7月にDALL-E2やMidjourneyが公開されて以降、画像生成AIの話題が尽きない。
ほんの2,3ヶ月の間に、文章から画像を生成するtext to imageの新しい研究やサービス・ツールへの移植が毎日のように次々と公開されている。
https://note.com/yamkaz/m/mad0bd7dabc99
オイラも8月にMidjourneyを無料枠で試してみた↓
話題のmidjourneyに「H・R・ギーガーが描いたウルトラマン」を頼んだ結果#midjourney pic.twitter.com/dV9ANULIdO
— NegativeMind (@NegativeMind) August 5, 2022
Stability.Aiがtext to image手法の1つであるStable Diffusionをオープンソースで公開したことで、text to imageが色んなサービスやツールに組み込まれて一気に手軽に試せるようになった。
https://huggingface.co/CompVis/stable-diffusion-v1-4
https://github.com/CompVis/stable-diffusion
text to imageを利用できる有料サービスに課金しても良いけど、今はかなり円安なのでできれば自分のPCローカルでtext to image動かして好き放題遊びたい。そこそこ良いスペックのPCはあるので。


少し調べてみると、今のところ最も手軽にtext to imageをローカルで試せるのはStable DiffusionをGUIで包んだこちらのアプリケーション↓
Stable Diffusion GRisk GUI
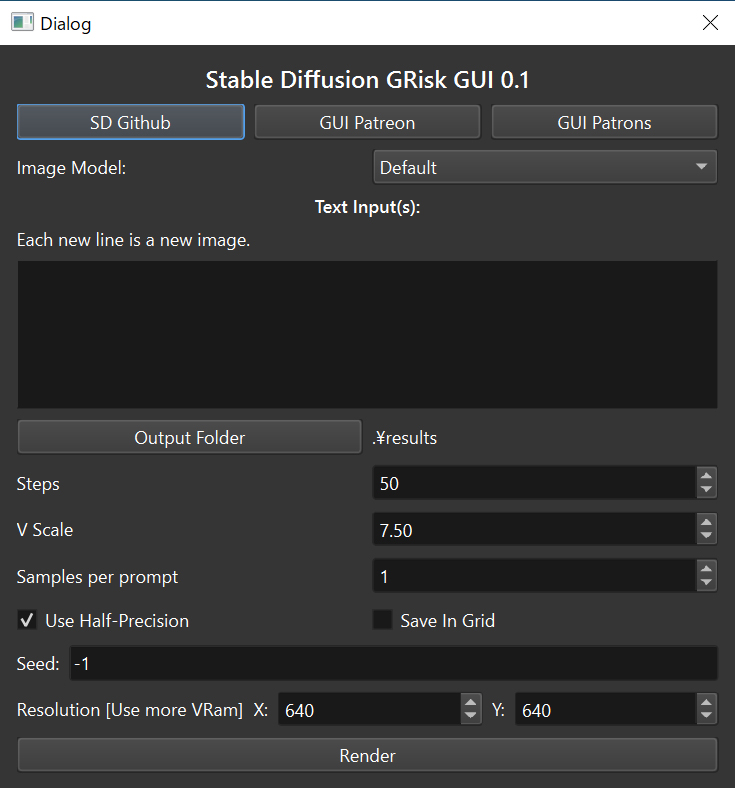
Stable Diffusionのモデルを実行するためのインターフェイスです。つまり、テキストのpromptを入力するとそれに対応した画像が返ってきます。
これは超アルファ版であるため、多くのバグがある可能性があります。Stable Diffusion GRisk GUI.exeを実行するだけで使用できます。
生成する画像の解像度設定は64の倍数(64, 128, 192, 256など)である必要があり、512×512解像度が最も良い生成結果を得られます。
重要事項:
- 一部のGTX 1660カードでは、Use Half-Precisionで実行すると問題が発生すると判明しています。(現時点でGUIではこのオプションにしか対応していません)
- Samples per promptはまだ機能しておらず、promptごとに常に1つの画像が生成されます。同じpromptを複数行繰り返せばSamples per promptと同等の効果を得られます。
- 512X512で良好な結果を得られますが、他の解像度は品質に影響を与える可能性があります。
- Step数を多くするとより品質が向上します。Step数を増やしてもメモリ消費量は増えず、処理時間が長くなります。
- 150 Step以下から始めると良いでしょう。
- .exeの起動時に以下のエラーが表示されてもアプリは引き続き動作します。
torchvision\io\image.py:13: UserWarning: Failed to load image Python extension:torch\_jit_internal.py:751: UserWarning: Unable to retrieve source for @torch.jit._overload function:
. warnings.warn(f"Unable to retrieve source for @torch.jit._overload function: {func}.")
torch\_jit_internal.py:751: UserWarning: Unable to retrieve source for @torch.jit._overload function:
. warnings.warn(f"Unable to retrieve source for @torch.jit._overload function: {func}.")
オイラの環境だと640×640解像度まではエラー無く動作したけど、推奨解像度の512×512の方が生成品質は良くなるらしいです。
https://note.com/abubu_nounanka/n/n496a98677201
追記:もっとリッチなGUIアプリがあった↓
NMKD Stable Diffusion GUI
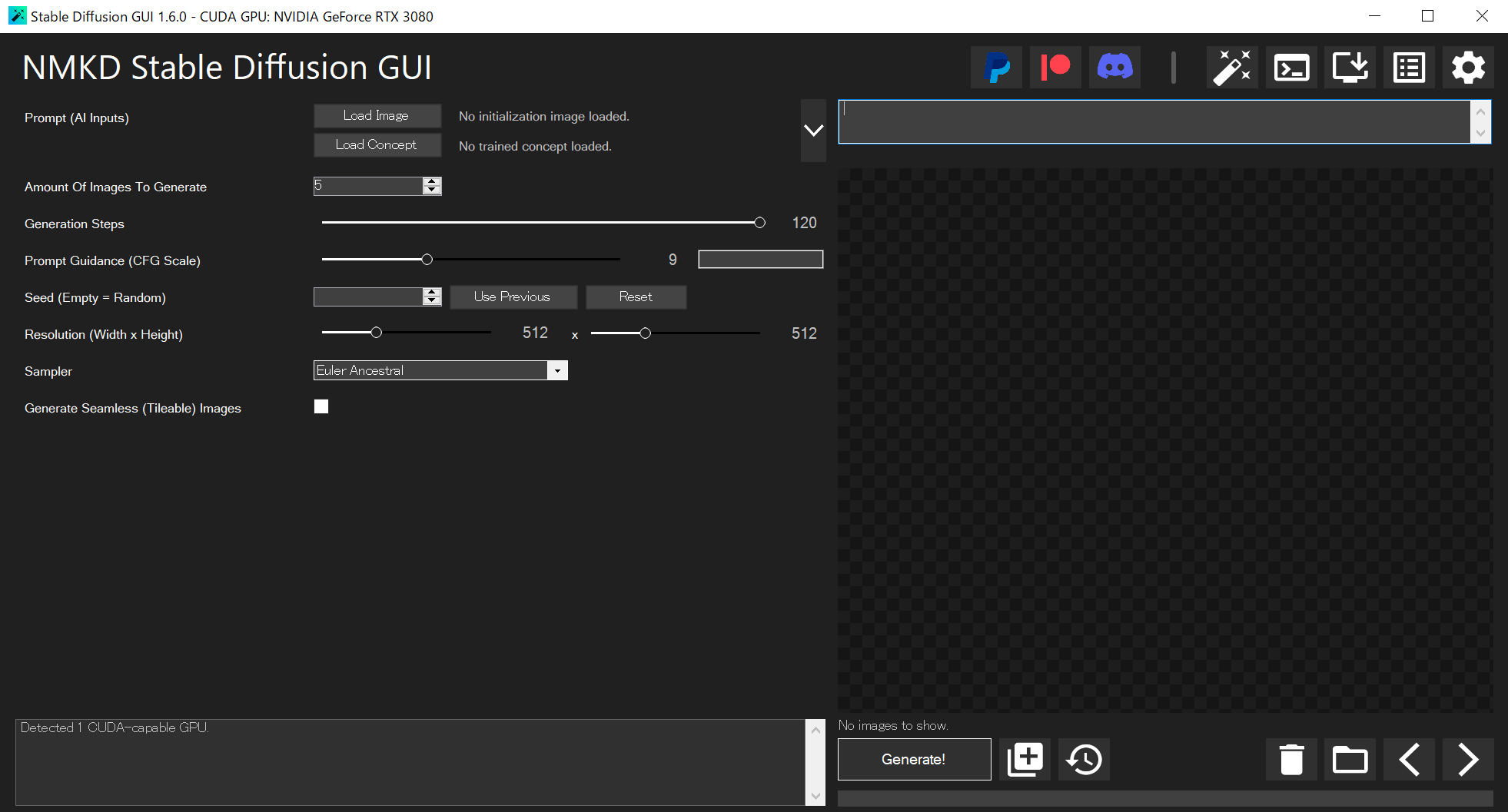
https://github.com/n00mkrad/text2image-gui
https://pajoca.com/stable-diffusion-gui-nmkd/
https://pajoca.com/stable-diffusion-gui-img2img/
promptとパラメータを色々工夫して好みの画像生成を模索してみた結果↓














ハイスペックなPCを持っていれば、パソコンを起点とした遊びは充実するね。
もはやGANの時代ではないらしい。Stable Diffusionの仕組みについてちゃんと勉強したいなぁ。
https://ja.stateofaiguides.com/20221012-stable-diffusion/
追記:Stable Diffusionをスマホローカルで動作させた例もチラホラ


The #stableDifusion running on-device on iOS beta is out! Running iOS 16 only right now. These took me about 4:30-5 min on my iPhone 14 Pro https://t.co/41OQSJQHC4
Also, signup here if you haven’t already to learn about the actual launch https://t.co/7tpiedKeJz pic.twitter.com/Q0G82BC4qb
— Matt Waller (@wattmaller1) October 15, 2022
I got Stable Diffusion running on my phone this weekend. It's slow, but usable! Code is here: https://t.co/mwq0YQiNcU pic.twitter.com/Ft29LWOk5p
— Ollin Boer Bohan (@madebyollin) October 9, 2022
関連記事
書籍『開田裕治 怪獣イラストテクニック』
ZBrushでアヴァン・ガメラを作ってみる 口内の微調整・身...
DUSt3R:3Dコンピュータービジョンの基盤モデル
ゴジラの全てがわかる博覧会『G博』
AnacondaとTensorFlowをインストールしてVi...
Maya LTのQuick Rigを試す
ZBrushCore
参考書
SegNet:ディープラーニングによるSemantic Se...
ZBrushのUV MasterでUV展開
PureRef:リファレンス画像専用ビューア
RefineNet (Multi-Path Refineme...
ZBrushでアヴァン・ガメラを作ってみる 口のバランス調整
Human Generator:Blenderの人体生成アド...
トランスフォーマー :リベンジのメイキング (デジタルドメイ...
書籍『3次元コンピュータビジョン計算ハンドブック』を購入
trimesh:PythonでポリゴンMeshを扱うライブラ...
ポリ男からMetaHumanを作る
オープンソースのIT資産・ライセンス管理システム『Snipe...
書籍『イラストで学ぶ ディープラーニング』
Alice Vision:オープンソースのPhotogram...
動き出す浮世絵展 TOKYO
ニンテンドー3DSのGPU PICA200
ZBrushで基本となるブラシ
uvでWindows11のPython環境を管理する
ボールペンに変形するトランスフォーマー『TRANSFORME...
ZBrushでアヴァン・ガメラを作ってみる 下アゴと頭部を作...
ZBrushでアヴァン・ガメラを作ってみる 全体のバランス調...
仮面ライダーバトライド・ウォー
ZBrushのハードサーフェイス用ブラシ
オープンソースの物理ベースレンダラ『Mitsuba』をMay...
Adobe MAX 2015
FCN (Fully Convolutional Netwo...
『スター・ウォーズ 最後のジェダイ』のVFXブレイクダウン ...
犬が電柱におしっこするように、僕はセカイカメラでエアタグを貼...
Iridescence:プロトタイピング向け軽量3D可視化ラ...
CEDEC 2日目
ZBrush 2021.6のMesh from Mask機能...
3DCGのモデルを立体化するサービス
DCGAN (Deep Convolutional GAN)...
偏愛マップ
OpenMesh:オープンソースの3Dメッシュデータライブラ...


コメント