OpenGV公式ドキュメントのHow to useを読んでるんだけど、出てくる用語が独特なのと、図はあるけど、抽象的過ぎてとても分かりづらいので苦戦している。

もう思いっきりこの記事に触発されたよね。
https://code.facebook.com/posts/697469023742261/360-video-stabilization-a-new-algorithm-for-smoother-360-video-viewing/
とりあえず、Vocabularyのところだけでも理解しておきたいので以下翻訳メモ。
How to use
このページでは、OpenGV使い方、インターフェイスやサンプルの解説も合わせて紹介します。より詳しい情報は”OpenGV: A unified and generalized approach to real-time calibrated geometric vision“に記載されています。
しかし、OpenGVの機能やドキュメントの内容を十分理解していただくためには、最初にここで使われる用語の意味を明確に定義しておく必要があります。Vocabulary(用語)
Bearing vector:
bearing vectorは、camera reference frame(カメラの投影面)から空間上の3D点へ向かうベクトルを正規化した3次元の単位ベクトルと定義します。
このベクトルは2自由度で、この自由度はカメラ投影面における方位角と仰角にあたります。bearing vectorは2自由度しか無いため、ここではほとんど2次元の情報として扱っています。通常、bearing vectorはカメラ投影面上で表されます。
Landmark:
ここでのlandmarkとは、3D空間上の点を表します。(通常、landmarkはworld reference frameと呼ばれる固定されたフレーム上で表されます)
Camera:
OpenGVはキャリブレーション済みの状態を想定しており、Landmarkの位置座標は常にカメラ投影面上のbearing vectorの形で与えられます。したがって、cameraはカメラ投影面と、原点から各landmarkへのbearing vectorのセットを表します。
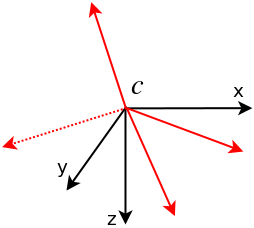
以下の図は、camera cとbearing vector(赤)を表しています。bearing vectorは全て、cameraを中心とした単位球面上になります。
Viewpoint:
コードのドキュメントでは、とても頻繁にcameraの代わりにviewpointについて語っていることに気づくかもしれません。OpenGVの利点の1つは、centralとnon-centralなケースの両方を透過的に扱えることです。
viewpointとは、cameraを一般化した概念で、viewpointには任意の数のcameraと、それぞれのcameraが持つlandmarkの座標値(例えばbearing vector)を含むことができます。
viewpointの具体例としては、撮影画像と関連する測定値(完全なキャリブレーションの元で測定)のセット、同期したカメラによる剛性のマルチカメラリグ、静止画なら一連の(複数)のスナップショットと言えます。(つまりviewpoint)
各cameraはそれぞれが独自にviewpoint frameへのtransformationを持っています。centralの場合、viewpointには単純に1つのカメラと唯一のtransformationが含まれています。
最も一般化したケースで言うと、cameraを一般化するとviewpointで記述することができます。すると、それぞれのbearing vectorも、自身のcameraと、関連するtransformationを持つことになります。したがって、このようにcameraを一般化すると、網羅的なマルチカメラシステムとして表すことができます。
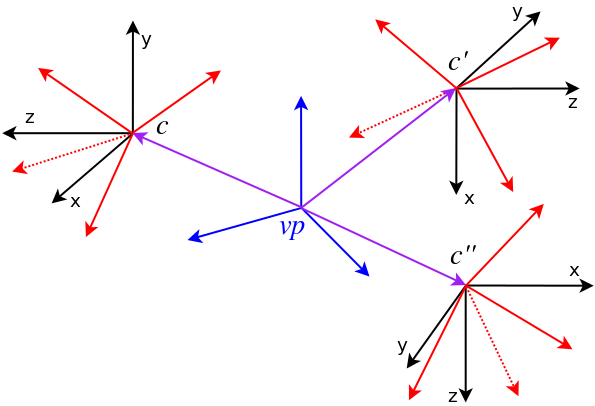
以下の画像は、viewpoint vp(青)と、それぞれ独自のbearing vectorを含む3つのcamera c, c’, c”を示しています。
Pose:
world reference frameと呼ばれる固定のreference frame上のPose、あるいは別のviewpointに対する相対的なPoseのいずれかでviewpointの位置と向きを表せます。
Absolute Pose:
absolute poseは、world reference frame上でのviewpointのposeを表します。
Relative Pose:
relative poseは、別のviewpointに対する相対的なposeとしてviewpointのposeを表します。
Correspondence:
correspondenceは、別々のviewpoint上で同一のlandmarkを指しているbearing vectorのペア(2D-2D correspondence)、bearing vectorとそれが指す3次元座標のペア(2D-3D correspondence)、または、異なるframe間で同一のlandmarkを表している座標のペア(3D-3D correspondence)の対応関係を記述します。
OpenGVでbearing vectorと呼ばれるものは、カメラの原点から投影面を通過して3次元空間上の点(landmark)へ向かう3次元方向ベクトルのことだというのは理解できた。レイトレーシングで言うところのrayみたいなものですね。
viewpointの件は未だ十分理解にできてないな。centralとnon-centralってのもまだピンと来ない。
まずreference frameって言葉の意味を教えてほしいところ。ここで出てくるframeってのは「空間」とか「座標系」みたいな意味だろうか。
関連記事
MB-Lab:Blenderの人体モデリングアドオン
iPhone・iPod touchで動作する知育ロボット『R...
TensorFlowでCGを微分できる『TensorFlow...
Raspberry Pi 2を買いました
Google Colaboratoryで遊ぶ準備
HD画質の無駄遣い
今年もSSII
VGGT:マルチビュー・フィードフォワード型3Dビジョン基盤...
iOSデバイスと接続して連携するガジェットの開発方法
OANDAのfxTrade API
NumSharp:C#で使えるNumPyライクな数値計算ライ...
CycleGAN:ドメイン関係を学習した画像変換
オーバーロードとオーバーライド
PCA (主成分分析)
Mayaのレンダリング アトリビュート
スクラッチで既存のキャラクターを立体化したい
hloc:SuperGlueで精度を向上させたSfM・Vis...
MFnMeshクラスのsplit関数
自前Shaderの件 解決しました
UnityのGameObjectの向きをScriptで制御す...
疑似3D写真が撮れるiPhoneアプリ『Seene』がアップ...
PGGAN:段階的に解像度を上げて学習を進めるGAN
openMVGをWindows10 Visual Studi...
Kornia:微分可能なコンピュータービジョンライブラリ
FacebookがDeep learningツールの一部をオ...
OpenCVで平均顔を作るチュートリアル
ニューラルネットワークで画像分類
Unity Scriptコーディング→Unreal Engi...
AfterEffectsプラグイン開発
Mitsuba 3:オープンソースの研究向けレンダラ
pythonの機械学習ライブラリ『scikit-learn』
FCN (Fully Convolutional Netwo...
ディープラーニング
法線マップを用意してCanvas上でShadingするサンプ...
Rerun:マルチモーダルデータの可視化アプリとSDK
機械学習手法『Random Forest』
フォトンの放射から格納までを可視化した動画
ドットインストールのWordPress入門レッスン
コンピュータビジョンの技術マップ
UnityでPoint Cloudを表示する方法
viser:Pythonで使える3D可視化ライブラリ
Google App Engineのデプロイ失敗


コメント