R-CNN、Fast R-CNNに引き続きFaster R-CNNのアルゴリズムのお勉強。名前が似ていてややこしいですな。
しつこくこちらの系譜図を引用する↓
Faster R-CNNからEnd-to-Endのアプローチが始まります。
Faster R-CNN
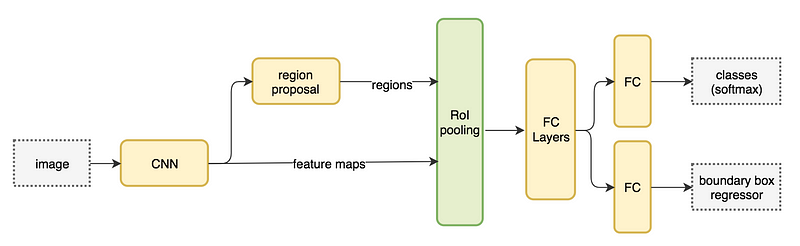
NIPS 2015で発表された論文 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networksで提案されたFaster R-CNNでは、従来Selective Searchで行っていた候補領域(region proposals)の検出処理をRPN (Region Proposal Network)というニューラルネットワークに置き換えてさらなる効率化を実現した。
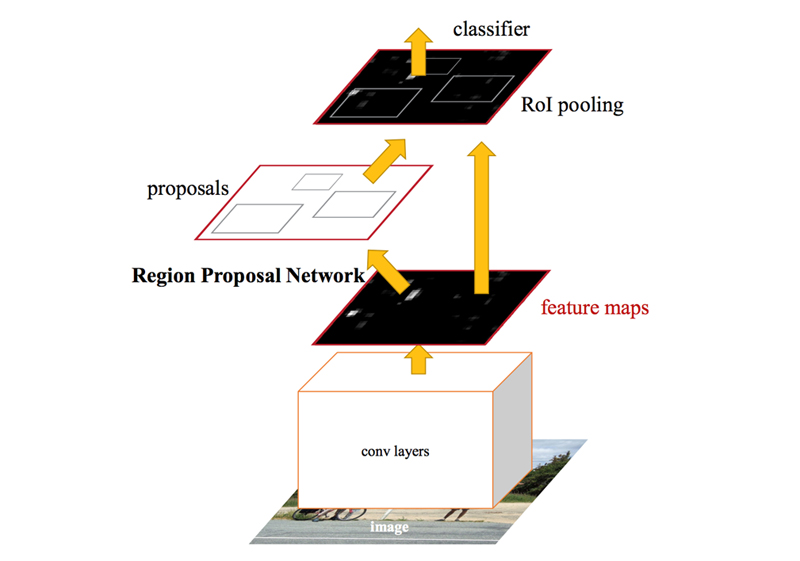
Faster R-CNNのネットワークアーキテクチャ図でregion proposalと表記されているのがRPN↓
これで物体検出の全ての処理が1つのニューラルネットワークにつながった。End-to-Endアプローチということですね。
ZFNet
この論文で例示されている特徴抽出CNNは、Visualizing and understanding convolutional neural networksで提案されたZF(Zeiler and Fergus)Net。(AlexNetの改良版)
ZFNetの5つの畳み込み層を経て出力される特徴マップは256チャンネル(256-d)となる。
(特徴抽出に使うCNNはVGGでも良いらしく、その場合の特徴マップは512チャンネルとなる)
通常、一般物体検出の対象となる画像のサイズは1000×600程度で、CNNで特徴マップ化すると16分の1の程度のサイズ(60×40)に縮小される。
RPN (Region Proposal Network)
物体領域候補の検出を行うRPN (Region Proposal Network)は、画像全体からCNNで抽出した特徴マップに対して、候補領域のBounding Boxと、その領域の物体らしさ(Objectness)を表すスコアを出力する。
RPNは小さなニューラルネットワークで、特徴マップ上をn×nサイズのスライディングwindowで走査し、各々のn×nサイズの注目領域をネットワークの入力とする。
そして、各スライディングwindow位置に対してk個の候補領域を推定する。
k個の候補領域を推定するために、RPNは以下2つの全結合層へ分岐する。
- cls layer:物体かどうか(objectness)を分類する
- reg layer:Bounding Boxの回帰を行う
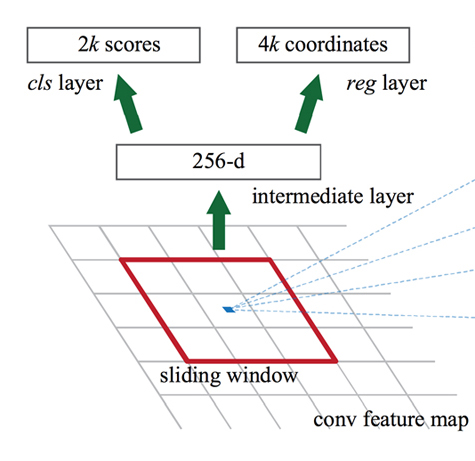
cls layerには、k個の各候補領域がオブジェクトか、背景かの確率を推定した2k個のスコアが出力される。
reg layerには、k個のBounding Boxの座標・サイズを表す4k個の出力がある。(x座標、y座標、幅、高さ)
この論文ではn=3とし、実際にはスライディングwindowではなく3×3サイズの畳み込み層と、それに続く2つに分岐した1×1サイズの畳み込み層(Fully Convolutional Networks)として実装している。
(これは3×3のスライディングwindowと等価)
Anchor
スライディングwindowに対して、写っている物体の形状が必ずしも正方形に収まらないことを考慮して、Anchorと呼ばれるk個の検出矩形パターンを用意する。
各スライディングwindowで検出する候補の数k個とはつまり、用意するAnchorの種類の数というわけ。
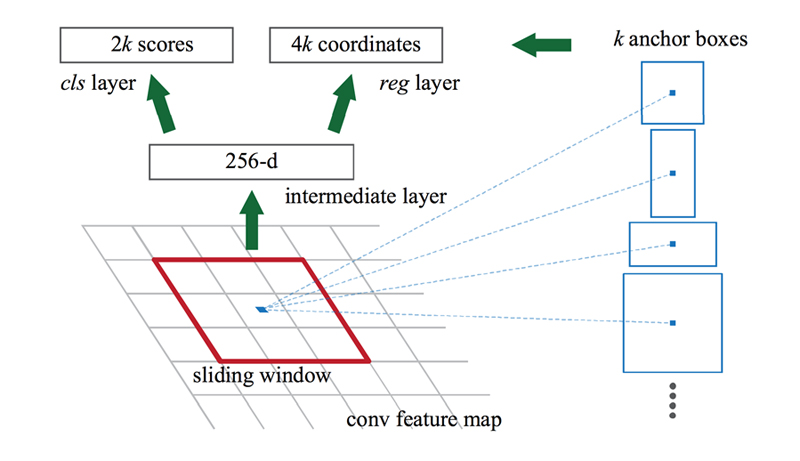
Anchorはスライディングwindowの中心を基準に設定される。
論文では、アスペクト比の違う3種類の矩形をさらにスケール違いで3種類用意し、k=9としている。
特徴マップのサイズをW×H(2,400以下)とすると、RPNは合計W×H×k個の領域について物体候補かどうかを判定することになる。
RPNでAnchorごとの判別を行い、物体である可能性が高いものは、Fast R-CNNと同様にRoIプーリング以降のネットワークへと進み、物体の分類が行われる。
特徴抽出の畳み込み層をRPNと共有する
ここまで、「RPNはCNNで抽出した特徴マップを入力とする」と説明してきたけど、正確には「特徴マップを抽出するCNNをRPNも共有している」と言う方が適切で、RPN自体も畳み込みニューラルネットワークの構造を持っている↓
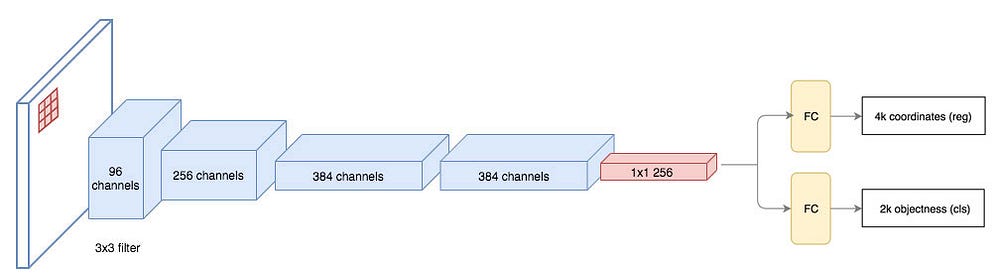
単純に畳み込み層を共有するだけでは学習するパラメータが相互に依存してしまうため、段階的に学習する方法が採られている。
- ImageNetで学習済みの畳み込み層を使ってRPNを学習する
- 学習済みRPNが出力する矩形を使って畳み込み層のパラメータを更新する
- 畳み込み層をfixしてRPNを学習し直す
Faster R-CNNの実装
Learn OpenCVにPyTorch実装のチュートリアルがある↓
https://www.learnopencv.com/faster-r-cnn-object-detection-with-pytorch/
Faster R-CNNの特許
一時期話題になりましたが、MicrosoftからFaster R-CNNの特許が出願されています。
https://qiita.com/yu4u/items/6bc9571c19181c1600a7
権利化について結局どうなったのかオイラにはちょっと分からないのですが。。。
今更だけど、R-CNN, Fast R-CNN, Faster R-CNNについて詳細に解説している記事を見つけた↓
http://www.telesens.co/2018/03/11/object-detection-and-classification-using-r-cnns/
次はYOLO (You Only Look Once)についてまとめよう↓

関連記事
adskShaderSDK
第1回 3D勉強会@関東『SLAMチュートリアル大会』
Managing Software Requirements...
法線マップを用意してCanvas上でShadingするサンプ...
Physics Forests:機械学習で流体シミュレーショ...
Twitter APIのPythonラッパー『python-...
Swark:コードからアーキテクチャ図を作成できるVSCod...
書籍『ROSプログラミング』
UnityのMonoBehaviourクラスをシングルトン化...
顔画像処理技術の過去の研究
Math Inspector:科学計算向けビジュアルプログラ...
Amazon EC2ログイン用の秘密鍵を無くした場合の対処方...
Autodesk Mementoでゴジラを3次元復元する
MPFB2:Blenderの人体モデリングアドオン
Mask R-CNN:ディープラーニングによる一般物体検出・...
C++の抽象クラス
MythTV:Linuxでテレビの視聴・録画ができるオープン...
クラスの基本
Python.NET:Pythonと.NETを連携させるパッ...
SVM (Support Vector Machine)
WordPressで数式を扱う
MeshroomでPhotogrammetry
OpenCVでPhotoshopのプラグイン開発
AfterEffectsプラグイン開発
PythonでBlenderのAdd-on開発
Runway ML:クリエイターのための機械学習ツール
konashiのサンプルコードを動かしてみた
Raspberry PiのGPIOを操作するPythonライ...
このブログのデザインに飽きてきた
OpenCV バージョン4がリリースされた!
ZScript
OpenCV
UnityでOpenCVを使うには?
Open3D:3Dデータ処理ライブラリ
画像生成AI Stable Diffusionで遊ぶ
Math.NET Numerics:Unityで使える数値計...
Theia:オープンソースのStructure from M...
プログラムによる景観の自動生成
Leap MotionでMaya上のオブジェクトを操作できる...
UnityのGameObjectの向きをScriptで制御す...
Point Cloud Libraryに動画フォーマットが追...
OpenCVの超解像(SuperResolution)モジュ...
コメント