FCN, SegNet, U-Netに引き続きディープラーニングによるSemantic Segmentation手法のお勉強。

次はPSPNet (Pyramid Scene Parsing Network)について。
PSPNet (Pyramid Scene Parsing Network)
PSPNet (Pyramid Scene Parsing Network)はCVPR 2017で発表されたPyramid Scene Parsing Networkで提案されたSemantic Segmentation手法。
SegNetやU-Netの登場以降、ディープラーニングによるSemantic SegmentationではEncoder–Decoder構造が定番となった。
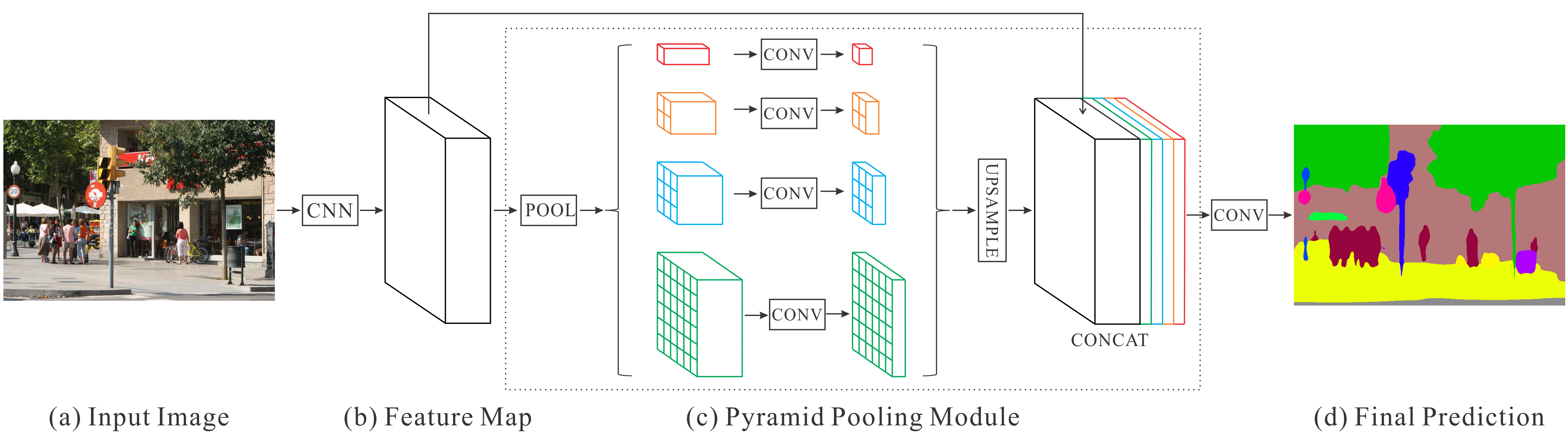
PSPNetでは、EncoderにResNet101(大規模データで学習済み)の特徴抽出層を利用しており、EncoderとDecoderの間にPyramid Pooling Moduleを追加している↓
Fast R-CNNの記事で触れたSPPNetで、似た名前のSpatial Pyramid Pooling(空間ピラミッドプーリング)が使われていた。
同じなのは複数の解像度でmax-poolingを行うという点だけです(笑)
Pyramid Pooling Module
Encoderによって入力画像から抽出された特徴マップのサイズは、ダウンサンプリングされて元の入力画像の1/8になる。
Pyramid Pooling Moduleでは、Encoderで抽出された特徴マップに対して、複数の解像度でmax-poolingをかけてそれぞれのスケールで捉えた特徴マップを得る。これによって、画像の大域的なコンテキストと小さな部分の情報の両方を拾うことができる。
Pyramid Pooling Moduleの階層数や各階層での特徴マップのサイズは、入力される特徴マップのサイズに合わせて設計する。Pyramid Pooling Moduleの階層の数をNとすると、削減後の各特徴マップのチャンネル数は1/Nになる。
論文の例では、以下の図のように階層的に4つの異なるカーネルサイズ(1×1, 2×2, 3×3, 6×6)でmax-poolingを行い、得られた複数スケールの特徴マップを1×1で畳み込んでチャンネル数を削減する。
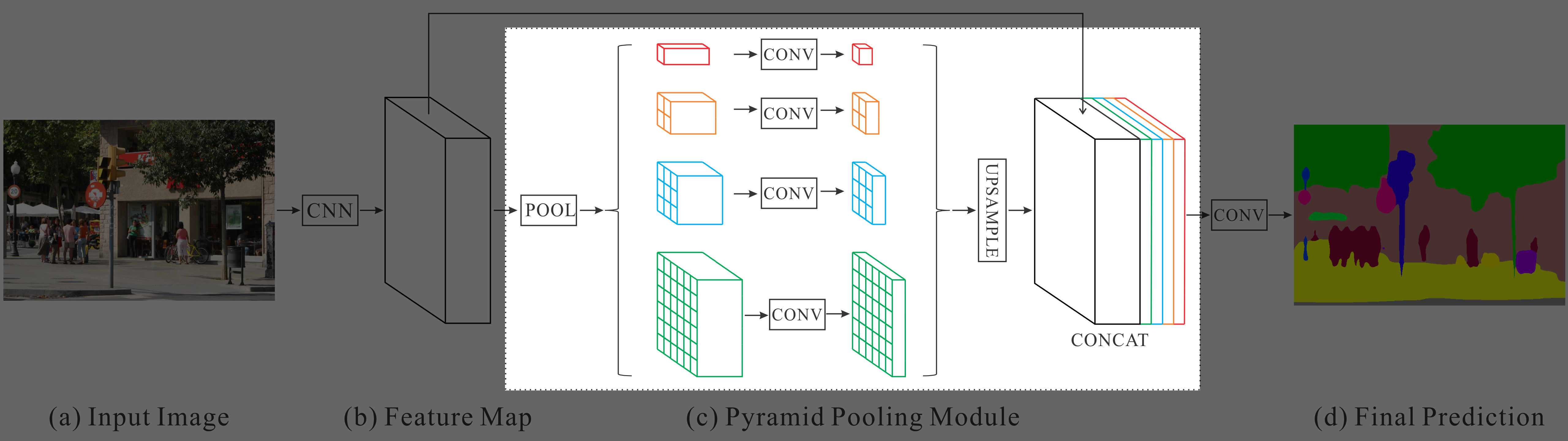
そして、このチャンネル数を削減した特徴マップをバイリニア補間で元の特徴マップと同じサイズにアップサンプリングする。
アップサンプリングしたこれらの特徴マップを元の特徴マップにチャンネルを追加する形で連結し、大域的なコンテキストと局所的な情報の両方を持った特徴マップとする。
最終的に、この連結した特徴マップに対して1×1の畳み込みを行ってSemantic Segmentationの結果を得る。
あれ、何か妙に情報があっさりだぞ。。。
次はRefineNet (Multi-Path Refinement Network)について勉強しよう。
関連記事
機械学習について最近知った情報
OpenCVで顔のモーフィングを実装する
Faster R-CNN:ディープラーニングによる一般物体検...
FCN (Fully Convolutional Netwo...
Mitsuba 2:オープンソースの物理ベースレンダラ
疑似3D写真が撮れるiPhoneアプリ『Seene』がアップ...
GAN (Generative Adversarial Ne...
顔画像処理技術の過去の研究
OpenCV 3.1とopencv_contribモジュール...
SSII 2014 デモンストレーションセッションのダイジェ...
SSD (Single Shot Multibox Dete...
BlenderProc:Blenderで機械学習用の画像デー...
Cartographer:オープンソースのSLAMライブラリ
SVM (Support Vector Machine)
AR (Augmented Reality)とDR (Dim...
スクラッチで既存のキャラクターを立体化したい
Google Colaboratoryで遊ぶ準備
PCA (主成分分析)
ニューラルネットワークと深層学習
OpenCV 3.1のsfmモジュールのビルド再び
書籍『ゼロから作るDeep Learning』で自分なりに学...
ArUco:OpenCVベースのコンパクトなARライブラリ
iOSで使えるJetpac社の物体認識SDK『DeepBel...
PeopleSansPeople:機械学習用の人物データをU...
畳み込みニューラルネットワーク (CNN: Convolut...
Theia:オープンソースのStructure from M...
OpenCV3.3.0でsfmモジュールのビルドに成功!
openMVGをWindows10 Visual Studi...
3D Gaussian Splatting:リアルタイム描画...
MLDemos:機械学習について理解するための可視化ツール
3Dスキャンに基づくプロシージャルフェイシャルアニメーション
iPhoneで3D写真が撮れるアプリ『seene』
OpenCVのfindEssentialMat関数を使ったサ...
Rerun:マルチモーダルデータの可視化アプリとSDK
NumSharp:C#で使えるNumPyライクな数値計算ライ...
Photogrammetry (写真測量法)
LLM Visualization:大規模言語モデルの可視化
OpenCVでカメラ画像から自己位置認識 (Visual O...
顔検出・認識のAPI・ライブラリ・ソフトウェアのリスト
BlenderでPhotogrammetryできるアドオン
Kornia:微分可能なコンピュータービジョンライブラリ
PyTorch3D:3Dコンピュータービジョンライブラリ

コメント