
今まで一般物体認識や一般物体検出にはあんまり興味が無かったんだけど、YOLOとかSSD、Mask R-CNNといった手法をベースにして特定のタスクを解く研究も結構登場しているので、その体系を知りたくなってきた。
幸い、ディープラーニングによる一般物体検出の研究はもう5, 6年経っていてネット上に教材が豊富なので、色々と漁りながら勉強してみる。スクラップブックみたいな感じで色んな人による解説資料を引用して並べるとディティールを補完しやすい。
一般物体検出(Generic Object Detection)
そもそも一般物体検出(Generic Object Detection)とは、画像に何が写っているかを識別する一般物体認識(Generic Object Recognition)に対して、さらに物体が画像のどの位置に写っているかも特定すること。
人の顔など、画像の中から特定の物体を検出して位置を特定する手法は特定物体認識と呼ばれる。
2013年に登場したR-CNN以降、一般物体検出の研究はディープラーニングの時代に突入した。
ディープラーニングによる一般物体検出手法の発展の時系列をまとめた図がGitHubで公開されている↓

赤字で表記されているのが後のランドマークとなる手法で、図の作者いわく「必読」だそうです。
R-CNNからMask R-CNNまでの各手法の継承関係を概観するのにこちらのスライドの6ページ目の系譜図がとても分かりやすかった↓
系譜図のように、まず大きく分けて2つのパラダイムがある。
- NOT End-to-Endな手法:領域候補の検出と領域の分類を別々の手法で処理する
- End-to-Endな手法:領域候補の検出と領域の分類を1つのニューラルネットワークで処理する
Faster R-CNNやYOLOからEnd-to-Endが主流となった。
では、ディープラーニングによる一般物体検出の始祖となるR-CNNから勉強しよう。
R-CNN (Regions with CNN features)
R-CNNはCVPR 2014で発表された論文 Rich feature hierarchies for accurate object detection and semantic segmentationで提案された一般物体検出手法。
論文で使われた実装はGitHubで公開されているけど、MATLABコードが含まれてるのよね↓
https://github.com/rbgirshick/rcnn
この手法の1番のポイントは、CNN(畳み込みニューラルネットワーク)を特徴抽出器として利用した点。
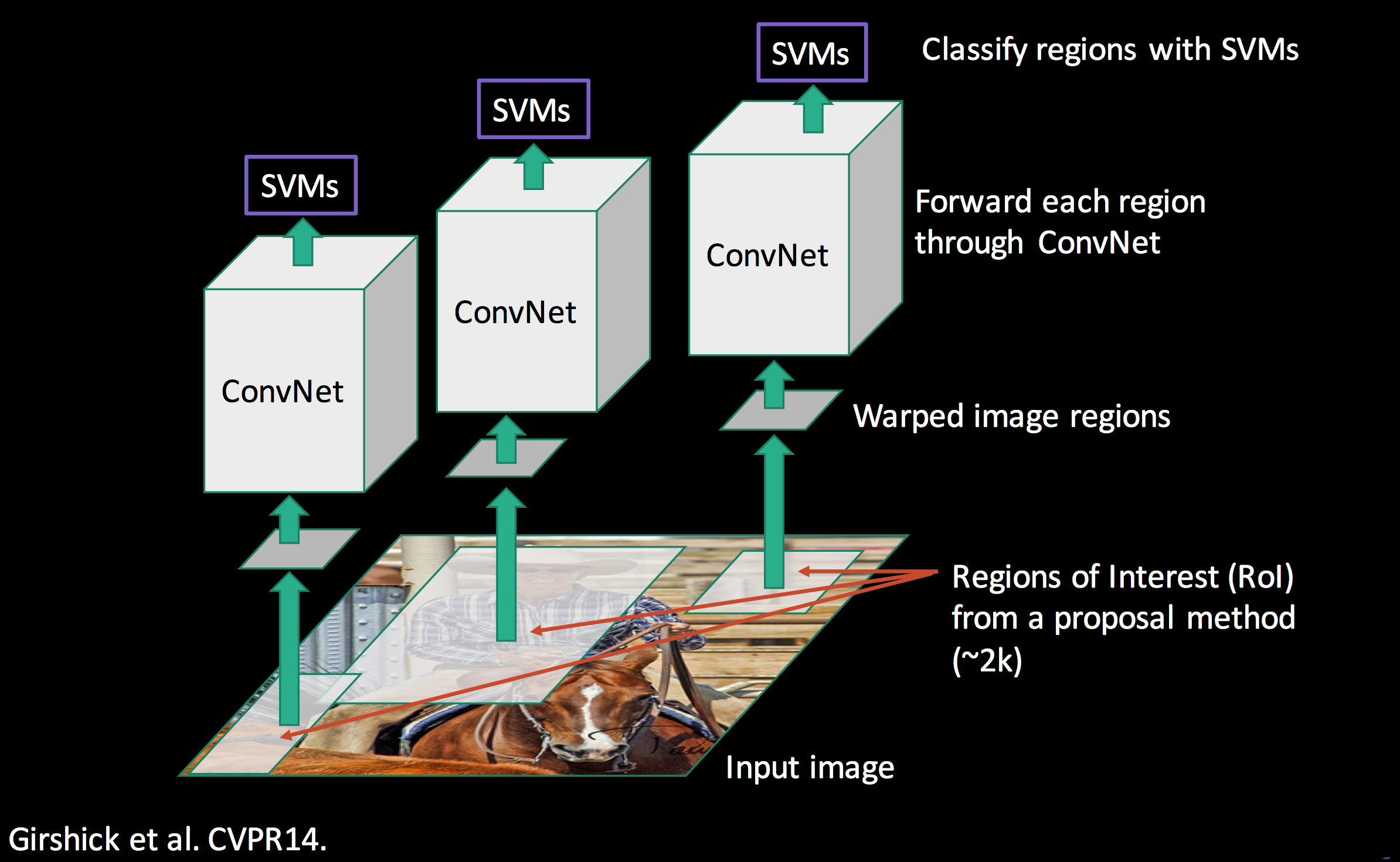
R-CNNの処理の全体像はこちらのスライドの30ページがまとまっていて分かりやすい↓
この図にそって処理の流れを4ステップで段階的に説明すると…
1. Input image (画像を入力する)
一般物体検出処理にかける画像を入力する。
2. Extract region proposals (物体領域の候補を抽出する)
入力画像からSelective Searchで物体が写っている領域の候補(region proposals)矩形を2000個ほど抽出し、CNNの入力画像とする。Selective Searchであらかじめ候補領域を絞り込むことで、画像全体に隈なく認識Windowを走らせるよりも高速化を図っている。
CNNの入力サイズ(ピクセル数)は固定なため、Selective Searchで抽出した領域はCNNの入力サイズに合わせて変形・リサイズする。
Selective Search
ここで使うSelective Searchは、ICCV 2011で発表された論文 Segmentation as Selective Search for Object Recognitionで提案されたもので、セグメンテーション手法をベースにしたObjectness (物体らしいもの)検出手法。
Selective Searchの処理の流れはこちらのスライドの10, 11ページ目が分かりやすい↓
スライドのように、Selective Searchはピクセルレベルで類似する領域を階層的に結合して1つの物体候補領域を抽出し、そのBounding Boxを出力する。
結合前の初期セグメンテーションには、2004年に提案されたGraph Based Image Segmentationが使われる。Dlibで言うとsegment_image関数↓
http://dlib.net/imaging.html#segment_image
DlibにはSelective Searchもfind_candidate_object_locations関数として実装されている↓
http://dlib.net/imaging.html#find_candidate_object_locations
そしてfind_candidate_object_locations関数をpythonで利用するサンプルコードも公開されている↓
http://dlib.net/find_candidate_object_locations.py.html
3. Compute CNN features (CNNで特徴量を抽出する)
特徴抽出器として使うCNNには、ImageNetデータセットで学習した一般物体認識のネットワークを流用する。(当時の代表的なCNNアーキテクチャであるAlexNetやVGG)
fine-tuning
しかし、一般物体認識用に学習したCNNをそのまま使うと、学習したクラスだけしか認識できず、学習していないクラスの画像は1番似ているクラスに分類(Classification)してしまう。これを防ぐために、ImageNetで学習したネットワークパラメータを初期値として別のデータセット(Pascal VOC)で学習を行う。
※これをfine-tuningまたは転移学習(transfer learning)と呼ぶ。
そしてこのCNNで分類(Classification)まで行うのではなく、出力層の1つ前の層である全結合層の値を特徴量(ベクトル)とする。
4. Classify regions (領域に何が写っているか分類する)
CNNで抽出した特徴量を使い、SVM(Support Vector Machine)によって領域を分類する。
SVMではyes, noの2クラス分類を行うだけなので、分類したい物体の種類の数だけSVMを学習する必要がある。
SVMの結果からその領域がどの物体なのか、あるいは背景なのかを判定する。
その後、回帰(Regression)によって物体のBounding Boxを推定する。
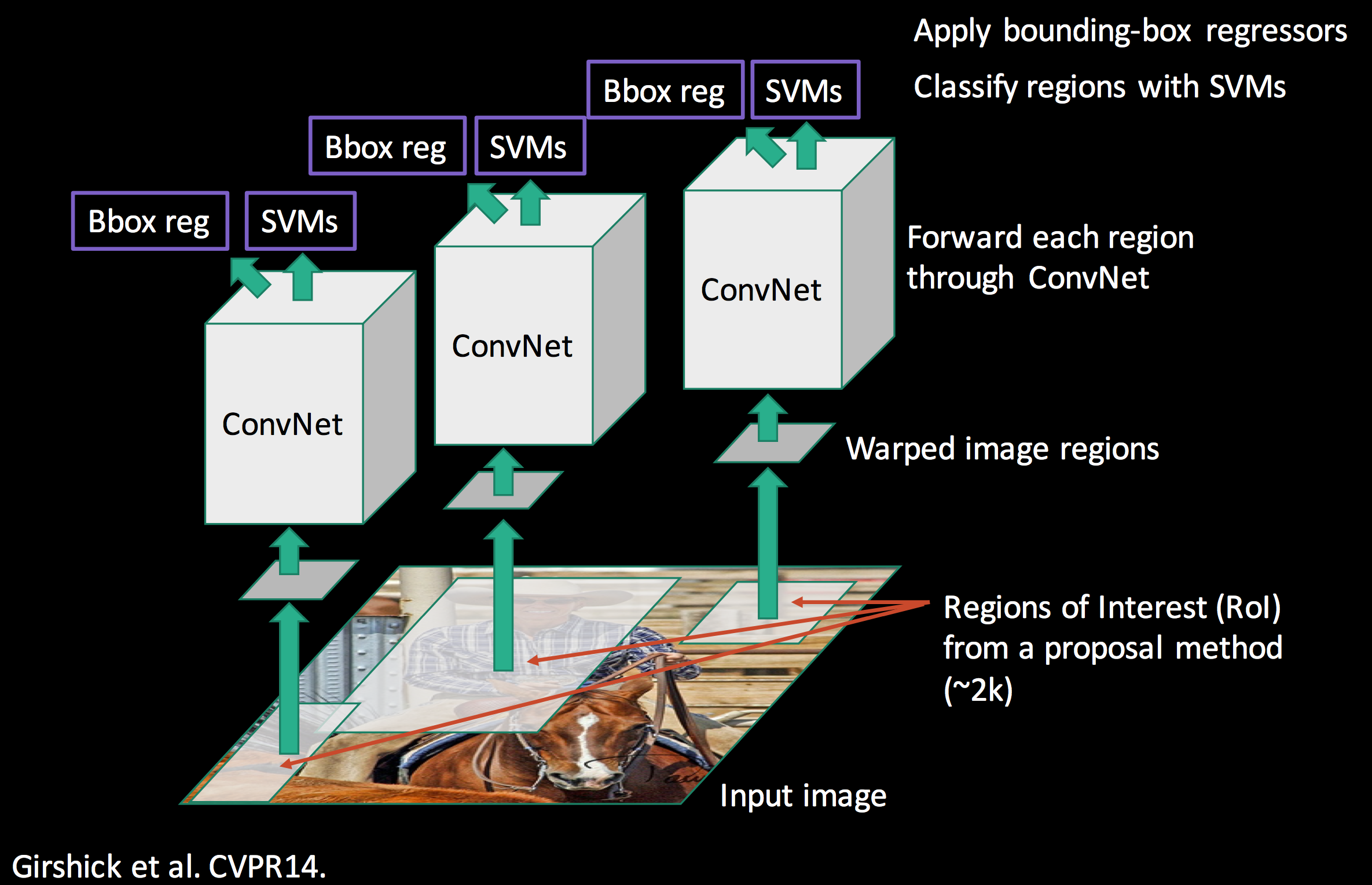
R-CNNの欠点
要するにR-CNNは、Selective Searchで大量に検出した物体領域候補(region proposals)を無理やりリサイズしてCNNで特徴抽出し、1つ1つをSVMで分類(Classification)するというもの。
R-CNNはディープラーニング以前の一般物体検出手法に比べて認識精度を大きく向上させたが、画像1枚あたりの推定時間がGPUを使っても10秒以上かかってしまう。
また、CNNのfine-tuning、分類を行う複数のSVM、Bounding Boxの回帰と、プロセスごとに別々に学習する必要がある。
参考図書
こちらの書籍の改訂第2版がディープラーニングの最近の動向まで簡潔にまとまっていて分かりやすかった↓

第2版ではR-CNNから始まる一般物体検出の歴史が解説されている他、前の版にあったボルツマンマシンの件がバッサリとカットされていて読みやすい(笑)
ところで、論文の発表時期を学会の開催時期とするかarXivでの公開時期とするかで結構時差が生まれるな。
R-CNNのarXiv公開は2013年11月だけど、CVPR2014の開催は2014年6月。
次はFast R-CNNについてまとめようと思う↓
(必読推奨のOverFeatをスルーしている)
関連記事
2D→3D復元技術で使われる用語まとめ
Unityの薄い本
ZBrushで作った3Dモデルを立体視で確認できるVRアプリ...
adskShaderSDK
KelpNet:C#で使える可読性重視のディープラーニングラ...
ROSでガンダムを動かす
cvui:OpenCVのための軽量GUIライブラリ
オープンソースのロボットアプリケーションフレームワーク『RO...
書籍『ゼロから作るDeep Learning』で自分なりに学...
UnityでLight Shaftを表現する
Iterator
プログラムによる景観の自動生成
TorchStudio:PyTorchのための統合開発環境と...
CGのためのディープラーニング
Unityで強化学習できる『Unity ML-Agents』
ニューラルネットワークと深層学習
uvでWindows11のPython環境を管理する
ブログをGoogle App EngineからAmazon ...
注文してた本が届いた
定数
書籍『絵はすぐに上手くならない』読了
OpenCVで顔のモーフィングを実装する
MythTV:Linuxでテレビの視聴・録画ができるオープン...
UnityでPoint Cloudを表示する方法
Accord.NET Framework:C#で使える機械学...
OpenMesh:オープンソースの3Dメッシュデータライブラ...
コンピュータビジョンの技術マップ
書籍『AI vs. 教科書が読めない子どもたち』読了
OpenCV 3.3.0 contribのsfmモジュールの...
OpenCVでカメラ画像から自己位置認識 (Visual O...
VGGT:マルチビュー・フィードフォワード型3Dビジョン基盤...
全脳アーキテクチャ勉強会
Super Resolution:OpenCVの超解像処理モ...
OpenCVの超解像(SuperResolution)モジュ...
Unityで画面タッチ・ジェスチャ入力を扱う無料Asset『...
書籍『天才を殺す凡人』読了
動画で学ぶお絵かき講座『sensei』
OANDAのfxTrade API
iOSデバイスのためのフィジカル・コンピューティングツールキ...
Unity MonoBehaviourクラスのオーバーライド...
SegNet:ディープラーニングによるSemantic Se...
UnrealCV:コンピュータビジョン研究のためのUnrea...


コメント