予定だそうです。
https://github.com/arXivTimes/arXivTimes/issues/638
ソースコードがGitHubで公開されましたね↓
https://github.com/facebookresearch/DensePose
Dockerfileもあるので試すのは楽か?
2018年12月 追記:試した方がいます↓
http://whoopsidaisies.hatenablog.com/entry/2018/12/03/193759
これって、顔画像で言うところのFace Alignmentに近い役割ができて、Body Alignmentって言っても良さそう。
画像中から人物表面のUV座標が推定できれば、身体の模様(つまり服装)を比べたり、入れ替えたり、描き替えたりできるんですよね。
著者にFacebook AI Researchの人が2人入ってるけど、やっぱり目指すのは画像からの個人識別なんですかね。
https://research.fb.com/facebook-open-sources-densepose/
https://shiropen.com/seamless/facebook-ai-densepose
論文では、データセットを作るためのアノテーションツールを設計と、アノテーションの質の評価についても載っている。
ちゃんと解きたいタスクに適したデータセットを用意して、タスクに適したネットワークを設計する、ってのが機械学習の良いアプローチなのだろうか。
機械学習でOverfitting(過学習)と呼ばれる現象は、データセットとタスクのギャップと言えるのかもしれない。
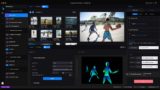
2019年追記:最近はRunway MLというツールで手軽にDensePoseを試すことができるぞ↓
関連記事
Math Inspector:科学計算向けビジュアルプログラ...
ドットインストールのWordPress入門レッスン
フリーで使えるスカルプト系モデリングツール『Sculptri...
iPhoneアプリ開発 Xcode 5のお作法
UnityのGlobal Illumination
スターウォーズ エピソードVIIの予告編
OpenCVでカメラ画像から自己位置認識 (Visual O...
ZBrushでアヴァン・ガメラを作ってみる 全体のバランス調...
Live CV:インタラクティブにComputer Visi...
「ベンジャミン·バトン数奇な人生」でどうやってCGの顔を作っ...
ZBrush 2021.6のMesh from Mask機能...
ラクガキの立体化 反省
MB-Lab:Blenderの人体モデリングアドオン
組み込み向けのWindows OS 『Windows Emb...
ZBrushで人型クリーチャー
映画から想像するVR・AR時代のGUIデザイン
参考になりそうなサイト
ZBrush 2018での作業環境を整える
Connected Papers:関連研究をグラフで視覚的に...
Mask R-CNN:ディープラーニングによる一般物体検出・...
ラクガキの立体化 1年半ぶりの続き
HD画質の無駄遣い
ベイズ推定とグラフィカルモデル
ファンの力
Netron:機械学習モデルを可視化するツール
UnityのAR FoundationでARKit 3
UnityでTweenアニメーションを実装できる3種類の無料...
日立のフルパララックス立体ディスプレイ
Google製オープンソース機械学習ライブラリ『Tensor...
ハリウッド版「GAIKING」パイロット映像
Cartographer:オープンソースのSLAMライブラリ
MPC社によるゴジラ(2014)のVFXブレイクダウン
ブログのデザイン変えました
書籍『ゼロから作るDeep Learning』で自分なりに学...
3DCG Meetup #4に行ってきた
OpenCVでiPhone6sのカメラをキャリブレーションす...
Seleniumを使ったFXや株の自動取引
白組による『シン・ゴジラ』CGメイキング映像が公開された!
OpenCVでPhotoshopのプラグイン開発
顔追跡による擬似3D表示『Dynamic Perspecti...
ArUco:OpenCVベースのコンパクトなARライブラリ
中学3年生が制作した短編映像作品『2045』

コメント