FCN (Fully Convolutional Network)に引き続きSemantic Segmentation手法のお勉強。

次はSegNetについて。
SegNet
SegNetはPAMI 2017のSegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentationで提案されているSemantic Segmentation手法。
立派なプロジェクトページもあり、ソースコードも公開されている。
もともとはCVPR 2015にSegNet: A Deep Convolutional Encoder-Decoder Architecture for Robust Semantic Pixel-Wise Labellingとして投稿されていた研究らしい。(その版はarXivにある)
ここ最近は論文の公開形態が複雑ですね。学会に採択されていなくても、arXivに投稿されていれば他の論文で引用されるようになった。
SegNetもFCNと同様に全結合層を持たず、入力画像に対してpixel単位でどの物体クラスに属するかのラベルを出力する。
FCNとの大きな違いはメモリ効率。
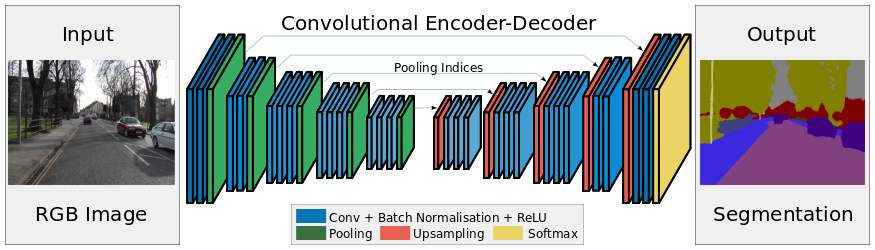
Encoder-Decoder構造
SegNetは、入力画像から特徴マップを抽出するEncoderと、抽出した特徴マップと元の画像のpixel位置の対応関係をマッピングするDecoderで構成されている。対称構造のようなネットワーク構成↓

FCNでは、途中の各pooling層の特徴マップをアップサンプリング・連結して利用していたが、そのために各特徴マップを一時的に保持する必要があり、メモリ効率が悪かった。
SegNetでは、Encoderでpoolingした位置をmax-pooling indexとして記憶しておき、Decoderで特徴マップをそのindex位置にアップサンプリングすることでメモリ効率を高めている。
Encoder
画像から特徴マップを抽出するEncoderには、一般物体認識用に学習したVGG-16の13層の畳み込み層を流用しfine-tuningする。(お決まりのテクニックですね)
そして、Decoderでのアップサンプリング時に利用するために、pooling層でのmax-poolingでどのpixel位置(max-pooling index)の値を取ってきたかを記録しておく。
Batch Normalization (バッチ正規化)
ネットワーク図で明示的に記載されているので、ここでBatch Normalization (バッチ正規化)について解説。
Batch Normalizationは2015年に発表されたBatch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shiftで提案された勾配消失・勾配爆発を防ぐための手法。
通常、ニューラルネットワークの学習は、学習データセットを少量のサブセット(ミニバッチ)に分け、そのサブセットごとにネットワークのパラメータ更新を行うミニバッチ学習で行う。
しかし、ネットワークの構造が深くなると、ある層での特徴の分布(特徴マップ)がミニバッチごとに大きく変化する内部共変量シフトが発生し、学習が効率的に進まなくなる。
Batch Normalizationはこの内部共変量シフトが起こらないように、各層においてミニバッチごとに特徴分布が偏らないように調整する。
Batch Normalization以前は、学習を効率的に進めるために以下のように様々な対処方法が提案されていた↓
- ネットワークの重みの初期値を事前学習する
- 学習係数(learning rate)を下げる
- ネットワークの自由度を制約する(Dropoutなど)
Batch Normalizationの登場により、これらの方法を使わなくても学習プロセスを安定化させて高速に学習できるようになった。
Batch Normalizationは全結合や畳み込みの後、活性化関数(ReLUなど)の前に行われる。ネットワーク構造の全体像を表す図では活性化関数と同様に記載を省略されることが多いです。
Decoder
Encoderで抽出された特徴マップはpooling層を経てサイズが小さくなっているため、Decoderでは特徴マップをアップサンプリングで徐々に大きくして元の画像サイズに戻していく。これによって画像上の物体のpixel位置とsegmentationのpixel位置を対応させる。
DecoderはEncoderの順序を反転してpooling層をアップサンプリング層に置き換えたような構造となっている。
SegNetのDecoderで行われる逆畳み込みとFCNで行われる逆畳み込みとの大きな違いは、Encoderのpooling層で記録したmax-pooling indexを使用して特徴マップをアップサンプリングしてから畳み込みを行う点。
以下の図のa, b, c, dが特徴マップのpixel値だとすると、Decoderのアップサンプリング層では特徴マップの各画素をEncoderのpooling層で記録しておいたindex位置へ戻すだけで、それ以外のpixelは空(0)で埋める。

このアップサンプリングは逆pooling(un-pooling)とも呼ばれる。
そして、このアップサンプリングした特徴マップに対して畳み込みを行う。
サンプルコード
SegNetのシンプルなPyTorch実装ならこの辺りかな↓
https://github.com/delta-onera/segnet_pytorch
SegNetに限らず、Semantic Segmentation系のPyTorch実装をひとまとめにしたリポジトリがGitHubにあった↓
https://github.com/meetshah1995/pytorch-semseg
次はU-Netについてまとめよう。

関連記事
Leap MotionでMaya上のオブジェクトを操作できる...
MLDemos:機械学習について理解するための可視化ツール
OpenCVで動画の手ぶれ補正
BlenderでPhotogrammetryできるアドオン
openMVG:複数視点画像から3次元形状を復元するライブラ...
ポイントクラウドコンソーシアム
オープンソースのロボットアプリケーションフレームワーク『RO...
hloc:SuperGlueで精度を向上させたSfM・Vis...
iPhoneで3D写真が撮れるアプリ『seene』
Paul Debevec
TensorFlowでCGを微分できる『TensorFlow...
iOSで使えるJetpac社の物体認識SDK『DeepBel...
FacebookがDeep learningツールの一部をオ...
Point Cloud Libraryに動画フォーマットが追...
C#で使える遺伝的アルゴリズムライブラリ『GeneticSh...
OpenCVで顔のランドマークを検出する『Facemark ...
KelpNet:C#で使える可読性重視のディープラーニングラ...
Rerun:マルチモーダルデータの可視化アプリとSDK
Point Cloud Consortiumのセミナー「3D...
コンピュータビジョンの技術マップ
オープンソースの顔認識フレームワーク『OpenBR』
CNN Explainer:畳み込みニューラルネットワーク可...
TensorSpace.js:ニューラルネットワークの構造を...
Faster R-CNN:ディープラーニングによる一般物体検...
機械学習のオープンソースソフトウェアフォーラム『mloss(...
機械学習での「回帰」とは?
写真から3Dメッシュの生成・編集ができる無料ツール『Auto...
Super Resolution:OpenCVの超解像処理モ...
OpenCVの三角測量関数『cv::triangulatep...
R-CNN (Regions with CNN featur...
Connected Papers:関連研究をグラフで視覚的に...
Mitsuba 2:オープンソースの物理ベースレンダラ
Pylearn2:ディープラーニングに対応したPythonの...
OpenGVの用語
SSII2014 チュートリアル講演会の資料
ドットインストールのWordPress入門レッスン
PSPNet (Pyramid Scene Parsing ...
書籍『イラストで学ぶ ディープラーニング』
OpenCVの顔検出過程を可視化した動画
PeopleSansPeople:機械学習用の人物データをU...
OpenCVのバージョン3が正式リリースされたぞ
機械学習に役立つPythonライブラリ一覧


コメント